Canal——Canal-Adapter源码在IDEA部署运行
一、下载源码
我这里用的是canal-1.1.4版本

源码结构
client-adapter项目就是本次要部署运行的

源码导入到IDEA中的结构如下:
二、安装配置
- 找到manven模块中有root的那个模块,然后点击install进行安装

待安装完成后,会在对应的项目的target目录下产生相应的运行包,如果不想在开发工具中运行的话,直接拷贝对应的包即可。
修改launcher的application.yml配置
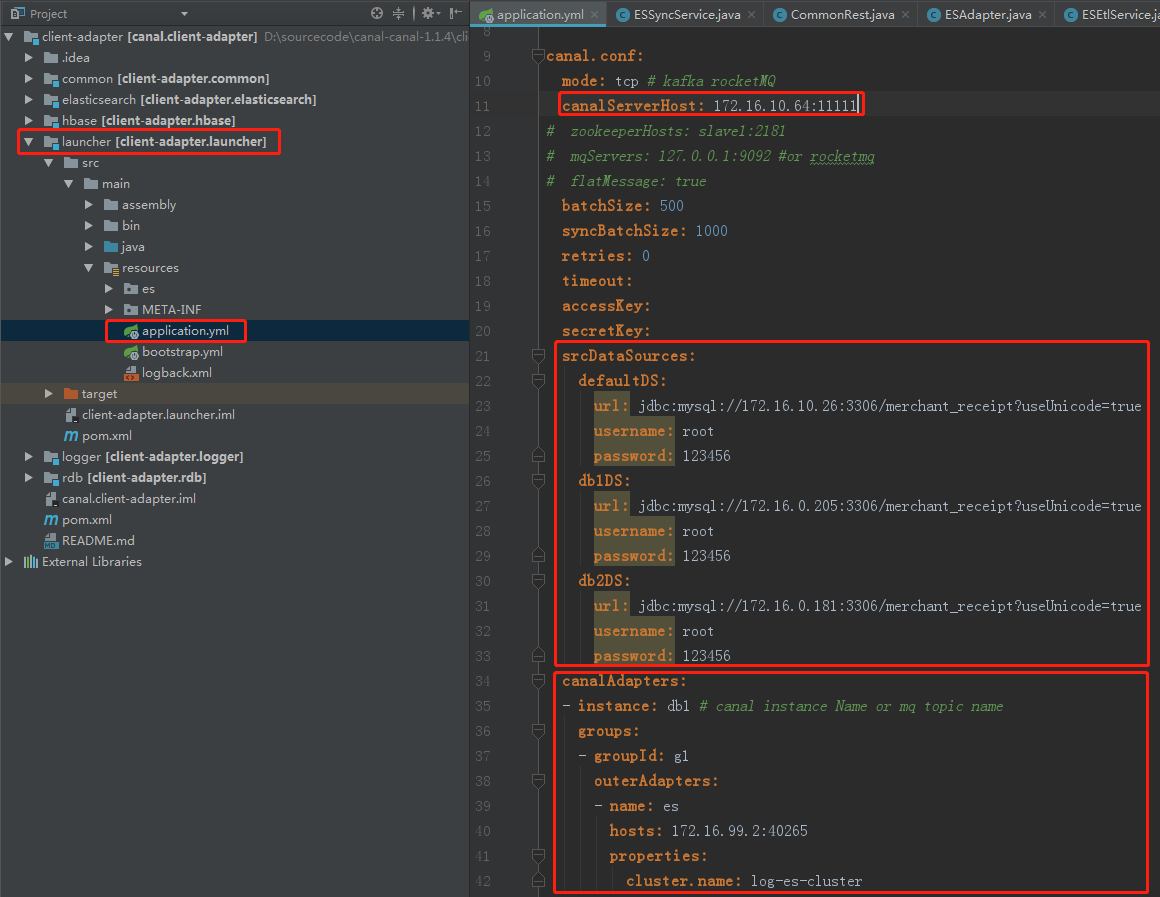
es adapter配置
在launcher项目中的配置文件下创建es目录并加入所需要同步的配置文件

