Mysql--JOIN连表查询
一、Join查询原理
MySQL内部采用了一种叫做 nested loop join(嵌套循环连接)的算法:通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。如果还有第三个参与 Join,则再通过前两个表的 Join 结果集作为循环基础数据,再一次通过循环查询条件到第三个表中查询数据,如此往复,基本上MySQL采用的是最容易理解的算法来实现join
所以驱动表的选择非常重要,驱动表的数据小可以显著降低扫描的行。
一般情况下参与联合查询的两张表都会一大一小,如果是join,在没有其他过滤条件的情况下MySQL会自动选择小表作为驱动表。简单来说,驱动表就是主表,left join 中的左表就是驱动表,right join 中的右表是驱动表。
二、Nested-Loop Join
如 select * from t1 inner join t2 on t1.id=t2.tid ,t1称为外层表,也可称为驱动表,t2称为内层表,也可称为被驱动表
mysql只支持一种join算法:Nested-Loop Join(嵌套循环连接),但Nested-Loop Join有三种变种:
- 简单嵌套循环连接:Simple Nested-Loop Join(SNLJ)
- 索引嵌套循环连接:Index Nested-Loop Join(INLJ)
- 缓存块嵌套循环连接:Block Nested-Loop Join(BNLJ)
在选择Join算法时,会有优先级,理论上会优先判断能否使用INLJ、BNLJ: Index Nested-LoopJoin > Block Nested-Loop Join > Simple Nested-Loop Join
2.1 Simple Nested-Loop Join
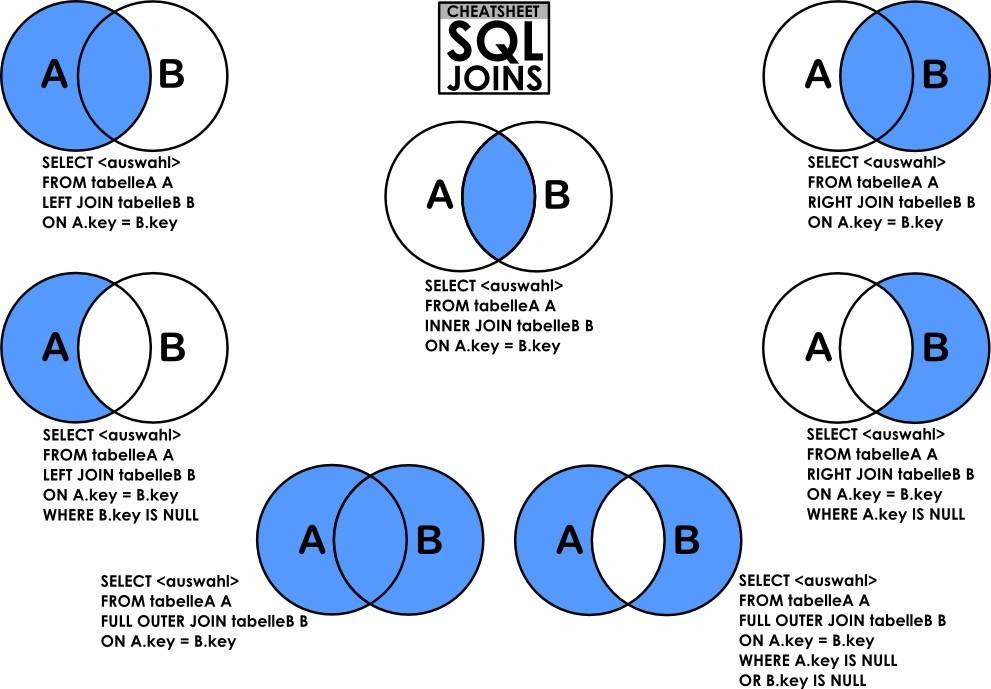
如下图,r为驱动表,s为匹配表,可以看到从r中分别取出r1、r2、…、rn去匹配s表的左右列,然后再合并数据,对s表进行了rn次访问,对数据库开销大。
如果table1有1万条数据,table2有1万条数据,那么数据比较的次数=1万 * 1万 =1亿次,这种查询效率会非常慢。
故基本不使用这种方式,mysql会根据情况选择其他两种方式进行查询
2.2 Index Nested-Loop Join(减少内层表数据的匹配次数)
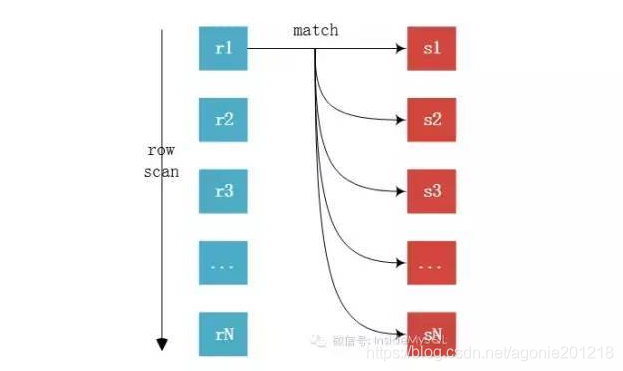
- 索引嵌套循环连接是基于索引进行连接的算法,索引是基于内层表的,通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录进行比较, 从而利用索引的查询减少了对内层表的匹配次数,优势极大的提升了 join的性能
- 使用场景:只有内层表join的列有索引时,才能用到Index Nested-LoopJoin进行连接
- 由于用到索引,如果索引是辅助索引而且返回的数据还包括内层表的其他数据,则会回内层表查询数据,多了一些IO操作
这个要求非驱动表(匹配表s)上有索引,可以通过索引来减少比较,加速查询。
在查询时,驱动表(r)会根据关联字段的索引进行查找,当在索引上找到符合的值,再回表进行查询,也就是只有当匹配到索引以后才会进行回表查询。
