在 NVIDIA DGX Cloud 上使用 H100 GPU 轻松训练模型
在 NVIDIA DGX Cloud上使用 H100 GPU 轻松训练模型
今天,我们正式宣布推出 DGX 云端训练 (Train on DGX Cloud) 服务,这是 Hugging Face Hub 上针对企业 Hub 组织的全新服务。
通过在 DGX 云端训练,你可以轻松借助 NVIDIA DGX Cloud的高速计算基础设施来使用开放的模型。这项服务旨在让企业 Hub 的用户能够通过几次点击,就在 Hugging Face Hub 中轻松访问最新的 NVIDIA H100 Tensor Core GPU,并微调如 Llama、Mistral 和 Stable Diffusion 这样的流行生成式 AI (Generative AI) 模型。

GPU 不再是稀缺资源
这一新体验基于我们去年宣布的战略合作,旨在简化 NVIDIA 加速计算平台上开放生成式 AI 模型的训练和部署。开发者和机构面临的主要挑战之一是 GPU 资源稀缺,以及编写、测试和调试 AI 模型训练脚本的工作繁琐。在 DGX 云上训练为这些挑战提供了简便的解决方案,提供了对 NVIDIA GPUs 的即时访问,从 NVIDIA DGX Cloud上的 H100 开始。此外,该服务还提供了一个简洁的无代码训练任务创建体验,由 Hugging Face AutoTrain 和 Hugging Face Spaces 驱动。
通过 企业版的 HF Hub,组织能够为其团队提供强大 NVIDIA GPU 的即时访问权限,只需按照训练任务所用的计算实例分钟数付费。
