使用Fluentd + MongoDB构建实时日志收集系统
Fluentd是一个日志收集系统,它的特点在于其各部分均是可定制化的,你可以通过简单的配置,将日志收集到不同的地方。
目前开源社区已经贡献了下面一些存储插件:MongoDB, Redis, CouchDB,Amazon S3, Amazon SQS, Scribe, 0MQ, AMQP, Delayed, Growl 等等。
本文要介绍的是在Fluentd的最新版中已经内置的MongoDB支持。主要通过一个收集Apache日志的例子来说明其使用方法:
机制图解
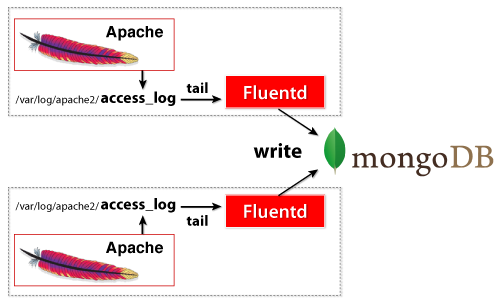
安装
为了完成相关的测试,需要安装下面一些组件:
- Fluentd with MongoDB Plugin
- MongoDB
- Apache (with the Combined Log Format)
在Fluentd的最新安装包中已经包含了MongoDB插件,你也可以用命令
gem install fluent-plugin-mongo
来进行安装
配置
如果你是使用上面的deb/rpm包安装的Fluentd,那么配置文件位置在:/etc/td-agent/td-agent.conf,否则其位置应该在:/etc/fluentd/fluentd.conf
首先我们编辑配置文件中的source来设置日志来源
<source>
type tail
format apache
path /var/log/apache2/access_log
tag mongo.apache
</source>
其中:
- type tail: tail方式是 Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。
- format apache: 指定使用 Fluentd 内置的 Apache 日志解析器。
- path /var/log/apache2/access_log: 指定日志文件位置。
- tag mongo.apache: 指定tag,tag被用来对不同的日志进行分类
下面再来编辑输出配置,配置日志收集后存储到MongoDB中
<match mongo.**>
# plugin type
type mongo # mongodb db + collection
database apache
collection access # mongodb host + port
host localhost
port 27017 # interval
flush_interval 10s
</match>
match标签后面可以跟正则表达式以匹配我们指定的tag,只有匹配成功的tag对应的日志才会运用里面的配置。配置中的其它项都比较好理解,看注释就可以了,其中flush_interval是用来控制多长时间将日志写入MongoDB一次。
测试
用ab工具对Apache进行访问,以产生相应的访问日志以供收集
$ ab -n 100 -c 10 http://localhost/
然后我们在MongoDB中就能看到收集到的日志了
$ mongo
> use apache
> db.access.find()
{ "_id" : ObjectId("4ed1ed3a340765ce73000001"), "host" : "127.0.0.1", "user" : "-", "method" : "GET", "path" : "/", "code" : "200", "size" : "44", "time" : ISODate("2011-11-27T07:56:27Z") }
{ "_id" : ObjectId("4ed1ed3a340765ce73000002"), "host" : "127.0.0.1", "user" : "-", "method" : "GET", "path" : "/", "code" : "200", "size" : "44", "time" : ISODate("2011-11-27T07:56:34Z") }
{ "_id" : ObjectId("4ed1ed3a340765ce73000003"), "host" : "127.0.0.1", "user" : "-", "method" : "GET", "path" : "/", "code" : "200", "size" : "44", "time" : ISODate("2011-11-27T07:56:34Z") }
来源: blog.treasure-data.com翻译: http://blog.nosqlfan.com/html/3521.html
使用Fluentd + MongoDB构建实时日志收集系统的更多相关文章
- 用ElasticSearch,LogStash,Kibana搭建实时日志收集系统
用ElasticSearch,LogStash,Kibana搭建实时日志收集系统 介绍 这套系统,logstash负责收集处理日志文件内容存储到elasticsearch搜索引擎数据库中.kibana ...
