2.Storm集群部署及单词统计案例
1、集群部署的基本流程
2、集群部署的基础环境准备
3、Storm集群部署
4、Storm集群的进程及日志熟悉
5、Storm集群的常用操作命令
6、Storm源码下载及目录熟悉
7、Storm 单词计数案列
1、集群部署的基本流程
集群部署的流程:下载安装包、解压安装包、修改配置文件、分发安装包、启动集群
注意:所有的集群上都需要配置hosts:vi /etc/hosts
2、集群部署的基础环境准备
1、storm安装依赖Python,所以在安装前请确保Python已经安装成功了
[root@hadoop1 software]# wget http://www.python.org/ftp/python/2.6.6/Python-2.6.6.tar.bz2
[root@hadoop1 software]# tar -jxvf Python-2.6.6.tar.bz2
[root@hadoop1 software]# cd Python-2.6.6
[root@hadoop1 software]# ./configure
[root@hadoop1 software]# make
[root@hadoop1 software]# make install
2、在安装前要保证shizhan2,shizhan3,shizhan5之间能够互相两两之间ssh免登陆
3、安装好JDK
4、安转好Zookeeper集群(shizhan2、shizhan3、shizhan5)
3、Storm集群部署:
3.1.下载安装包:wget https://mirrors.tuna.tsinghua.edu.cn/apache/storm/apache-storm-1.1.2/apache-storm-1.1.2.tar.gz
3.2.解压安装包:
[root@shizhan2 software]# mkdir -p /export/servers/
[root@shizhan2 software]# tar -xzvf apache-storm-1.1.2.tar.gz -C /export/servers/
[root@shizhan2 software]# cd /export/servers/
[root@shizhan2 servers]# ln -s apache-storm-1.1.2 storm
3.3.修改配置文件:
配置文件:vi /export/servers/apache-storm-1.1.2/conf/storm.yaml
#指定strom使用的zk集群,如果Zookeeper集群使用的不是默认端口,那么还需要storm.zookeeper.port选项
storm.zookeeper.servers:
- "shizhan2"
- "shizhan3"
- "shizhan5"
#strom.local.dir : Nimbus和Supervisor进程用于存储少量状态,如jars、confs等的本地磁盘目录,需要提前创建该目录并给以足够的访问权限。然后在storm.yaml中配置目录,如:
storm.local.dir: "/home/software/stormInstallPath/workdir"
#指定storm集群中的nimbus节点所在的服务器
nimbus.host: "shizhan2"
#指定nimbus启动JVM最大可用内存大小
nimbus.childopts: "-Xmx1024m"
#指定supervisor启动JVM最大可用内存大小
supervisor.childopts: "-Xmx1024m"
#指定supervisor节点上,每个worker启动JVM最大可用内存大小
worker.childopts: "-Xmx768m"
#指定ui启动JVM最大可用内存大小,ui服务一般与nimbus同在一个节点上。
ui.childopts: "-Xmx768m"
#指定supervisor节点上,启动worker时对应的端口号,每个端口对应槽,每个槽位对应一个worker,对于Supervisor工作节点,需要配置该工作节点可以运行的worker数量。每个worker占用一个单独的端口用于接收消息,该配置选线即用于接收消息,该配置选项用于定义哪些端口是可以被worker使用的。默认情况下每个节点下可以运行4个workers,分别在6700,6701,6702,6703端口,如:
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
3.4.分发安装包:
scp -r /export/servers shizhan3:/export/
scp -r /export/servers shizhan5:/export/
cd /export/servers/
ln -s apache-storm-0.9.5 storm
配置strom的环境变量(shizhan2,shizhan3,shizhan5这几台服务器都要相应的修改)
[root@hadoop1 software]# vim /etc/profile
#set storm env
export STORM_HOME=/export/servers/apache-storm-1.1.2
export PATH=$PATH:$STORM_HOME/bin
[root@hadoop1 software]# source /etc/profile
3.5启动集群:先启动zookeeper集群,再启动Storm集群
在nimbus.host所属的机器上启动 nimbus服务
cd /export/servers/storm/bin/
nohup ./storm nimbus &
在nimbus.host所属的机器上启动ui服务
cd /export/servers/storm/bin/
nohup ./storm ui &
在其它个点击上启动supervisor服务
cd /export/servers/storm/bin/
nohup ./storm supervisor &
3.5 查看集群 Storm UI:
http://shizhan2:8080,即可查看storm UI界面
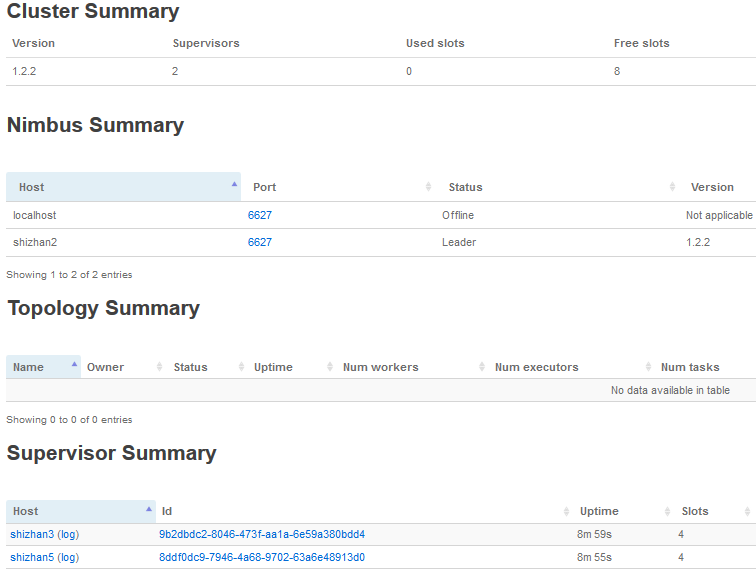
4.1 查看nimbus的日志信息(在shizhan2的nimbus服务器上)

(该worker正在运行wordcount程序)
Storm命令可以用来管理拓扑,它们可以提交、杀死、禁用、再平衡拓扑
提交任务命令格式:storm jar 【jar路径】 【拓扑包名.拓扑类名】 【拓扑名称】
bin/storm jar examples/storm-starter/storm-starter-topologies-0.9.6.jar storm.starter.WordCountTopology wordcount
杀死任务命令格式:storm kill 【拓扑名称】 -w 10(执行kill命令时可以通过-w [等待秒数]指定拓扑停用以后的等待时间)
storm kill topology-name -w 10
停用任务命令格式:storm deactivte 【拓扑名称】
storm deactivte topology-name
我们能够挂起或停用运行中的拓扑。当停用拓扑时,所有已分发的元组都会得到处理,但是spouts的nextTuple方法不会被调用。
销毁一个拓扑,可以使用kill命令。它会以一种安全的方式销毁一个拓扑,首先停用拓扑,在等待拓扑消息的时间段内允许拓扑完成
当前的数据流。
启用任务命令格式:storm activate【拓扑名称】
storm activate topology-name
重新部署任务命令格式:storm rebalance 【拓扑名称】
storm rebalance topology-name
再平衡使你重分配集群任务。这是个很强大的命令。比如,你向一个运行中的集群增加了节点。再平衡命令将会停用拓扑,然后
在相应超时时间之后重分配工人,并重启拓扑。
6、Storm源码下载及目录熟悉(很重要):
1.在Storm官方网站上寻找源码地址: http://storm.apache.org/downloads.html
2.点击Source Code
3.进入GitHub后,拷贝Storm源码地址,点击Clone or Download,进行下载,也可使用Subversion客户端下载


7、Storm单词计数案例:
集群部署成功时,测试自带wordcount程序案例,熟悉任务提交部署流程
2.Storm集群部署及单词统计案例的更多相关文章
- Storm集群部署及单词技术
1. 集群部署的基本流程 集群部署的流程:下载安装包.解压安装包.修改配置文件.分发安装包.启动集群 注意: 所有的集群上都需要配置hosts vi /etc/hosts 192.168.239.1 ...
- Storm 系列(三)Storm 集群部署和配置
Storm 系列(二)Storm 集群部署和配置 本章中主要介绍了 Storm 的部署过程以及相关的配置信息.通过本章内容,帮助读者从零开始搭建一个 Storm 集群. 一.Storm 的依赖组件 1 ...