如果非驱动表(s)的关联健是主键的话,性能会非常高,如果不是主键,要进行多次回表查询,先关联索引,然后根据二级索引的主键ID进行回表操作,性能上比索引是主键要慢。
2.3 Block Nested-Loop Join(减少内层表数据的循环次数)
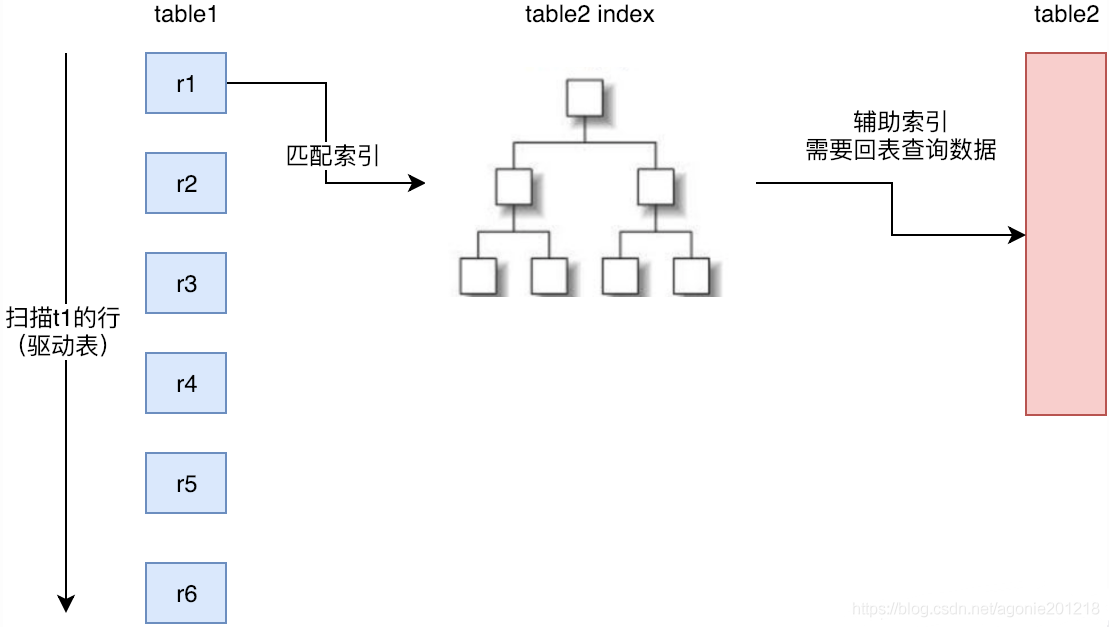
缓存块嵌套循环连接通过一次性缓存多条数据,把参与查询的列缓存到Join Buffer 里,然后拿join buffer里的数据批量与内层表的数据进行匹配,从而减少了内层循环的次数(遍历一次内层表就可以批量匹配一次Join Buffer里面的外层表数据)。
当不使用Index Nested-Loop Join的时候(内层表查询不适用索引),默认使用Block Nested-Loop Join
- Join Buffer会缓存所有参与查询的列而不是只有Join的列
- 可以通过调整join_buffer_size缓存大小
- join_buffer_size的默认值是256K,join_buffer_size的最大值在MySQL 5.1.22版本前是4G-1,而之后的版本才能在64位操作系统下申请大于4G的Join Buffer空间
- 使用Block Nested-Loop Join算法需要开启优化器管理配置的optimizer_switch的设置block_nested_loop为on,默认为开启
三 优化
- 用小结果集驱动大结果集,减少外层循环的数据量:如果小结果集和大结果集连接的列都是索引列,mysql在内连接时也会选择用小结果集驱动大结果集,因为索引查询的成本是比较固定的,这时候外层的循环越少,join的速度便越快
- 为匹配的条件增加索引:争取使用INLJ,减少内层表的循环次数
- 增大join buffer size的大小:当使用BNLJ时,一次缓存的数据越多,那么外层表循环的次数就越少
- 减少不必要的字段查询:
- 当用到BNLJ时,字段越少,join buffer 所缓存的数据就越多,外层表的循环次数就越少
- 当用到INLJ时,如果可以不回表查询,即利用到覆盖索引,则可能可以提示速度
- 尽量使用inner join,避免left join 和NULL
摘抄自(有删改):https://blog.csdn.net/agonie201218/article/details/106993948
四 补充
4.1 找出所有在左表,不在右表的纪录
注:列值为null应该用is null 而不能用=NULL
a.user_id 列必须声明为 NOT NULL 的
select id, name, action from user as u left join user_action a on u.id = a.user_id where a.user_id is NULL
4.2 where使用
在连表查询时,通常在子查询中使用 WHERE 子句限制表数据会比在最后的主查询中使用 WHERE 子句效率更高。
原因是,在子查询中使用 WHERE 子句可以对较小的结果集进行过滤,减少了主查询需要处理的数据量。这样可以减少数据的传输和处理的负担,提高查询性能。
另一方面,在最后的主查询中使用 WHERE 子句时,会先执行联接操作并获取所有的匹配行,然后再对整个结果集进行过滤。这样会导致在查询过程中处理了更多的数据,增加了查询的开销,可能导致性能下降。
因此,将限制条件放在子查询中,可以尽早地过滤数据,只将需要的数据传递到后续的查询阶段,减少了不必要的计算和数据传输,更加高效。
