读《Simple statistical gradient-following algorithms for connectionist reinforcement learning》论文 提出Reinforce算法的论文
《Simple statistical gradient-following algorithms for connectionist reinforcement learning》发表于1992年,是一个比较久远的论文,因为前几天写了博文:
论文《policy-gradient-methods-for-reinforcement-learning-with-function-approximation 》的阅读——强化学习中的策略梯度算法基本形式与部分证明
所以也就顺路看看先关的论文,尤其是这篇提出Reinforce的算法,准确的来说正是这篇论文提出了基于策略搜索的强化学习方法,所以说这是个始祖型的论文。
给出部分论文内容:




--------------------------------------------------------------------------------
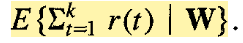
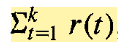

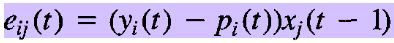
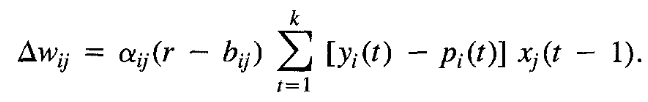
associative reinforcement problem:

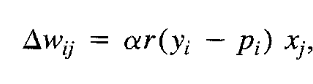
根据上面的论文中给出的公式,可以得到现在的Reinforce算法的 标准 formulation。
---------------------------------------------------------------------------------

---------------------------------------------------------------
还有一点Reinforce的名称来源是缩写:

这是原先没有想到的。
---------------------------------------------------------------
现在一般给出的reinforce算法的推导如下:

一般对于reinforce算法最终给出的形式就是上面最后的表达式。
不过上面的reinforce表达形式还可以继续推导:
因为t=0,1,2,3,4,5,......,H
假设动作集中的动作个数为A,也就是说St 状态时可以选择的动作数为A,而选择各个动作的概率和为1。而R(τ)可以写为St之前的状态行为所获得的奖励和与之后所获得的奖励和,即r(0),r(1),r(2),r(3),...,r(t-1) 折扣和 和 r(t), r(t+1), ......,r(H)折扣和。
因为当前的动作与过去的回报实际上是没有关系的,于是可以得到化简后的reinforce算法的表达式:

所以可得:


所以,化简reinforce的表现形式,可以得到:

根据上面的推导可以看出重点是在于这句话: 当前的动作与过去的回报实际上是没有关系的
对于如此关键的一句话,正是因为这句话才推导出reinforce算法的简化形式,那么这句话又是如何来进行理解呢?



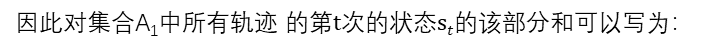
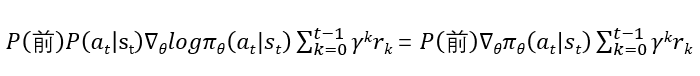
因为A1集合中的at均为a1,A2集合中的均为a2, 以此类推直至AN集合,所以其他子集合也可得上述表达式,只不过at不同而已。
因为不同集合中的该部分表达式只有at不同,即π(at|st)不同,而对不同集合中所得的上面该部分再求和,因为∑π(at|st)=1,为常数,因此求和后该部分为0。
也就是说集合A中该部分求和为0,以此类推至所有轨迹中的所有状态中的该部分,皆为0,由此对应了前面的那句话:
当前的动作与过去的回报实际上是没有关系的
其实上面的推导过程有个隐含的假设,那就是s,a返回的奖励r是确定的,而如果状态,动作对返回的奖励reward是一个分布的话上面的推导过程则隐含假设每一个状态,动作对(s,a)获得的reward都是期望值,即R使s,a所得的期望值。
----------------------------------------------------------------------
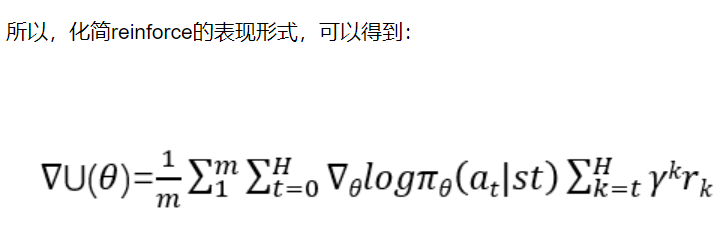
或者为:
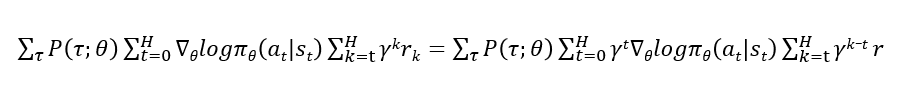
根据上面化简后得到的形式,容易得到Sutton的Reinforcement introduction中的一般形式及算法伪代码,如下:

根据上面简化形式的推导过程,容易理解sutton给出的伪代码中的:


-------------------------------------------------------------------------------------
在论文 《policy-gradient-methods-for-reinforcement-learning-with-function-approximation 》中指出策略梯度定理为reinforce算法的更一般的表现形式,下面给出策略梯度算法中episode形式下的推导:

不论是上面我们对reinforce算法的推导形式,还是策略梯度定理中给出的推导,都是等价的,都可以将episodic情景下计算表达式写为如下:
策略梯度定理中:
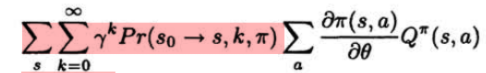
或策略梯度定理中:

或reinforce算法中在一个个episode中序惯采样的形式:

在reinforce算法中,我们是在一个episode中序惯的采样,因此γk是乘在我们的计算项中的。这里的计算项为:
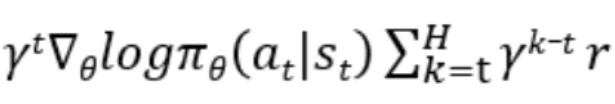
而在策略梯度定理中我们假设采样到的计算项,即
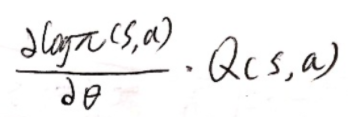
策略梯度定理中计算项的表达式之所以和reinforce算法中的有所不同在于其采样的设定,在reinforce算法中是按照一条条轨迹那样来采样的,在采样的过程中就已经把计算项前面的概率使用采样的方式来表达了,所以需要把折扣率算在计算项中。而在策略梯度定理中,并没有设定为采样,而是直接假设系统中(s,a)的γk折扣概率,我们是计算在所有轨迹中(或是系统中)第k步出现(s,a)的γk折扣概率,因此已经把折扣率算在了概率的过程中。
策略定理中没有设定为采样,但是我们为了便于理解也可以把整个系统想象成一个超大的采样,把所有会出现的轨迹都采样出来了,并且每个轨迹在系统中出现的概率和我们这里采样的频率相等,这时我们想要得到某对(s,a)则直接在这个大的采样中来获得,此时获得某对(s,a)的概率就等于所有轨迹中(或是系统中)第k步出现(s,a)的γk折扣概率,因此这样也可以理解为折扣率算在了采样的过程中。
------------------------------------------------------
读《Simple statistical gradient-following algorithms for connectionist reinforcement learning》论文 提出Reinforce算法的论文的更多相关文章
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- Discovering Reinforcement Learning Algorithms
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:2007.08794v1 [cs.LG] 17 Jul 2020 Abstract 强化学习(RL)算法根据经过多年研究手动发 ...
- [Reinforcement Learning] Policy Gradient Methods
上一篇博文的内容整理了我们如何去近似价值函数或者是动作价值函数的方法: \[ V_{\theta}(s)\approx V^{\pi}(s) \\ Q_{\theta}(s)\approx Q^{\p ...
- Machine Learning Algorithms Study Notes(3)--Learning Theory
Machine Learning Algorithms Study Notes 高雪松 @雪松Cedro Microsoft MVP 本系列文章是Andrew Ng 在斯坦福的机器学习课程 CS 22 ...
- [CS231n-CNN] Training Neural Networks Part 1 : activation functions, weight initialization, gradient flow, batch normalization | babysitting the learning process, hyperparameter optimization
课程主页:http://cs231n.stanford.edu/ Introduction to neural networks -Training Neural Network ________ ...
