SQL调优--记一次表统计信息未及时更新导致查询超级慢
某日同事丢给我一个看上去复杂的查询(实际就涉及两张表,套来套去)说只是换了日期条件,但一个查询5秒出数据,一个根本查不出来。现在整理下解决过程,及涉及的知识点。
若有不正之处,请多多谅解并欢迎批评指正,不甚感激。
请尊重作者劳动成果,转载请标明原文链接:
http://www.cnblogs.com/zzry/p/5857751.html
一.问题描述
环境:sqlserver 2008r2
现象:
查询涉及到两张表
ODS_TABLE_A 每日数据700万现在总计60多亿。 已建立索引+分区
MID_TABLE_B 每日数据20万 总计3000万。 已建立索引未分区
当etldate为 '2016-08-12' 及以前的时间时,本查询5秒出数据,
当etldate为 '2016-08-16' 及以后的时间时,本查询出不来数据。
贴上问题sql:做过数据字段处理,针对本篇主题注意点放在查询因为日期的选择不同导致查询时间变的超级慢,而不是改变sql写法比如用临时表,强制索引上。
----------《代码开始》
select
COUNT(distinct(case when COL_USERID3 is null then COL_USERID6 end)) as 'aa',
COUNT(distinct(case when COL_USERID3 is null and COL_USERID7 is not null then COL_USERID6 end)) as 'bb',
COUNT(distinct(case when COL_USERID3 is not null then COL_USERID6 end)) as 'cc',
COUNT(distinct(case when COL_USERID3 is not null and COL_USERID7 is not null then COL_USERID6 end)) as 'dd',
SUM(case when COL_USERID3 IS not null then ee end) as 'ee'
from
(
select c.COL_USERID3,c.ee,g.COL_USERID6
from
(
select b.COL_USERID2 as COL_USERID3,COUNT(b.COL_USERID2) as ee
from
(
select COL_USERID as COL_USERID1,min(EventTime) as time1
from ODS_TABLE_A
where EtlDate = '2016-08-12'
and colid LIKE 'heihei%'
group by COL_USERID
)as a
join
(
select COL_USERID as COL_USERID2,eventtime as time2
from ODS_TABLE_A
where EtlDate = '2016-08-12'
and ItemId = ''
and colid like 'haha-%'
and colid not like 'haha-skill%'
and colid not like 'haha-fine%'
)as b
on a.COL_USERID1 = b.COL_USERID2 and a.time1 > b.time2
group by b.COL_USERID2
)as c
right join
(
select DISTINCT d.COL_USERID4 as COL_USERID6
from
(
select distinct COL_USERID as COL_USERID4
from MID_TABLE_B
where etldate = '2016-08-12'
)as d
join
(
select COL_USERID AS COL_USERID5
from ODS_TABLE_A
where EtlDate = '2016-08-12'
and colid LIKE 'heihei%'
)as f
on d.COL_USERID4 = f.COL_USERID5
)as g
on c.COL_USERID3 = g.COL_USERID6
)as i
left join
(
select COL_USERID as COL_USERID7
from MID_TABLE_B
where EtlDate = '2016-08-12'
and IsTodayPay = ''
)as h
on i.COL_USERID6 = h.COL_USERID7
----------《代码结束》
二。解决过程
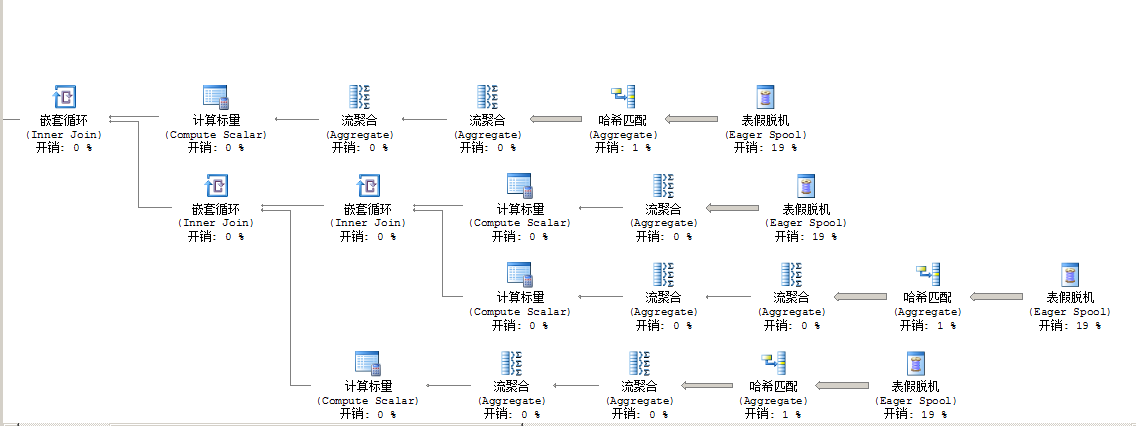
1.先看了下上述代码的执行计划如下图初看上去需要用索引的地方都用到了。应该没啥大问题。
可能你注意到系统提示的缺少索引信息,加上去一样效果,不能解决‘2016-08-16’ 查询慢的问题。

三。总结
对于大表新插入的数据没及时更新统计信息,导致出现上面文中的现象,一个日期导致查询效率天壤之别的分水岭(查12号前5秒出数据,查12号后死活不出来。)
解决办法是大表自动更新统计信息触发自动更新机制频率不够,定期更新。
SQL调优--记一次表统计信息未及时更新导致查询超级慢的更多相关文章
- 数据库性能调优之始: analyze统计信息
摘要:本文简单介绍一下什么是统计信息.统计信息记录了什么.为什么要收集统计信息.怎么收集统计信息以及什么时候收集统计信息. 1 WHY:为什么需要统计信息 1.1 query执行流程 下图描述了Gau ...