SELECT A.*
FROM 大表A A
JOIN (SELECT * FROM 小表B WHERE C) AS B ON A.关联键 = B.关联键;
4.2 多表联合查询
在MySQL关联查询中,建议将小表作为驱动表,而将大表作为被驱动表。
因为小表通常拥有较少的记录,而大表可能包含大量的数据。当小表作为驱动表时,MySQL可以先从小表中获取数据,并使用这些数据来查询大表。这样做的好处是可以减少查询的数据量,提高查询的效率。如果将大表作为驱动表,MySQL需要先扫描大表的所有记录,然后再根据关联条件查询小表,这样会增加查询的时间和资源消耗。
需要注意的是,选择驱动表的原则是根据查询的条件和数据量来决定,而不是根据表的大小。有时候大表可能也是更适合作为驱动表的,这需要根据具体的情况进行分析和测试。
假设t4为大表:
select
b.name,
c.view_name,
a.notify_time,
a.product,
a.alarm_id
from
(
select
psa,
group_id
from
t1
) a
left join (
select
id,
name
from
t2
) b on a.group_id=b.id
left join (
select
view_name,
psas
from
t3
where
type='alarm'
) c on concat('"', c.psas, '"') regexp a.psa
left join (
select
notify_time,
product,
alarm_id
from
t4
where
product!='/'
) d on d.product=b.psa
Mysql--JOIN连表查询的更多相关文章
- MySQL之多表查询一 介绍 二 多表连接查询 三 符合条件连接查询 四 子查询 五 综合练习
MySQL之多表查询 阅读目录 一 介绍 二 多表连接查询 三 符合条件连接查询 四 子查询 五 综合练习 一 介绍 本节主题 多表连接查询 复合条件连接查询 子查询 首先说一下,我们写项目一般都会建 ...
- day15(mysql 的多表查询,事务)
mysql之多表查询 1.合并结果集 作用:合并结果集就是把两个select语句查询的结果连接到一起! /*创建表t1*/ CREATE TABLE t1( a INT PRIMARY KEY , b ...
- mysql数据库优化课程---11、mysql普通多表查询
mysql数据库优化课程---11.mysql普通多表查询 一.总结 一句话总结:select user.username,user.age,class.name,class.ctime from u ...
- Mariadb/MySQL数据库单表查询基本操作及DML语句
Mariadb/MySQL数据库单表查询基本操作及DML语句 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一数据库及表相关概述 1>.数据库操作 创建数据库: CREATE ...
- day 39 MySQL之多表查询
MySQL之多表查询 阅读目录 一 介绍 二 多表连接查询 三 符合条件连接查询 四 子查询 五 综合练习 一 介绍 本节主题 多表连接查询 复合条件连接查询 子查询 首先说一下,我们写项目一般都 ...
