【赵渝强老师】搭建Hadoop环境
说明:这里我们以本地模式和伪分布模式伪列,为大家介绍如何搭建Hadoop环境。有了这个基础,大家可以自行搭建Hadoop的全分布模式。
需要使用的安装介质:
- hadoop-2.7.3.tar.gz
- jdk-8u181-linux-x64.tar.gz
- rhel-server-7.4-x86_64-dvd.iso
一、安装前的准备工作
- 安装好Redhat Linux 7.4(安装包rhel-server-7.4-x86_64-dvd.iso),并在Linux上创建tools和training两个目录

- 关闭防火墙,执行下面的命令
systemctl stop firewalld.service
systemctl disable firewalld.service
- 配置主机名,使用vi编辑器编辑文件/etc/hosts,输入以下内容
bigdata111 192.168.157.111
- 配置免密码登录,在命令行中输入下面的命令
ssh-keygen -t rsa
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata111
二、安装JDK
- 通过FTP工具将jdk-8u181-linux-x64.tar.gz和hadoop-2.7.3.tar.gz上传到Linux的/root/tools目录
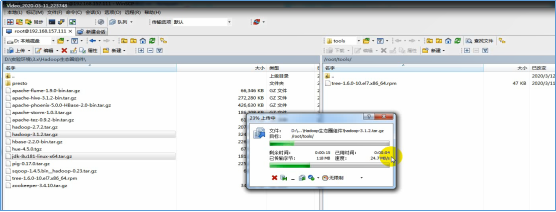
- 在xshell中,解压jdk-8u181-linux-x64.tar.gz,执行下面的命令
tar -zxvf jdk-8u181-linux-x64.tar.gz -C /root/training/
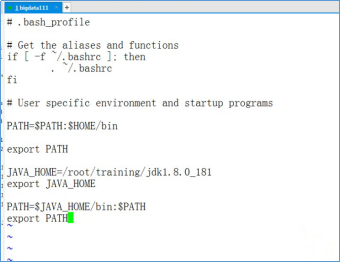
- 设置Java的环境变量,使用vi编辑器编辑~/.bash_profile文件。执行下面的命令
vi /root/.bash_profile
- 在vi编辑器中,输入以下内容
JAVA_HOME=/root/training/jdk1.8.0_181
export JAVA_HOME PATH=$JAVA_HOME/bin:$PATH
export PATH
- 生效环境变量,执行下面的命令
source /root/.bash_profile

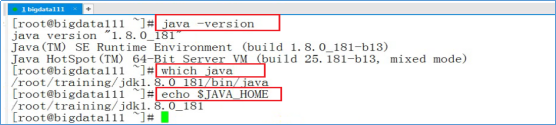
- 输入下图中,红框中的命令验证Java环境
三、解压Hadoop,并设置环境变量
- 执行下面的命令,解压hadoop-2.7.3.tar.gz
tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
- 设置Hadoop的环境变量,编辑~/.bash_profile文件,并输入以下内容
HADOOP_HOME=/root/training/hadoop-2.7.3
export HADOOP_HOME PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export PATH
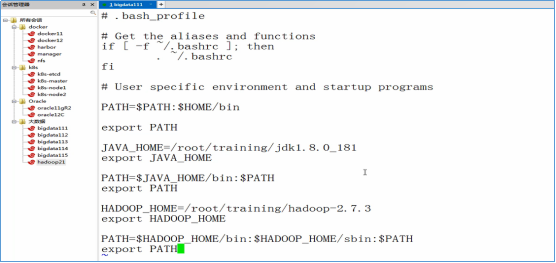
- 生效环境变量
source ~/.bash_profile
四、搭建Hadoop的本地模式
- 进入目录/root/training/hadoop-2.7.3/etc/hadoop
- 使用vi编辑器编辑文件:hadoop-env.sh
- 修改JAVA_HOME
export JAVA_HOME=/root/training/jdk1.8.0_181

- 测试Hadoop的本地模式,执行MapReduce程序。准备测试数据:vi ~/temp/data.txt
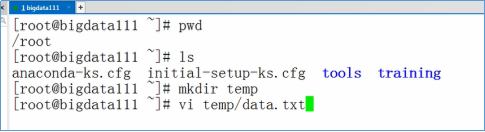
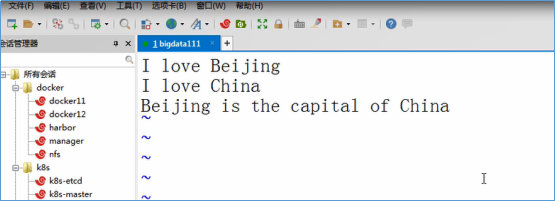
- 输入下面的数据,并保存退出
- 进入目录:/root/training/hadoop-2.7.3/share/hadoop/mapreduce