- ELK+kafka构建日志收集系统
ELK+kafka构建日志收集系统 原文 http://lx.wxqrcode.com/index.php/post/101.html 背景: 最近线上上了ELK,但是只用了一台Redis在 ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- Go实现海量日志收集系统(一)
项目背景 每个系统都有日志,当系统出现问题时,需要通过日志解决问题 当系统机器比较少时,登陆到服务器上查看即可满足 当系统机器规模巨大,登陆到机器上查看几乎不现实 当然即使是机器规模不大,一个系统通常 ...
- 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
作者:大数据女神-诺蓝(微信公号:dashujunvshen).本文是36大数据专稿,转载必须标明来源36大数据. 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要 ...
- GO学习-(32) Go实现日志收集系统1
Go实现日志收集系统1 项目背景 每个系统都有日志,当系统出现问题时,需要通过日志解决问题 当系统机器比较少时,登陆到服务器上查看即可满足 当系统机器规模巨大,登陆到机器上查看几乎不现实 当然即使是机 ...
- Flume -- 开源分布式日志收集系统
Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. 一.Flum ...
- 用fabric部署维护kle日志收集系统
最近搞了一个logstash kafka elasticsearch kibana 整合部署的日志收集系统.部署参考lagstash + elasticsearch + kibana 3 + kafk ...
- 基于Flume的美团日志收集系统(二)改进和优化
在<基于Flume的美团日志收集系统(一)架构和设计>中,我们详述了基于Flume的美团日志收集系统的架构设计,以及为什么做这样的设计.在本节中,我们将会讲述在实际部署和使用过程中遇到的问 ...
随机推荐
- MySQL事件的先后
今天闲聊之时 提及MySQL事件的执行,发现一些自己之前没有注意的细节 如果在执行事件过程中,如果insert的存储过程发生意外 会如何 USE iot2; CREATE TABLE aaaa (ti ...
- 数据库垂直拆分,水平拆分利器,cobar升级版mycat(转)
原文:数据库垂直拆分,水平拆分利器,cobar升级版mycat 1,关于Mycat Mycat情报 基于阿里的开源cobar ,可以用于生产系统中,目前在做如下的一些改进: 非阻塞IO的实现,相对于目 ...
- InnoDB 与 MyISAM 区别
1.myisam可以对索引进行压缩,innodb不压缩 2.索引都用b-tree, innodb使用 b+tree,NDB Cluster使用 T-Tree. 3.myisam 表级锁, inno ...
- centos7安装nodejs 和 yarn
如何从EPEL库安装Node.js 另一个有效且简单的方法来安装Node.js就是从官方库.这同样确保您可以访问到EPEL库,你可以通过运行以下命令. sudo yum install epel-re ...
- MongoDB学习笔记—常用命令
这里记录一下MongoDB常用的命令 数据库相关 创建数据库 use DATABASE_NAME 如果数据库不存在,则创建数据库,否则切换到指定数据库. 删除数据库:切换到要删除的数据库下,执行命令即 ...
- mybatis-generator和TKmybatis的结合使用
mybatis-generator可以自动生成mapper和entity文件,mybatis-generator有三种用法:命令行.eclipse插件.maven插件.这里使用的是maven插件方式, ...
- Spring学习笔记3—声明式事务
1 理解事务 事务:在软件开发领域,全有或全无的操作被称为事务.事务允许我们将几个操作组合成一个要么全部发生要么全部不发生的工作单元. 事务的特性: 原子性:事务是由一个或多个活动所组成的一个工作单元 ...
- HAProxy安装及简单配置
一.HAProxy简介 代理的作用:web缓存(加速).反向代理.内容路由(根据流量及内容类型等将请求转发至特定服务器).转码器(将后端服务器的内容压缩后传输给client端).缓存的作用:减少冗余内 ...
- 剑指offer 面试35题
面试35题: 题目:复杂链表的复制 题:输入一个复杂链表(每个节点中有节点值,以及两个指针,一个指向下一个节点,另一个特殊指针指向任意一个节点),返回结果为复制后复杂链表的head.(注意,输出结果中 ...
- List contents of directories in a tree-like format
Python programming practice. Usage: List contents of directories in a tree-like format. #!/usr/bin/p ...