01篇ELK日志系统——升级版集群之elasticsearch集群的搭建
【
前言:以前搭了个简单的ELK日志系统,以我个人的感觉来说,ELK日志系统还是非常好用的。以前没有弄这个ELK日志系统的时候,线上的项目出了bug,报错了,要定位错误是什么,错误出现在哪个java代码文件里,每次都要在服务器上使用linux命令打开日志文件查看错误,简直繁琐无比。
搭了这个ELK日志系统之后,项目中的所有日志打印都发送到了ELK里面,然后通过ELK中的kibana视图界面 搜索 或 查看 各个时间段的日志,以及什么级别的日志,巨方便。
当然上次搭建的ELK日志系统只是个简单的,今天打算把消息中间件kafka整合到ELK日志系统里。
》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》
目前还是借鉴这位老哥的博客,搭建一个高并发场景的ELK日志系统:https://blog.csdn.net/qq_22211217/article/details/80764568,最后搭建高并发ELK日志系统流程图如下:

】
1、先说说整个ELK日志系统的流程

2、开始搭建ELK日志系统
2.1、准备工作:
先准备3台机器:我的分别如下:
192.168.2.115
192.168.2.116
192.168.2.119
- 3台机器上都要配置jdk环境,因为elasticsearch是java开发的
- 3台机器上也全要安装elasticsearch,因为现在要搭建elasticsearch分布式集群,所以3台机器都要装
- 我用192.168.2.119作es的主节点,192.168.2.115、192.168.2.116作为数据节点
- 在主节点上安装kibana,192.168.2.115上安装logstash
ELK使用的版本:elk所有安装包都在官网下载到
3、ELK日志系统第一步:安装elasticsearch
3.1、目前我把elasticsearch-6.4.2.tar.gz安装包都放在三台机器的/usr/local/dev/es目录下,并解压