- 执行WordCount任务
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /root/temp /root/output/wc
- 根据下图的命令,查看输出结果
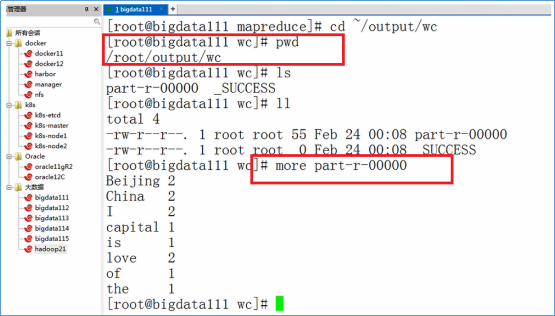
五、搭建Hadoop的伪分布模式
- 首先,搭建好Hadoop的本地模式
- 创建目录:/root/training/hadoop-2.7.3/tmp
mkdir /root/training/hadoop-2.7.3/tmp
- 进入目录:/root/training/hadoop-2.7.3/etc/hadoop
cd /root/training/hadoop-2.7.3/etc/hadoop
- 修改hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
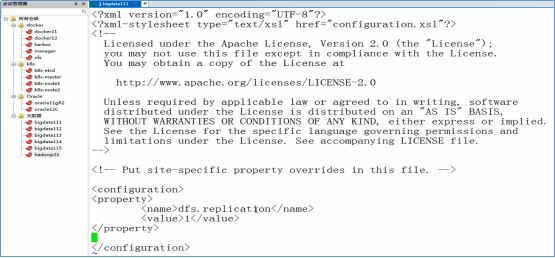
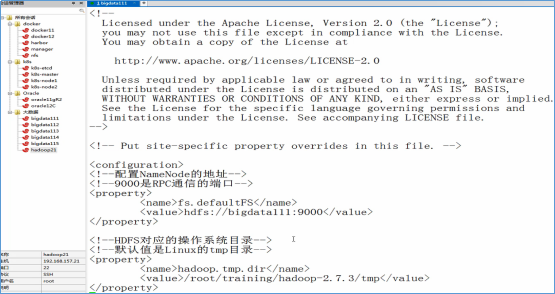
- 修改core-site.xml
<!--配置NameNode的地址-->
<!--9000是RPC通信的端口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata111:9000</value>
</property> <!--HDFS对应的操作系统目录-->
<!--默认值是Linux的tmp目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/training/hadoop-2.7.3/tmp</value>
</property>
- 修改mapred-site.xml(注意:这个文件默认没有)
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>

- 修改yarn-site.xml
<!--配置ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata111</value>
</property> <!--MapReduce运行的方式是洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>

- 格式化NameNode
hdfs namenode -format

- 启动Hadoop
start-all.sh

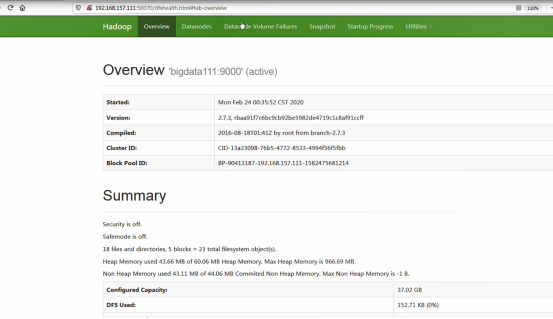
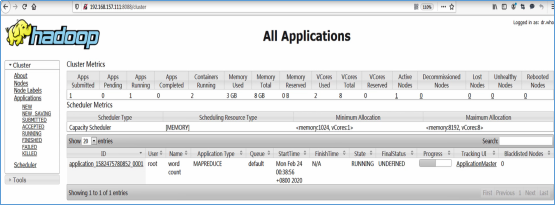
- 访问Web Console
http://192.168.157.111:50070
http://192.168.157.111:8088