三、运行调试
配置完毕后,直接运行launcher这个springBoot项目即可,也就是运行CanalAdapterApplication这个类就可以了。

当看日志提示启动成功后就代表启动成功了!
四、测试验证
增量同步测试跟canal-adapter安装包部署运行一样,这里主要介绍及测试一下条件同步和全量同步功能,即etl功能。
launcher项目是一个spring boot项目,在其中的rest包下有一个controller类(CommonRest.java),里面提供了一些接口,其中一个用于全量同步数据的接口

canal全量同步
我们按照注释的内容发送一个http请求即可:

canal_db1.yml为es目录下的配置文件,运行后出现以下提示信息,就可以让canal_db1.yml配置的数据表的所有数据全同步到es中了

在kibana中查看数据是否已经生成:

canal条件同步
如果想执行从某一个时刻的数据同步,在上面的测试URL后加上对应的参数就可以了

其参数由es的配置项决定的,以下截图的配置文件中的etlCondition:

五、修改源码
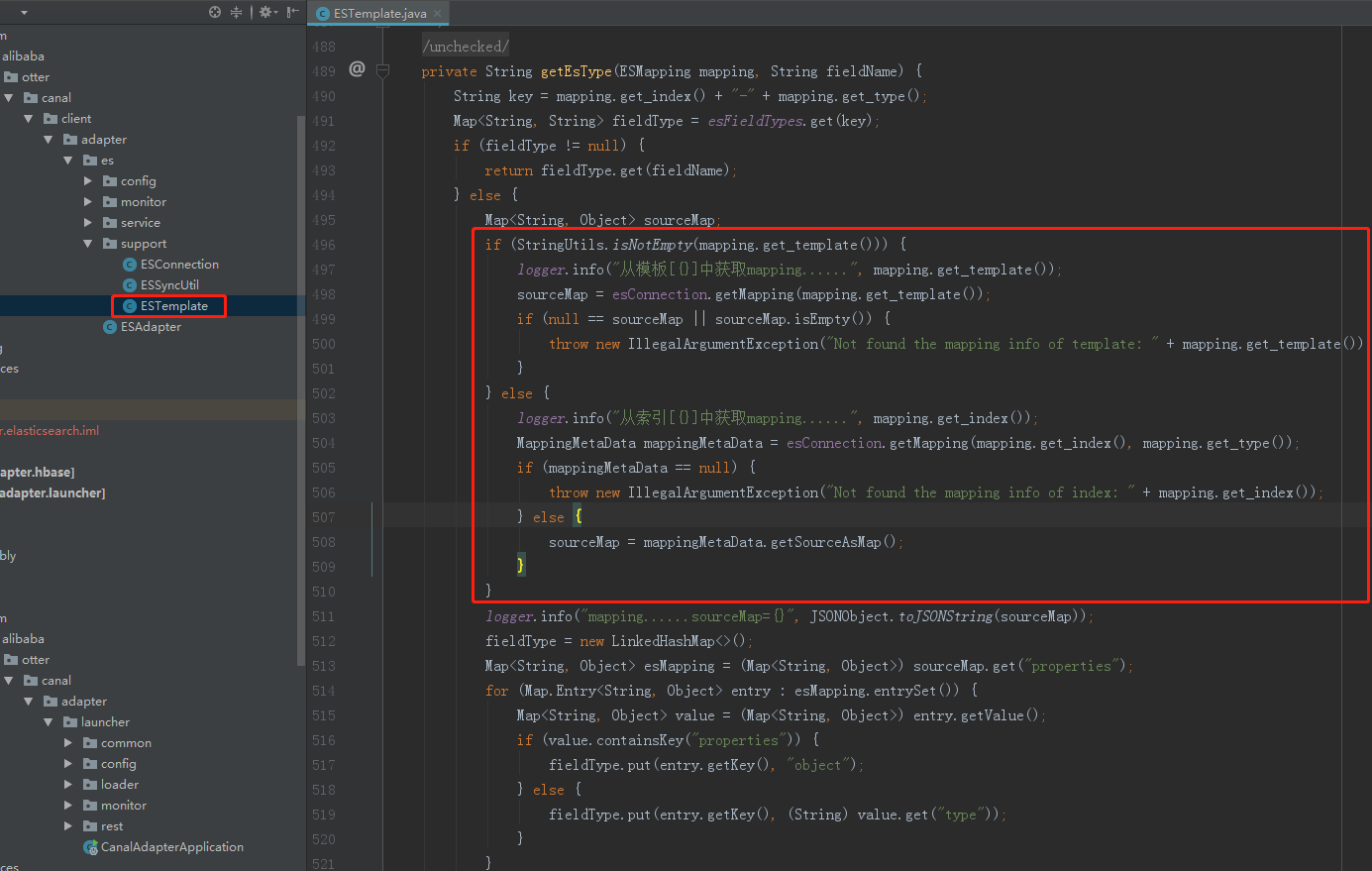
以下代码增加了从索引模板中获取mapping的处理逻辑:
重新编译打包:
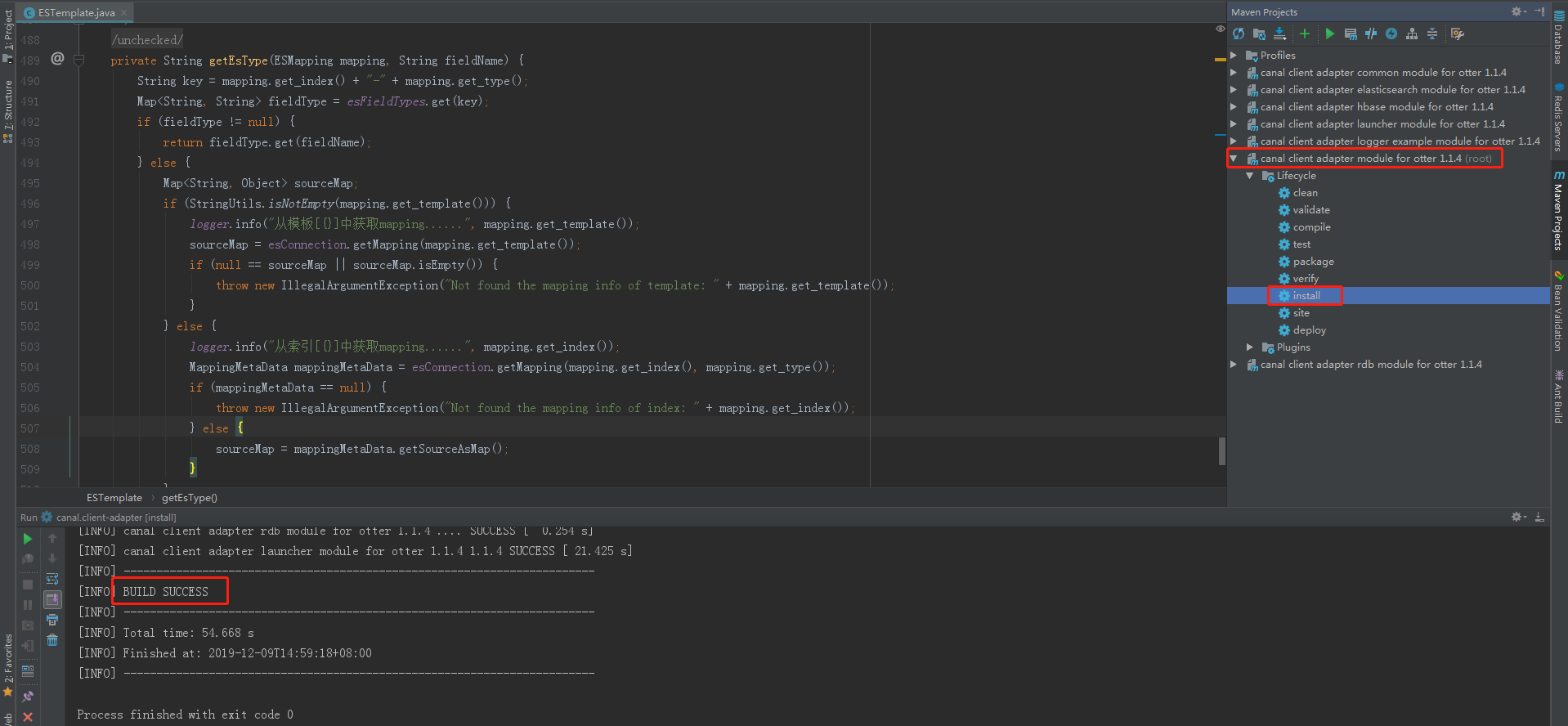
在项目的target目录下,会生成编译后的包,我这里修改的是es相关的,路径如下:

更新到canal-adapter的plugin目录下,重新服务就可以了。

Canal——Canal-Adapter源码在IDEA部署运行的更多相关文章
- Spark1.0.0 源码编译和部署包生成
问题导读:1.如何对Spark1.0.0源码编译?2.如何生成Spark1.0的部署包?3.如何获取包资源? Spark1.0.0的源码编译和部署包生成,其本质只有两种:Maven和SBT,只不过针对 ...
- 01.LNMP架构-Nginx源码包编译部署详细步骤
操作系统:CentOS_Server_7.5_x64_1804.iso 部署组件:Pcre+Zlib+Openssl+Nginx 操作步骤: 一.创建目录 [root@localhost ~]# mk ...
- 02.LNMP架构-MySQL源码包编译部署详细步骤
操作系统:CentOS_Server_7.5_x64_1804.iso 部署组件:Cmake+Boost+MySQL 操作步骤: 一.安装依赖组件 [root@localhost ~]# yum -y ...
- Appium Server 源码分析之启动运行Express http服务器
通过上一个系列Appium Android Bootstrap源码分析我们了解到了appium在安卓目标机器上是如何通过bootstrap这个服务来接收appium从pc端发送过来的命令,并最终使用u ...
- 单点登录(三)-----实战-----cas server 源码下载和部署
我们在上一篇文章中使用的是4.0版本的cas,4.0版本的有发布好的war包可以直接使用,那如果我们要使用更新的版本怎么办呢? 就需要下载源码自己编辑打包了. 步骤如下: 版本选择 我们在cas的gi ...
- MHA源码分析——环境部署
为了更好地了解MHA的原理,计划对MHA源码进行详细的阅读,本文主要为部署源码阅读环境. 一.概述 mha是由perl语言开发,这里想通过eclipse+perl组件来阅读其源码,所以我们环境需要安装 ...
- 如何让spring源码正常的部署在idea中
我在这里把我从GitHub下载的源码成功编译之后的文件放在了我的百度网盘上大家可以直接下载,也可以按如下步骤自己编译部署到idea中, 下载的地址是:http://pan.baidu.com/s/1d ...
- Hadoop 修改源码以及将修改后的源码应用到部署好的Hadoop中
我的Hadoop版本是hadoop-2.7.3, 我们可以去hadoop官网下载源码hadoop-2.7.3-src,以及编译好的工程文件hadoop-2.7.3, 后者可以直接部署. 前者hadoo ...
- Apollo源码打包及部署
1. 通过源码打包 到携程Apollo地址 https://github.com/ctripcorp/apollo 下载Apollo源码,可在源码中进行自定义配置日志路径及端口等,之后打包. 打包完成 ...
随机推荐
- 一、XML DOM、XMLDocument
一.XML DOM概述 XML 文档大小写敏感.属性用引号括起来,每一个标记都要闭合. DOM是XML文档的内存中树状的表示形式. 继承关系图: XmlNode;//XML节点 ......XmlDo ...
- Mybatis-Generator逆向工程,复杂策略(Criteria拼接条件)
基于上一篇修改 1.Generator配置文件修改,将targetRuntime改为MyBatis3 2.项目结构目录 这个xxxExample就是拼接条件用的 3.测试代码 注释写的很详细 publ ...
- Mybatis配置文件中#{ }和${ }的区别
#{ }和${ }都可以从map中取到相对应的值, 但是 #{ }采取的是预编译的方式(PreparedStatement)来执行sql语句,有效防止了sql注入问题 select * from bo ...
- nginx动静分离配置
动静分离: 所谓动静分离指的是当访问静态资源时,路由到一台静态资源服务器,当访问是非静态资源时,路由到另外一台服务器 静态资源配置: 如配置如下location 表示url为 /static/*.x ...
- 40 | insert语句的锁为什么这么多?
在上一篇文章中,我提到 MySQL 对自增主键锁做了优化,尽量在申请到自增 id 以后,就释放自增锁. 因此,insert 语句是一个很轻量的操作.不过,这个结论对于“普通的 insert 语句”才有 ...
- AtCoder Beginner Contest 133
目录 Contest Info Solutions A. T or T B.Good Distance C. Remainder Minimization 2019 D. Rain Flows int ...
- C++标准库分析总结(四)——<Vector、Array、Forward_list设计原则>
本节主要总结标准库Vector和Array的设计方法和特性以及相关迭代器内部特征 1.Vector 1.1 Vector 内部实现 Vector是自增长的数组,其实在标准库中没有任何一种容器能原地扩充 ...
- create an oauth app
github可以对自己的服务进行oauth认证,创建oauth认证的方式如下: github -> Settings -> Developer settings -> Develop ...
- [Shell]CVE-2019-0708漏洞复现及修复补丁
0x01 漏洞原理 Windows系列服务器于2019年5月15号,被爆出高危漏洞,该漏洞影响范围较广,windows2003.windows2008.windows2008 R2.windows 7 ...
- redis5种数据结构讲解及使用场景
string list hash set zset 探究 Redis 4 的 stream 类型 redis提供了5中数据结构,理解每种数据结构的特点对于redis开发运维非常重要. 一.字符 ...