在 DGX 云端训练是目前训练生成式 AI 模型最简单、最快速、最便捷的方式,它结合了强大 GPU 的即时访问、按需付费和无代码训练,这对全球的数据科学家来说将是一次变革性的进步!
—— Abhishek Thakur, Hugging Face AutoTrain 团队创始人
今天发布的 Hugging Face Autotrain,得益于 DGX 云的支持,标志着简化 AI 模型训练过程向前迈出了重要一步,通过将 NVIDIA 的云端 AI 超级计算机与 Hugging Face 的友好界面结合起来,我们正在帮助各个组织加速他们的 AI 创新步伐。
—— Alexis Bjorlin, NVIDIA DGX Cloud 副总裁
操作指南
在 NVIDIA DGX Cloud 上训练 Hugging Face 模型变得非常简单。以下是针对如何微调 Mistral 7B 的分步教程。
注意:你需要访问一个拥有 企业版的 HF Hub 订阅的组织账户,才能使用在 DGX 云端训练的服务
你可以在支持的生成式 AI 模型的模型页面上找到在 DGX 云端训练的选项。目前,它支持以下模型架构:Llama、Falcon、Mistral、Mixtral、T5、Gemma、Stable Diffusion 和 Stable Diffusion XL。
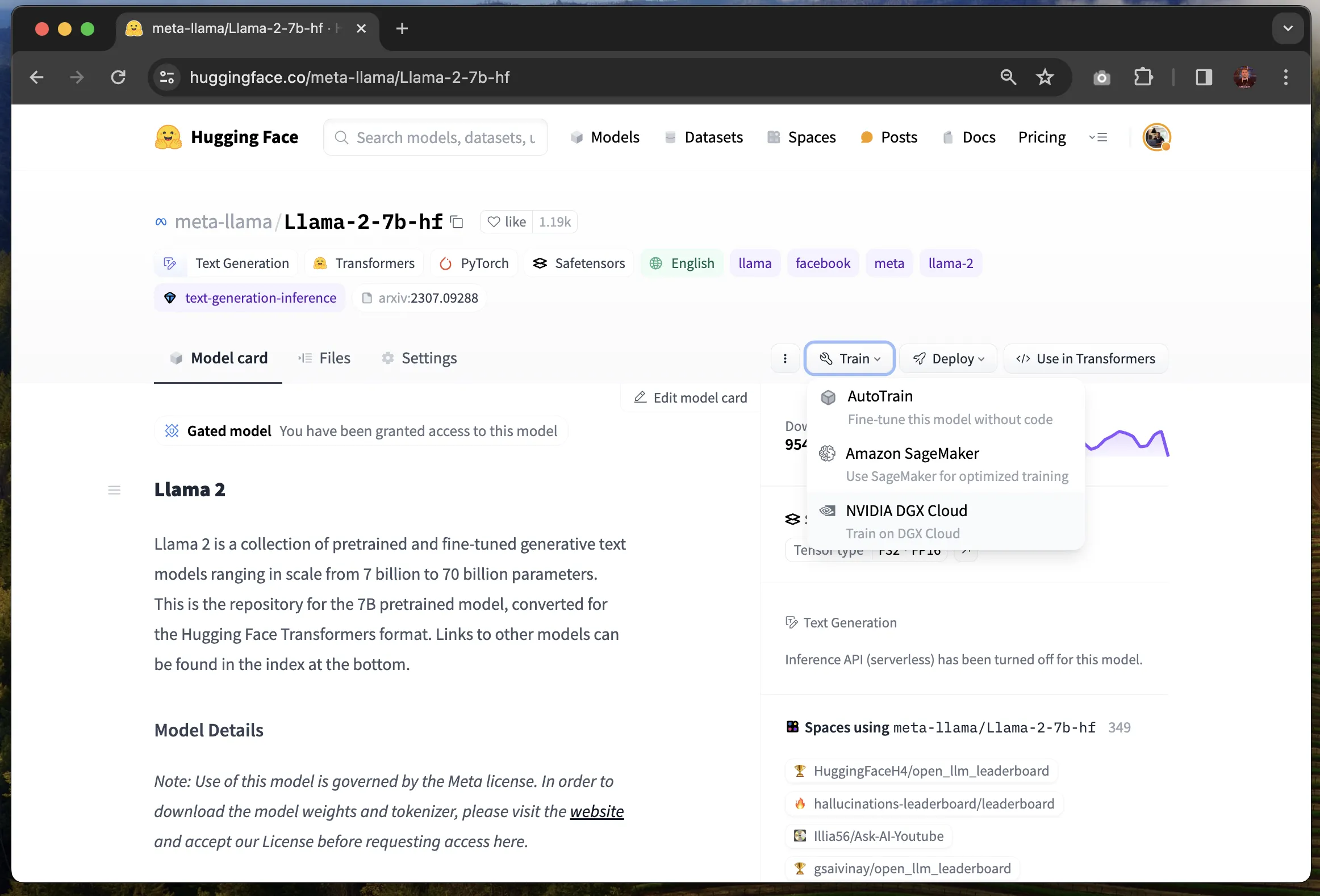
点击“训练 (Train)”菜单,并选择“NVIDIA DGX Cloud”选项,这将打开一个页面,让你可以选择你的企业组织。
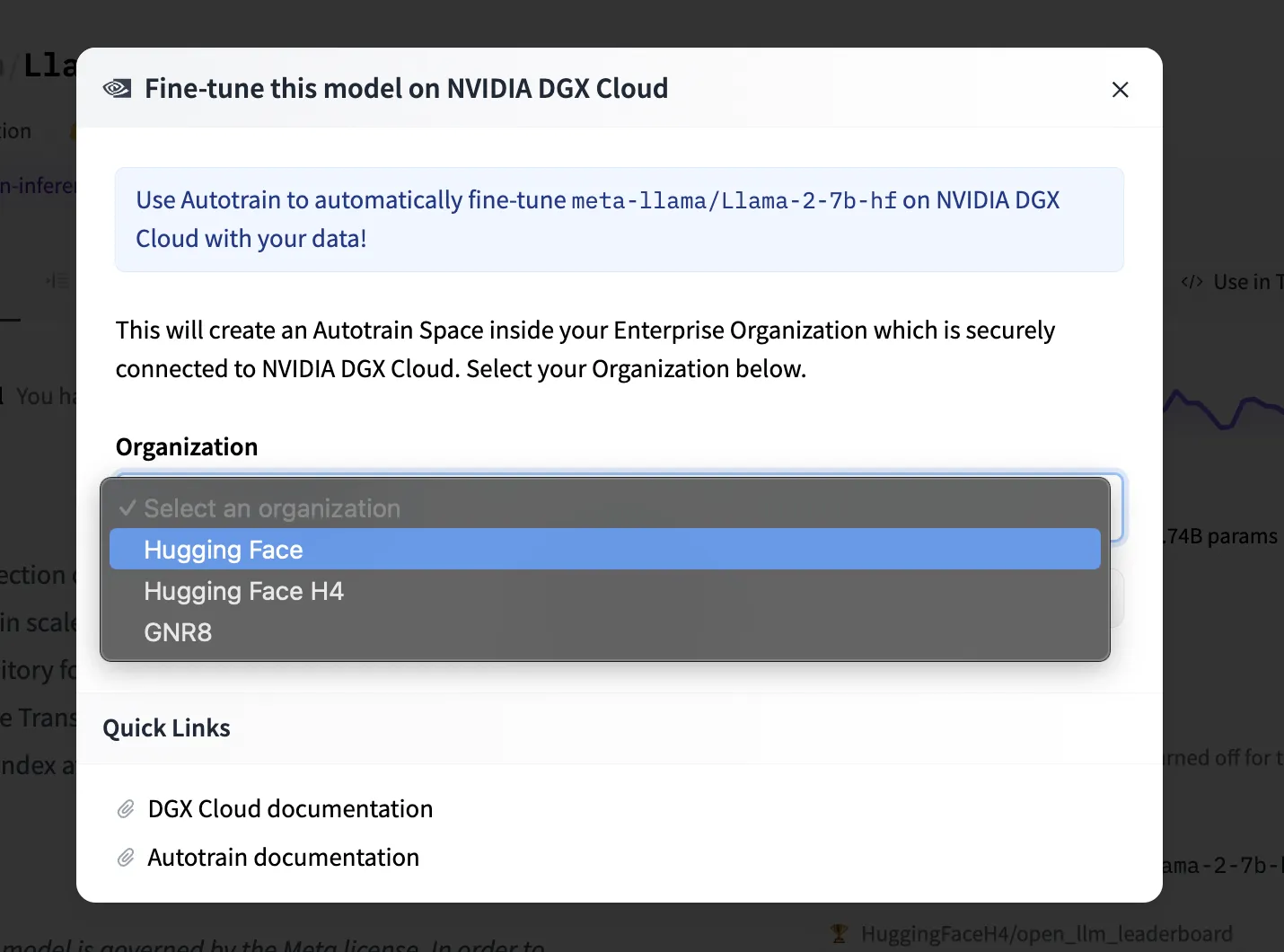