- storm集群部署和配置过程详解
先整体介绍一下搭建storm集群的步骤: 设置zookeeper集群 安装依赖到所有nimbus和worker节点 下载并解压storm发布版本到所有nimbus和worker节点 配置storm ...
- Storm集群部署
一. 说明 Storm是一个分布式实时计算系统,Storm对于实时计算的意义就相当于Hadoop对于批量计算的意义.对于实时性较高的系统Storm是不错的选择.Hadoop提供了map, reduce ...
- Storm1.0.3集群部署
Storm集群部署 所有集群部署的基本流程都差不多:下载安装包并上传.解压安装包并配置环境变量.修改配置文件.分发安装包.启动集群.查看集群是否部署成功. 1.所有的集群上都要配置hosts vi ...
- 02_Storm集群部署
1. 部署前的硬件及软件检查 硬件要求 1)storm集群部署包括zookeeper部署,而zookeeper集群最小为3台机器2)storm的计算过程都在内存中完成,因此内存要尽量大3)storm少 ...
- Storm集群安装部署步骤【详细版】
作者: 大圆那些事 | 文章可以转载,请以超链接形式标明文章原始出处和作者信息 网址: http://www.cnblogs.com/panfeng412/archive/2012/11/30/how ...
- Storm入门教程 第三章Storm集群安装部署步骤、storm开发环境
一. Storm集群组件 Storm集群中包含两类节点:主控节点(Master Node)和工作节点(Work Node).其分别对应的角色如下: 主控节点(Master Node)上运行一个被称为N ...
- Storm集群安装部署步骤
本文以Twitter Storm官方Wiki为基础,详细描述如何快速搭建一个Storm集群,其中,项目实践中遇到的问题及经验总结,在相应章节以"注意事项"的形式给出. 1. Sto ...
随机推荐
- VS2010插件之NuGet
Visual Studio(简写VS)是.net程序员开发必不可少的开发工具,随着VS的版本不断的升级和使用用户的扩大,现在针对VS开发了许多的开源免费的插件,大大的方便了程序员的开发,提高了开发效率 ...
- 【Leetcode_easy】643. Maximum Average Subarray I
problem 643. Maximum Average Subarray I 题意:一定长度的子数组的最大平均值. solution1:计算子数组之后的常用方法是建立累加数组,然后再计算任意一定长度 ...
- .Net Core 定时器Quartz
最近因为项目需要用到了Quartz,下面简单记录一下. 一.首先需要安装Quartz. 二.定义一个执行的Job类,实现IJob接口,接口有一个方法Execute,用来执行定时任务的实现内容. pub ...
- maven项目创建.m2文件夹
创建为.m2.,m2前后都要有点,然后去掉后面的点 settings.xml文件如下: <?xml version="1.0" encoding="UTF-8&qu ...
- 【web 安全测试Tools】BurpSuite 1.7.32及注册机【无后门版】
BurpSuite 1.7.32 原版+注册机 下载 链接:https://pan.baidu.com/s/1LFpXn2ulTLlcYZHG5jEjyw 密码:mie3 注意无后门版文件完整性: b ...
- 为什么每次登录要手动 source /etc/profile ...
由于执行顺序如下,故追个查看以下文件,看看是不是 JAVA_HOME, PATH 等环境变量在后面的文件中被重写覆盖了. 1. /etc/profile2. /etc/environment3. ~/ ...
- 一个websocket的demo(php server)
notice: 通过命令行执行php文件 如 php -q c:\path\server.php 通过本地web服务器访问 http://127.0.0.1/websocket/index.php即 ...
- 【VS开发】TCP服务端如何判断客户端断开连接
原文出自:http://www.cnblogs.com/youxin/p/4056041.html 一篇文章: 最近在做一个服务器端程序,C/S结构.功能方面比较简单就是client端与serve ...
- 解决maven打包时,会编译特定文件导致文件不可用
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-resou ...
- socket网络编程 的基本方法:--ongoing
https://blog.csdn.net/shuxiaogd/article/details/50366039在学习网络编程时,我们总是从最简单的Server程序写起:socket -> bi ...