【赵渝强老师】搭建Hadoop环境的更多相关文章
- 【一】、搭建Hadoop环境----本地、伪分布式
## 前期准备 1.搭建Hadoop环境需要Java的开发环境,所以需要先在LInux上安装java 2.将 jdk1.7.tar.gz 和hadoop 通过工具上传到Linux服务器上 3. ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
Hadoop在处理海量数据分析方面具有独天优势.今天花了在自己的Linux上搭建了伪分布模式,期间经历很多曲折,现在将经验总结如下. 首先,了解Hadoop的三种安装模式: 1. 单机模式. 单机模式 ...
- (转)超详细单机版搭建hadoop环境图文解析
超详细单机版搭建hadoop环境图文解析 安装过程: 一.安装Linux操作系统 二.在Ubuntu下创建hadoop用户组和用户 三.在Ubuntu下安装 ...
- 基于CentOS与VmwareStation10搭建hadoop环境
基于CentOS与VmwareStation10搭建hadoop环境 目 录 1. 概述.... 1 1.1. 软件准备.... 1 1.2. 硬件准备.... 1 2. 安装与配置虚拟机.. ...
- 基于《Hadoop权威指南 第三版》在Windows搭建Hadoop环境及运行第一个例子
在Windows环境上搭建Hadoop环境需要安装jdk1.7或以上版本.有了jdk之后,就可以进行Hadoop的搭建. 首先下载所需要的包: 1. Hadoop包: hadoop-2.5.2.tar ...
- Docker搭建Hadoop环境
文章目录 Docker搭建Hadoop环境 Docker的安装与使用 拉取镜像 克隆配置脚本 创建网桥 执行脚本 Docker命令补充 更换镜像源 安装vim 启动Hadoop 测试Word Coun ...
- Linux 下搭建 Hadoop 环境
Linux 下搭建 Hadoop 环境 作者:Grey 原文地址: 博客园:Linux 下搭建 Hadoop 环境 CSDN:Linux 下搭建 Hadoop 环境 环境要求 操作系统:CentOS ...
- 虚拟机搭建hadoop环境
这里简单用三台虚拟机,搭建了一个两个数据节点的hadoop机群,仅供新人学习.零零碎碎,花了大概一天时间,总算完成了. 环境 Linux版本:CentOS 6.5 VMware虚拟机 jdk1.6.0 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
首先要了解一下Hadoop的运行模式: 单机模式(standalone) 单机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选 ...
- 使用docker搭建hadoop环境,并配置伪分布式模式
docker 1.下载docker镜像 docker pull registry.cn-hangzhou.aliyuncs.com/kaibb/hadoop:latest 注:此镜像为阿里云个人上传镜 ...
随机推荐
- sftp文件上传下载方法
随着信息化.数字化的发展,企业对数据安全及应用安全意识普遍加强,在数据文件传输过程中,一般建议使用sftp协议进行文件传输,sftp文件操作脚本如下: sftp操作主要有三种方式,分别是sftp客户端 ...
- QT入门学习记录01
目录 前言 一.Qt安装 二.创建一个Qt工程 三.基类的区别和常用函数 1.QWidget 1.1 设置窗口标题 1.2 设置窗口大小和显示位置 1.3 显示窗口 1.4 隐藏窗口 1.5 改变窗口 ...
- 2024-08-03:用go语言,给定一个从 0 开始的字符串数组 `words`, 我们定义一个名为 `isPrefixAndSuffix` 的布尔函数,该函数接受两个字符串参数 `str1` 和
2024-08-03:用go语言,给定一个从 0 开始的字符串数组 words, 我们定义一个名为 isPrefixAndSuffix 的布尔函数,该函数接受两个字符串参数 str1 和 str2. ...
- 国产显卡如何正确打开 —— Windows平台下使用驱动精灵为国产显卡更新驱动(兆芯平台)
买了一个国产的电脑,全国产,CPU慢些也就忍了,软件兼容性差.稳定性差也忍了,大不了就用来上网看电影嘛,关键问题是这个国产显卡放电影居然有些卡,播放电影的时候存在明显的卡顿感,这简直是把国产电脑在我脑 ...
- 关于英语的语言规范问题——美式英语、英式英语和中式英语(Chinese English)到底哪个才是正宗 —— 中式英语才是英语世界的未来
因为日常生成生活中总是会使用英语进行阅读.写作.学习和交流表达,由于小的时候是学传统正宗英语(英式英语),后来长大后因为美国实力强又开始学这个时候的正宗英语(美式英语),但是由于个人的能力问题(农村娃 ...
- Linux系统下使用pytorch多进程读取图片数据时的注意事项——DataLoader的多进程使用注意事项
原文: PEP 703 – Making the Global Interpreter Lock Optional in CPython 相关内容: The GIL Affects Python Li ...
- mpi4py和cupy的联合应用(anaconda环境):GPU-aware MPI + Python GPU arrays
Demo代码: from mpi4py import MPI import cupy as cp comm = MPI.COMM_WORLD size = comm.Get_size() rank = ...
- Deepin20系统开机报错——You are in emergency mode ... Cannot open access to console, the root account is locked. emergency mode/“journalctl -xb”
参考: https://knowledge.ipason.com/ipKnowledge/knowledgedetail.html/1286 https://blog.csdn.net/wenfei1 ...
- Canvas简历编辑器-图形绘制与状态管理(轻量级DOM)
Canvas简历编辑器-图形绘制与状态管理(轻量级DOM) 在前边我们聊了数据结构的设计和剪贴板的数据操作,那么这些操作都还是比较倾向于数据相关的操作,那么我们现在就来聊聊基本的图形绘制以及图形状态管 ...
- quartz执行卡死--强制中断线程
在quartz中经常会碰到由于网络问题或者一些其他不稳定因素导致的线程卡死问题,这往往会导致数据处理的延时.而有时候一时无法定位到卡死的原因,为了降低系统风险,我们就会希望有一个超时机制,当执行超时时 ...