接下来,点击“Create new Space”。当你首次使用在 DGX 云端训练时,系统将在你的组织内创建一个新的 Hugging Face 空间,使你可以利用 AutoTrain 创建将在 NVIDIA DGX Cloud上执行的训练任务。当你日后需要创建更多训练任务时,系统将自动将你重定向到已存在的 AutoTrain Space 应用。
进入 AutoTrain Space 应用后,你可以通过配置硬件、基础模型、任务和训练参数来设置你的训练任务。
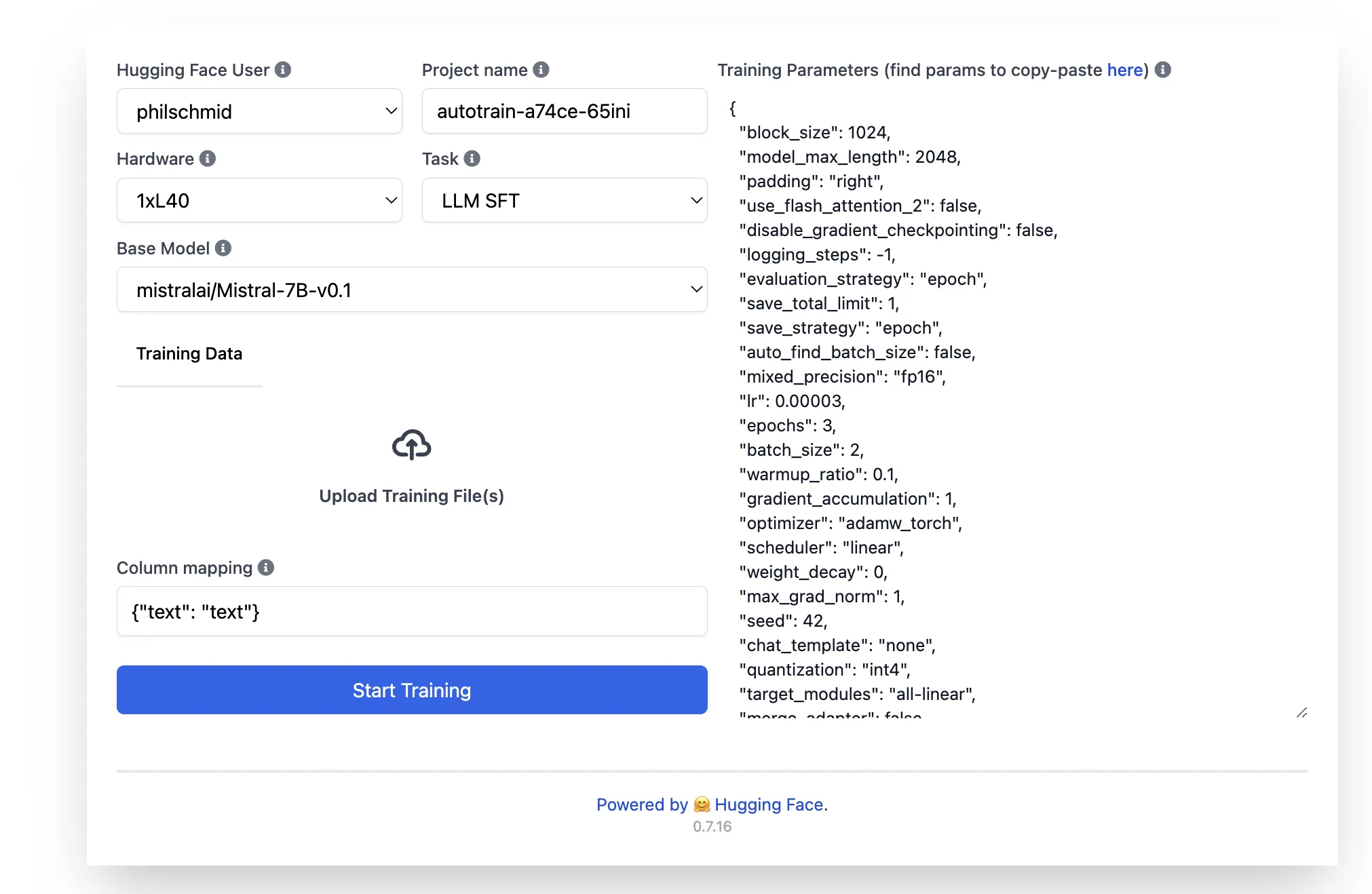
在硬件选择方面,你可以选择 NVIDIA H100 GPUs,提供 1x、2x、4x 和 8x 实例,或即将推出的 L40S GPUs。训练数据集需要直接上传至“上传训练文件”区域,目前支持 CSV 和 JSON 文件格式。