- 记一次SQL调优/优化(SQL tuning)——性能大幅提升千倍以上
好久不写东西了,一直忙于各种杂事儿,恰巧昨天有个用户研发问到我一个SQL调优的问题,说性能太差,希望我能给调优下,最近有些懒,可能和最近太忙有关系,本来打算问问现在的情况,如果差不多就不调了,那哥们儿 ...
- SQL调优常用方法
在使用DBMS时经常对系统的性能有非常高的要求:不能占用过多的系统内存和 CPU资源.要尽可能快的完成的数据库操作.要有尽可能高的系统吞吐量.如果系统开发出来不能满足要求的所有性能指标,则必须对系统进 ...
- SQL调优
# 问题的提出 在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的的编写等体会不出SQL语句各种写法的性能优劣,但是如果将应用 系统提交实际应用后,随着数据库中数据的增加,系 ...
- Oracle SQL 调优健康检查脚本
Oracle SQL 调优健康检查脚本 我们关注数据库系统的性能,进行数据库调优的主要工作就是进行SQL的优化.良好的数据架构设计.配合应用系统中间件和写一手漂亮的SQL,是未来系统上线后不出现致命性 ...
- Oracle中SQL调优(SQL TUNING)之最权威获取SQL执行计划大全
该文档为根据相关资料整理.总结而成,主要讲解Oracle数据库中,获取SQL语句执行计划的最权威.最正确的方法.步骤,此外,还详细说明了每种方法中可选项的意义及使用方法,以方便大家和自己日常工作中查阅 ...
- 《高性能SQL调优精要与案例解析》一书谈SQL调优(SQL TUNING或SQL优化)学习
<高性能SQL调优精要与案例解析>一书上市发售以来,很多热心读者就该书内容及一些具体问题提出了疑问,因读者众多外加本人日常工作的繁忙 ,在这里就SQL调优学习进行讨论并对热点问题统一作答. ...
- Oracle SQL调优之分区表
目录 一.分区表简介 二.分区表优势 三.分区表分类 3.1 范围分区 3.2 列表分区 3.3 散列分区 3.4 组合分区 四.分区相关操作 五.分区相关查询 附录:分区表索引失效的操作 一.分区表 ...
- /*+parallel(t,4)*/在SQL调优中的重要作用!
谈谈HINT /*+parallel(t,4)*/在SQL调优中的重要作用! /*+parallel(t,4)*/在大表查询等操作中能够起到良好的效果,基于并行查询要启动并行进程.分配任务与系统资源. ...
随机推荐
- iOS 解决tableView中headerView头部视图不跟随tableView滑动的方法
解决方法如下: if (scrollView.contentOffset.y >= 0 && scrollView.contentOffset.y <= pushNewsT ...
- python 之开发工具 sublimetext 3
一.前言 由于个人工作内容太过于繁杂,记忆力又不好,为日后使用的方便,故简单的记录了本篇关于sublimetext 3的初始化安装和部分插件内容的记录.目前最新的版本也是3.0以上版本了,故我这里使用 ...
- WebUploader实现采集图片的功能
项目最开始用百度团队的文件上传组件做了个物料照片采集的功能,后来做员工头像采集时竟然不知道怎么使用了. 参照官方Demo: http://fex.baidu.com/webuploader/getti ...
- ADO.NET #3-1 (GridView + DataReader + SqlCommand)完全手写Code Behind
[C#] ADO.NET #3-1 (GridView + DataReader + SqlCommand)完全手写.后置程序代码 之前有分享过一个范例 [C#] ADO.NET #3 (GridVi ...
- 如何用WebIDE打开并运行CRM Fiori应用
访问Web IDE url 在Web IDE里进行项目clone操作: https://:8080/#/admin/projects/fnf/customer/cus.crm.opportunity ...
- 【BZOJ3106】[CQOI2013] 棋盘游戏(对抗搜索)
点此看题面 大致题意: 在一张\(n*n\)的棋盘上有一枚黑棋子和一枚白棋子.白棋子先移动,然后是黑棋子.白棋子每次可以向上下左右四个方向中任一方向移动一步,黑棋子每次则可以向上下左右四个方向中任一方 ...
- 高级vim 配置
[root@chenbj ~]# pwd /root [root@chenbj ~]# cat .vimrc set nocompatible set pastetoggle=<F9> s ...
- python_7_while
count=0 while True: print('count:',count) count+=1 # count=count+1 if count==500: break#结束整个循环
- 重学css3(概览)
css3新特性概览: 1.强大的选择器 2.半透明度效果的实现 3.多栏布局 4.多背景图 5.文字阴影 6.开放字体类型 7.圆角 8.边框图片 9.盒子阴影 10.媒体查询 浏览器内核又可以分成两 ...
- mantis基本配置及邮件服务器配置
邮件服务器配置 在c:\php-5.0.3\php.ini文件中查找smtp,将localhost改为你的发件服务器,如SMTP = smtp.163.com 在php.ini文件中查找sendm ...