kafka核心原理总结
新霸哥发现在新的技术发展时代,消息中间件也越来越受重视,很多的企业在招聘的过程中着重强调能够熟练使用消息中间件,所有做为一个软件开发爱好者,新霸哥在此提醒广大的软件开发朋友有时间多学习。
消息中间件利用高效可靠的消息传递机制进行平台无关的数据交流。关于消息中间件的一下介绍就介绍到这里了,感兴趣的可以继续了解,下面新霸哥将和大家介绍一下kafka的一下相关知识。
kafka已经被很多的中小公司使用,消息发送接受,有用过的朋友可能就很清楚了,kafka是一个支持分区的、分布式、多副本的,是一个基于zookeeper协调的分布式消息系统,我们看中的就是其中的一个最大的特性就是可以实时的处理大量数据以满足各种需求场景。
kafka核心特性
高效性设计是其优于其他消息中间件的一个主要特性,还有一个重要特性就是消息可靠性,能够对消息集合压缩,还有备份机制。能够支持上千个客户端同时读写,kafka集群支持热扩展。
kafka核心组件
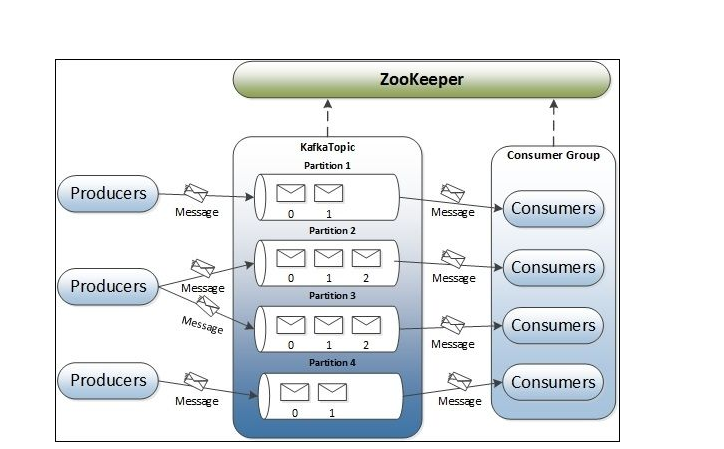
(1)replication(副本)、partition(分区)
一个topic能有非常多个副本,如果服务器配置足够好,可以配很多个,副本的个数决定了有多少个broker存放写入的数据;简单的来说副本是以partition为单位的,
存放副本也可以这样简单的理解,备份若干个partition、但是只能有一个partition被选为Leader用于读写。在这里新霸哥提醒刚入门的朋友partition(分区)
数量设置最好大于consumer数量,其实,这样设计的思想就是保证每个消费者都有一个partition。
(2)producer(生产者)
kafka中的producer能直接发送消息到Leader的 partition,可以看出producer能决定将消息推送到哪些partition。
也能使用批处理(Batch)推送消息,提高效率。在这里新霸哥给大家一个重要的提示那就是这里有一个重要的参数acks(0、-1、1)
(3)consumer(消费者)
kafka中的同一个group的consumer不可以同时消费同一个partition,对于同一个group的consumer,
kafka就可以认为是一个队列消息服务,各个consumer均衡的消费相应partition中的数据,有些时候会遇到当消费者数大于分区数时,
一般会出现leader consumer和follower consumer,leader consumer处理所有的读写请求,
特殊情况下leader consumer挂掉时,follower consumer会成为新的leader consumer。
kafka的一些核心原理技术就先介绍到这里了,更多的关于Kakfa的设计思想的一些相关的技术,新霸哥后面会继续放出。
kafka核心原理总结的更多相关文章
- 深入理解Kafka核心设计及原理(三):消费者
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16114877.html 深入理解Kafka核心设计及原理(一):初识Kafka 深入理解Kafka核心设计及原 ...