请确保根据以下示例正确设置列映射。对于训练参数,你可以直接在右侧的 JSON 配置中进行编辑,例如,将训练周期数从 3 调整为 2。
一切设置完成后,点击“开始训练”即可启动你的训练任务。AutoTrain 将验证你的数据集,并请求你确认开始训练。
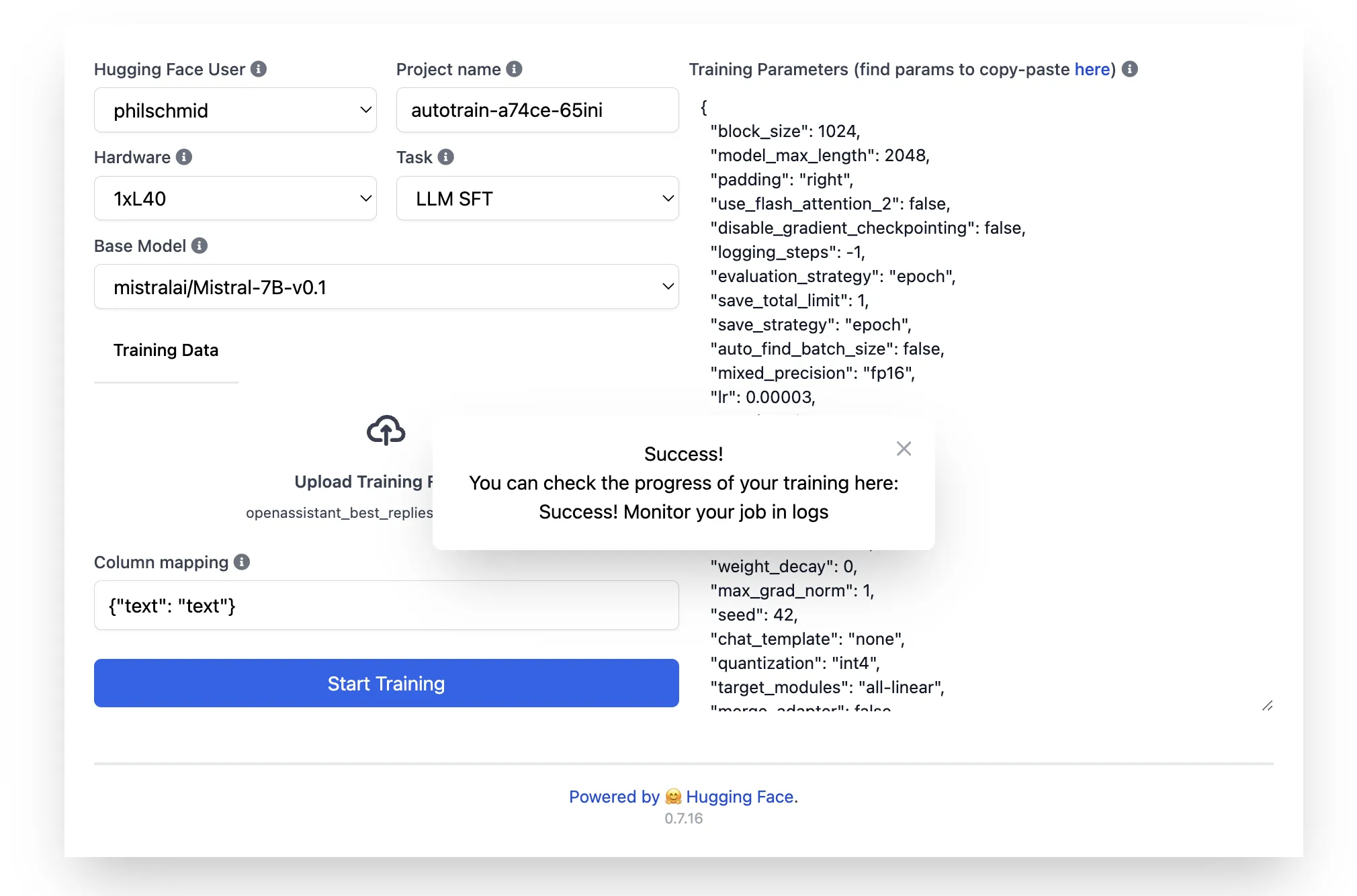
你可以通过查看这个 Space 应用的“Logs 日志”来查看训练进度。
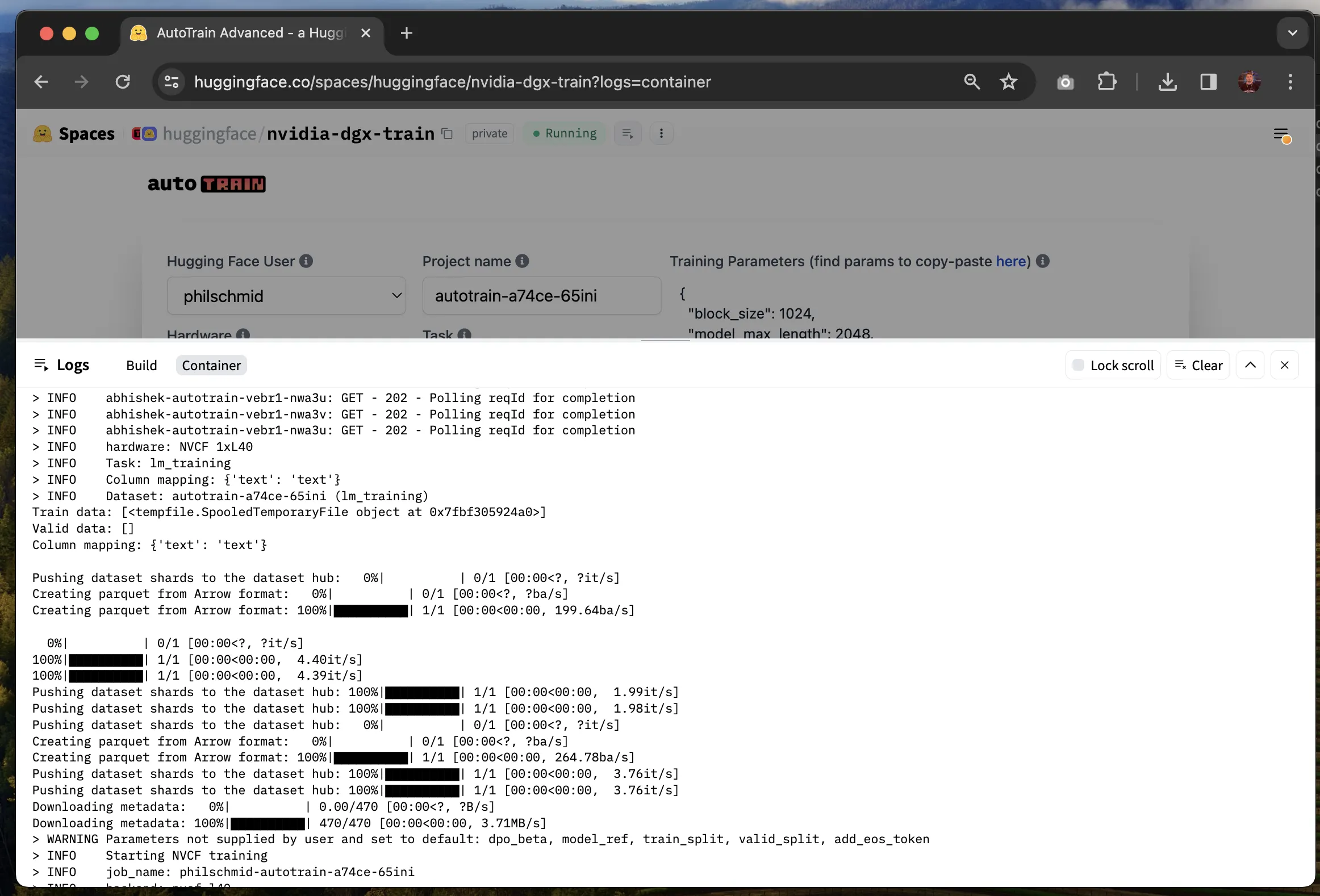
训练完成后,你微调后的模型将上传到 Hugging Face Hub 上你所选择的命名空间内的一个新的私有仓库中。
从今天起,所有企业 Hub 组织都可以使用在 DGX 云端训练的服务了!欢迎尝试并分享你的反馈!