- MySQL的联表查询
MySQL的联表查询 首选:分析查询的字段来自哪些表 进而:确定交集 然后:确定判断的条件 比如:从student表 和 result表 查学号.考试名称.学时.考试日期.考试成绩 表1: 学号 考试 ...
- 对于大量left join 的表查询,可以在关键的 连接节点字段上创建索引。
对于大量left join 的表查询,可以在关键的 连接节点字段上创建索引. 问题: 大量的left join 怎么优化 select a.id,a.num,b.num,b.pcs,c.num, c. ...
- Vc数据库编程基础MySql数据库的表查询功能
Vc数据库编程基础MySql数据库的表查询功能 一丶简介 不管是任何数据库.都会有查询功能.而且是很重要的功能.上一讲知识简单的讲解了表的查询所有. 那么这次我们需要掌握的则是. 1.使用select ...
- mybatis逆向工程,实现join多表查询,避免多表相同字段名的陷阱
mybatis逆向工程,实现join多表查询,避免多表相同字段名的陷阱 前言:使用 mybatis generator 生成表格对应的pojo.dao.mapper,以及对应的example的 ...
- MySQL之单表查询 一 单表查询的语法 二 关键字的执行优先级(重点) 三 简单查询 四 WHERE约束 五 分组查询:GROUP BY 六 HAVING过滤 七 查询排序:ORDER BY 八 限制查询的记录数:LIMIT 九 使用正则表达式查询
MySQL之单表查询 阅读目录 一 单表查询的语法 二 关键字的执行优先级(重点) 三 简单查询 四 WHERE约束 五 分组查询:GROUP BY 六 HAVING过滤 七 查询排序:ORDER B ...
随机推荐
- Python入门--字符串
字符串的使用和C语言 .java中一致 .使用" "(双引号)并且字符串可以与数字相乘,表示我使用这个字符串次数 字符串的连接:'+' Python中的变量直接赋值即可 ,如果赋予 ...
- 重学Java(一):什么是对象
前言 本系列文章内容来自于<Thinking in Java>作者的最新续作<On Java>基础卷,作者根据最新 Java 8.11.17的内容,重讲了Java的编程思想,值 ...
- 玩转开源 | 搭建 Hugo 管理 Markdown 文档
在工作.学习中,不可避免会要写一些文档:又或者想搭建个简单网站,记录和分享您的生活经验或知识:撰写这些文档中使用 markdown 是一个非常不错的选择,让我们更加聚焦在文档表达的内容上.实际上笔者的 ...
- C/C++ Zlib库封装MyZip压缩类
Zlib是一个开源的数据压缩库,提供了一种通用的数据压缩和解压缩算法.它最初由Jean-Loup Gailly和Mark Adler开发,旨在成为一个高效.轻量级的压缩库,其被广泛应用于许多领域,包括 ...
- vue+element-ui中引入编辑器
wangeditor编辑器 1.执行:npm install --save wangeditor 2.在你需要调用编辑器的vue文件中引入 wangeditor: import E from 'w ...
- 是谁的简历上全是秒杀商城和RPC啊?
是不是还在苦于自己简历上的项目离不开商城.RPC.秒杀.论坛.外卖.点评等等烂大街的项目?是不是翻遍全网再很难找到一个既有含金量又能看得懂的项目?那么现在就不用找了,下面这个项目一定适合你! 高性能短 ...
- What's past is prologue
凡是过去,皆为序章.爱所有人,信任少数人,不负任何人.我荒废了时间,时间便把我荒废了. 在灰暗的日子中,不要让冷酷的命运窃喜:命运既然来凌辱我们,就应该用处之泰然的态度予以报复.明智的人决不坐下来为失 ...
- MySQL运维4-Mycat入门
一.mycat概述 mycat是阿里巴巴企业下的开源的,基于JAVA语言编写的MySQL数据库中间件,可以像使用MySQL一样来使用Mycat,对于开发人员来说根本感觉不到mycat的存在.之前在国内 ...
- Python汉诺塔递归算法实现
关于用递归实现的原理,请查看我之前的文章: C语言与汉诺塔 C#与汉诺塔 以下为代码: count = 0 def move(pile, src, tmp, dst): global count if ...
- 2020-11-05:谈一下TCP的拥塞控制。
福哥答案2020-11-05: 所谓拥塞控制,是指防止过多的数据注入网络,保证网络中的路由器或链路不致过载.出现拥塞时,端点并不了解到拥塞发生的细节,对通信连接的端点来说,拥塞旺旺表现为通信时延的增加 ...