- Machine Learning Algorithms Study Notes(5)—Reinforcement Learning
Reinforcement Learning 对于控制决策问题的解决思路:设计一个回报函数(reward function),如果learning agent(如上面的四足机器人.象棋AI程序)在决定 ...
- 斯坦福大学公开课机器学习:梯度下降运算的学习率a(gradient descent in practice 2:learning rate alpha)
本章节主要讲怎么确定梯度下降的工作是正确的,第二是怎么选择学习率α,如下图所示: 上图显示的是梯度下降算法迭代过程中的代价函数j(θ)的值,横轴是迭代步数,纵轴是j(θ)的值 如果梯度算法正常工作,那 ...
- 论文笔记——N2N Learning: Network to Network Compression via Policy Gradient Reinforcement Learning
论文地址:https://arxiv.org/abs/1709.06030 1. 论文思想 利用强化学习,对网络进行裁剪,从Layer Removal和Layer Shrinkage两个维度进行裁剪. ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- 18 Issues in Current Deep Reinforcement Learning from ZhiHu
深度强化学习的18个关键问题 from: https://zhuanlan.zhihu.com/p/32153603 85 人赞了该文章 深度强化学习的问题在哪里?未来怎么走?哪些方面可以突破? 这两 ...
随机推荐
- .NET 使用 OpenTelemetry metrics 监控应用程序指标
上一次我们讲了 OpenTelemetry Logs 与 OpenTelemetry Traces.今天继续来说说 OpenTelemetry Metrics. 随着现代应用程序的复杂性不断增加,对于 ...
- git与gitee码云
1.git分支 在前面我们基本了解Git的使用方法,这一节我们看下GIt重要概念[分支] 背景 例如于超老师在开发一个同性交友网站,刚写到登录功能,代码还没写完,今天先睡觉了,所以就commit提交到 ...
- mongodb创建索引和删除索引和背景索引background
mongodb创建索引和删除索引和背景索引background MongoDB的背景索引允许在后台创建和重建索引,而不会对数据库的正常操作产生影响.背景索引的创建过程是非阻塞的,可以在业务运行时创建或 ...
- mongodb连接类
import com.mongodb.client.MongoClient; import com.mongodb.client.MongoClients; import com.mongodb.cl ...
- Java跳动爱心代码
1.计算爱心曲线上的点的公式 计算爱心曲线上的点的公式通常基于参数方程.以下是两种常见的参数方程表示方法,用于绘制爱心曲线: 1.1基于 (x, y) 坐标的参数方程 x = a * (2 * cos ...
- python sweetviz_数据分析及解决报告图表中文乱码
python sweetviz_数据分析 python 做数据分析,传入数据进去,就可以使用python现有的插件,进行数据分析,生成数据分析的报表,可以将复杂的数据,通过图表的形式,清晰将数据展示出 ...
- QT学习:05 元对象系统
--- title: framework-cpp-qt-05-元对象系统 EntryName: framework-cpp-qt-05-mos date: 2020-04-09 17:11:44 ca ...
- 设备树DTS 学习:学习总结(应用篇)
设备树DTS 学习:学习总结(应用篇) 背景 经过前几章的学习,我们可以说是掌握了设备树的基础用法,现在作为总结回顾. 1.设备树DTS 学习:有关概念 介绍了什么是设备树,设备树的作用,如何编译设备 ...
- 你要的AI Agent工具都在这里
只有让LLM(大模型)学会使用工具,才能做出一系列实用的AI Agent,才能发挥出LLM真正的实力.本篇,我们让AI Agent使用更多的工具,比如:外部搜索.分析CSV.文生图.执行代码等. 1. ...
- linux 4.19 ip重组
IP重组 ip重组这部分 4.19内核与3.10内核有些差别,4.9.134以后内核中不使用低水位和工作队列了,同时使用了rhashtable 替代了 hash bucket的概念,在3.10内核中使 ...