DGX 云端训练的定价
使用在 DGX 云端训练服务,将根据你训练任务期间使用的 GPU 实例分钟数来计费。当前的训练作业价格为:H100 实例每 GPU 小时 8.25 美元,L40S 实例每 GPU 小时 2.75 美元。作业完成后,费用将累加到你企业 Hub 组织当前的月度账单中。你可以随时查看企业 Hub 组织的计费设置中的当前和历史使用情况。

例如,微调 1500 个样本的 Mistral 7B 在一台 NVIDIA L40S 上大约需要 10 分钟,成本约为 0.45 美元。
我们的旅程刚刚开始
我们很高兴能与 NVIDIA 合作,推动加速机器学习在开放科学、开源和云服务领域的普惠化。
通过 BigCode 项目的合作,我们训练了 StarCoder 2 15B,这是一个基于超过 600 种编程语言训练的全开放、最先进的代码大语言模型(LLM)。
我们在开源方面的合作推动了新的 optimum-nvidia 库的开发,加速了最新 NVIDIA GPUs 上大语言模型的推理,已经达到了 Llama 2 每秒 1200 Tokens 的推理速度。
我们在云服务方面的合作促成了今天的在 DGX 云端训练服务。我们还在与 NVIDIA 合作优化推理过程,并使加速计算对 Hugging Face 社区更容易受益。此外,Hugging Face 上一些最受欢迎的开放模型将出现在今天 GTC 上宣布的 NVIDIA NIM 微服务 上。
本周参加 GTC 的朋友们,请不要错过周三 3/20 下午 3 点 PT 的会议 S63149,Jeff 将带你深入了解在 DGX 云端训练等更多内容。另外,不要错过下一期 Hugging Cast,在那里我们将现场演示在 DGX 云端训练,并且你可以直接向 Abhishek 和 Rafael 提问,时间是周四 3/21 上午 9 点 PT / 中午 12 点 ET / 17h CET - 请在此注册。
在 NVIDIA DGX Cloud 上使用 H100 GPU 轻松训练模型的更多相关文章
- 在OpenShift平台上验证NVIDIA DGX系统的分布式多节点自动驾驶AI训练
在OpenShift平台上验证NVIDIA DGX系统的分布式多节点自动驾驶AI训练 自动驾驶汽车的深度神经网络(DNN)开发是一项艰巨的工作.本文验证了DGX多节点,多GPU,分布式训练在DXC机器 ...
- NVIDIA DGX SUPERPOD 企业解决方案
NVIDIA DGX SUPERPOD 企业解决方案 实现大规模 AI 创新的捷径 NVIDIA DGX SuperPOD 企业解决方案是业界首个支持任何组织大规模实施 AI 的基础架构解决方案.这一 ...
- NVIDIA A100 GPUs上硬件JPEG解码器和NVIDIA nvJPEG库
NVIDIA A100 GPUs上硬件JPEG解码器和NVIDIA nvJPEG库 Leveraging the Hardware JPEG Decoder and NVIDIA nvJPEG Lib ...
- Raspberry Pi B+ 定时向物联网yeelink上传CPU GPU温度
Raspberry Pi B+ 定时向物联网yeelink上传CPU GPU温度 硬件平台: Raspberry Pi B+ 软件平台: Raspberry 系统与前期安装请参见:树莓派(Ros ...
- 在Docker Hub上你可以很轻松下载到大量已经容器化的应用镜像,即拉即用——daocloud国内镜像加速
Docker之所以这么吸引人,除了它的新颖的技术外,围绕官方Registry(Docker Hub)的生态圈也是相当吸引人眼球的地方. 在Docker Hub上你可以很轻松下载到大量已经容器化的应用镜 ...
- Java内存映射,上G大文件轻松处理
内存映射文件(Memory-mapped File),指的是将一段虚拟内存逐字节映射于一个文件,使得应用程序处理文件如同访问主内存(但在真正使用到这些数据前却不会消耗物理内存,也不会有读写磁盘的操作) ...