- 深入理解Kafka核心设计及原理(四):主题管理
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16124354.html 目录: 4.1创建主题 4.2 优先副本的选举 4.3 分区重分配 4.4 如何选择合 ...
- 深入理解Kafka核心设计及原理(五):消息存储
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16127749.html 目录: 5.1文件目录布局 5.2消息压缩 5.3日志索引 5.4日志文件及索引文件分 ...
- 高性能消息队列 CKafka 核心原理介绍(上)
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:闫燕飞 1.背景 Ckafka是基础架构部开发的高性能.高可用消息中间件,其主要用于消息传输.网站活动追踪.运营监控.日志聚合.流式 ...
- kafka系列四、kafka架构原理、高可靠性存储分析及配置优化
一.概述 Kakfa起初是由LinkedIn公司开发的一个分布式的消息系统,后成为Apache的一部分,它使用Scala编写,以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cl ...
- Kafka到底有几个Offset?——Kafka核心之偏移量机制
Kafka是由LinkIn开源的实时数据处理框架,目前已经更新到2.3版本.不同于一般的消息中间件,Kafka通过数据持久化和磁盘读写获得了极高的吞吐量,并可以不依赖Storm,SparkStre ...
- Kafka详细原理
Kafka Kafka是最初由Linkedin公司开发,是一个分布式.支持分区的(partition).多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实 ...
- 新书介绍 -- 《Redis核心原理与实践》
大家好,今天给大家介绍一下我的新书 -- <Redis核心原理与实践>. 后端开发的同学应该对Redis都不陌生,Redis由于性能极高.功能强大,已成为业界非常流行的内存数据库. < ...
- 【算法】(查找你附近的人) GeoHash核心原理解析及代码实现
本文地址 原文地址 分享提纲: 0. 引子 1. 感性认识GeoHash 2. GeoHash算法的步骤 3. GeoHash Base32编码长度与精度 4. GeoHash算法 5. 使用注意点( ...
随机推荐
- C++中的to_string()
目录 C++中的to_string() 注:原创不易,转载请务必注明原作者和出处,感谢支持! C++中的to_string() C++中的 to_string()系列函数将数值转换成字符串形式.注意, ...
- LC 655. Print Binary Tree
Print a binary tree in an m*n 2D string array following these rules: The row number m should be equa ...
- IIS asp.net 中出现未能加载文件或程序集“System.Core, Version=3.5.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089”或它的某一个依赖项。系统找不到指定的文件。
分析器错误消息: 未能加载文件或程序集“System.Core, Version=3.5.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089”或 ...
- debian中安装pip
sudo apt upate sudo apt-get install python3-pip
- Ajax操作的四个步骤
Ajax操作的四个步骤: 创建Ajax对象 连接服务器 发送请求 接收返回信息 <!DOCTYPE html> <html> <head lang="en&qu ...
- JS事件中级 --- 拖拽
http://bbs.zhinengshe.com/thread-1200-1-1.html 要求:实现div块的拖拽 原理:拖拽过程中鼠标点和div块的相对位置保持不变. 需要理解三点: 1. 为什 ...
- systemctl stop 列表
root@devstack2019:/etc/keystone# systemctl stop Display all 201 possibilities? (y or n)accounts-daem ...
- 强大的BeautifulSoup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库·它能够通过你喜欢的转换器实现惯用的文档导航 安装BeautifulSoup 推荐使用Beautiful Sou ...
- 在pythonanywhere.com免费网站建立虚拟机环境以及django网站
注册,添加App,选择python3.5,然后打开控制台 搭建python3.5虚拟环境 python --version virtualenv -p /usr/bin/python3.5 VENV ...
- PTA --- Basic Level 1009 说反话
1009 说反话 (20 point(s)) 给定一句英语,要求你编写程序,将句中所有单词的顺序颠倒输出. 输入格式: 测试输入包含一个测试用例,在一行内给出总长度不超过 80 的字符串.字符串由 ...