- 通过Anaconda在Ubuntu16.04上安装 TensorFlow(GPU版本)
一. 安装环境 Ubuntu16.04.3 LST GPU: GeForce GTX1070 Python: 3.5 CUDA Toolkit 8.0 GA1 (Sept 2016) cuDNN v6 ...
- 【MindSpore】Ubuntu16.04上成功安装GPU版MindSpore1.0.1
本文是在宿主机Ubuntu16.04上拉取cuda10.1-cudnn7-ubuntu18.04的镜像,在容器中通过Miniconda3创建python3.7.5的环境并成功安装mindspore_g ...
- 矩池云上安装caffe gpu教程
选用CUDA10.0镜像 添加nvidia-cuda和修改apt源 curl -fsSL https://mirrors.aliyun.com/nvidia-cuda/ubuntu1804/x86_6 ...
- 在Azure上部署带有GPU的深度学习虚拟机
1. 登录https://portal.azure.com 2. 点击"+创建",在弹出的页面搜索"deep learning toolkit for the DSVM& ...
随机推荐
- 使用OBS Studio软件进行桌面录屏
操作系统 :Windows10_x64 OBS Studio是开源免费的录屏和直播软件,支持Windows.macOS及Linux操作系统. 这里记录下桌面录屏和桌面区域录屏的使用,也方便我后续查阅( ...
- NC19910 [CQOI2007]矩形RECT
题目链接 题目 题目描述 给一个a*b矩形,由a*b个单位正方形组成.你需要沿着网格线把它分成分空的两部分,每部分所有格子连通,且至少有一个格子在原矩形的边界上."连通"是指任两个 ...
- NC16641 [NOIP2007]守望者的逃离
题目链接 题目 题目描述 恶魔猎手尤迪安野心勃勃,他背叛了暗夜精灵,率领深藏在海底的娜迦族企图叛变.守望者在与尤迪安的交锋中遭遇了围杀,被困在一个荒芜的大岛上.为了杀死守望者,尤迪安开始对这个荒岛施咒 ...
- MySQL树形结构表设计
两个字段: pid:父级ID parent_ids:所有经过的路径节点ID 这样设计有个好处是,可以查任意节点的所有子节点,从任意节点开始既可以向上查,也可以向下查 select * from ent ...
- Rancher 2.x 安装
Rancher 是一个容器管理平台.Rancher 简化了使用 Kubernetes 的流程. 下面记录一下手动安装Rancher的步骤 1. 部署 Rancher Server 执行以下命令即可( ...
- 惠普CP1025 因转印离合器导致打印不全大片空白的问题
问题症状 自检只打印出一部分, 后面大部分都是空白. 如果是碳盒缺粉, 应该是均匀地浅或者空白, 如果是成像鼓的问题, 应该是从上到下成条状的不均匀, 这样显示一节后空白的情况是没见过, 上网查有类似 ...
- CSS实现图形效果
CSS实现图形效果 CSS实现正方形.长方形.圆形.半圆.椭圆.三角形.平行四边形.菱形.梯形.六角星.五角星.心形.消息框. 正方形 <section> <div id=" ...
- Oracle设置和删除不可用列
Oracle设置和删除不可用列 1.不可用列是什么? 就是表中的1个或多个列被ALTER TABLE-SET UNUSED 语句设置为无法再被程序利用的列. 2.使用场景? If you are co ...
- 最简最快了解RPC核心流程
本文主要以最简易最快速的方式介绍RPC调用核心流程,文中以Dubbo为例.同时,会写一个简易的RPC调用代码,方便理解和记忆核心组件和核心流程. 1.核心思想 RPC调用过程中,最粗矿的核心组件3个: ...
- RAID 10磁盘阵列实践
RAID概述 RAID技术通过把多个硬盘设备组合成一个容量更大.安全性更好的磁盘阵列,利用分散读写技术来提升磁盘阵列整体的性能,同时把多个重要数据的副本同步到不同的物理硬盘设备上,从而起到了非常好的数 ...