3.2、开始配置elasticsearch集群
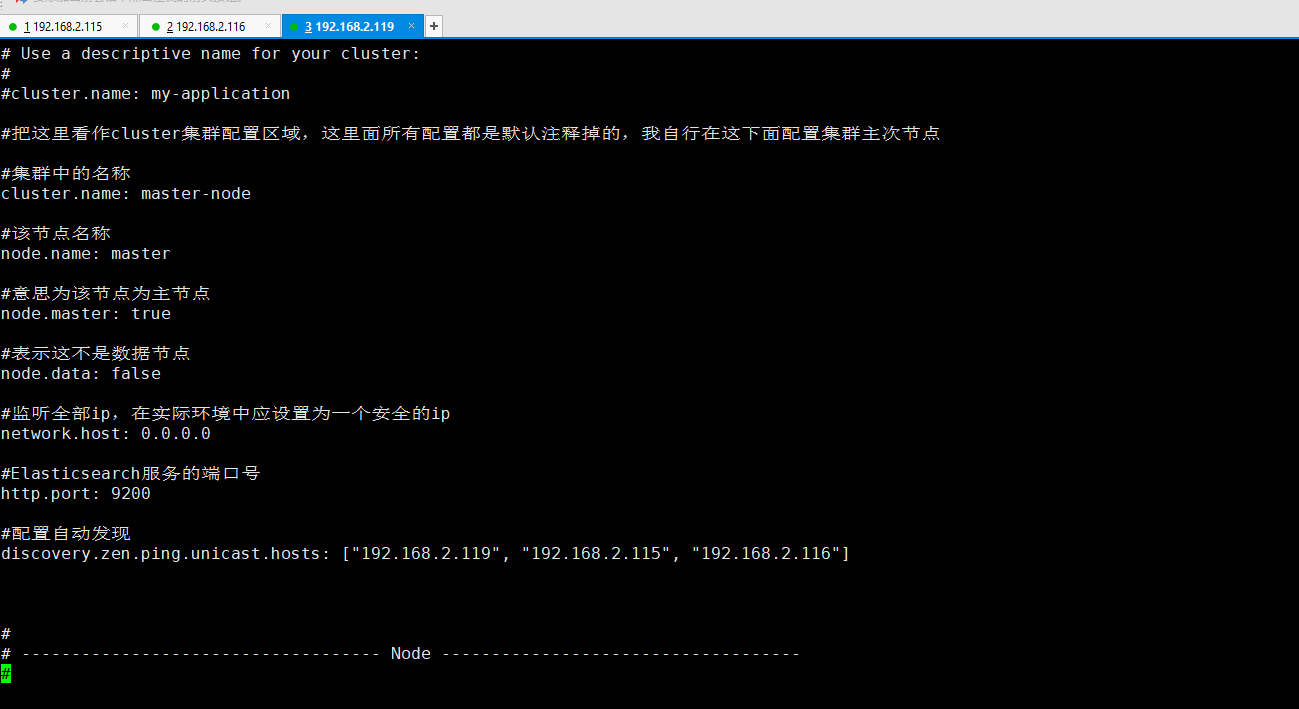
3.2.1、配置192.168.2.119主节点上的elasticsearch配置文件
#打开elasticsearch的配置文件
vi elasticsearch-6.4.2/config/elasticsearch.yml
配置内容如下:
#集群中的名称
cluster.name: master-node #该节点名称
node.name: master #意思为该节点为主节点
node.master: true #表示这不是数据节点
node.data: false #监听全部ip,在实际环境中应设置为一个安全的ip
network.host: 0.0.0.0 #Elasticsearch服务的端口号
http.port: #配置自动发现
discovery.zen.ping.unicast.hosts: ["192.168.2.119", "192.168.2.115", "192.168.2.116"]
192.168.2.119服务器主节点上的elasticsearch配置文件效果图:
3.2.2、配置192.168.2.115与192.168.2.116节点上的elasticsearch配置内容(大致相同,只是改下当前节点名称):
#集群中的名称
cluster.name: master-node
#该节点名称(115服务器为data-node1,116服务器为data-node2)
node.name: data-node1
#意思为该节点为主节点
node.master: false
#表示这不是数据节点
node.data: true
#监听全部ip,在实际环境中应设置为一个安全的ip
network.host: 0.0.0.0
#Elasticsearch服务的端口号
http.port: 9200
#配置自动发现
discovery.zen.ping.unicast.hosts: ["192.168.2.119", "192.168.2.115", "192.168.2.116"]
3.2、3台服务器的elasticsearch都配置好了,现在来启动一下主节点192.168.2.119上的elasticsearch:
#启动命令
./elasticsearch-6.4./bin/elasticsearch
啊哦,启动报错!!!!!!!!!!!!》》》》》》出现第一个报错》》》》》》》》》》》》》》》》》》》》》》
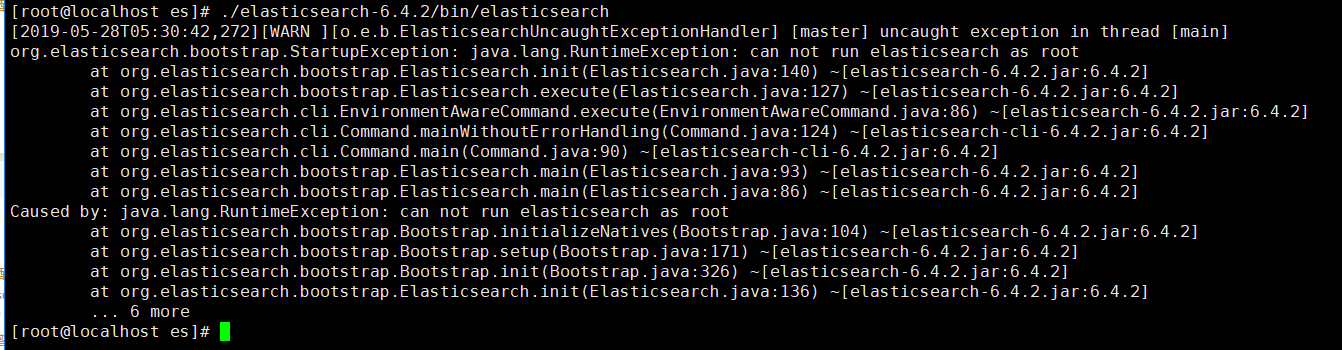
报错的原因:就是必须要再创建一个用户去操作elasticsearch,不能直接用root用户操作。
这位老哥的博客收集了很多elasticsearch报错解决的办法:https://blog.csdn.net/qq_22211217/article/details/80740873
第一个错误操作解决如下:
#创建一个用户组叫elsearch
groupadd elsearch #添加一个用户叫elsearch,并把此用户添加到elsearch用户组下,密码为123456
useradd elsearch -g elsearch -p 123456 #将elsearch的安装目录elasticsearch-6.4.2 授权给用户组(elsearch):用户(elsearch)
chown -R elsearch:elsearch elasticsearch-6.4.2 #切换使用elsearch用户
su elsearch #重新启动
./elasticsearch-6.4.2/bin/elasticsearch
》》》》》》出现第二个报错》》》》》》》》》》》》》》》》》》》》》》
重新启动,再次报错,出现了上面老哥博客里错误收集的第四条:bootstrap checks failed
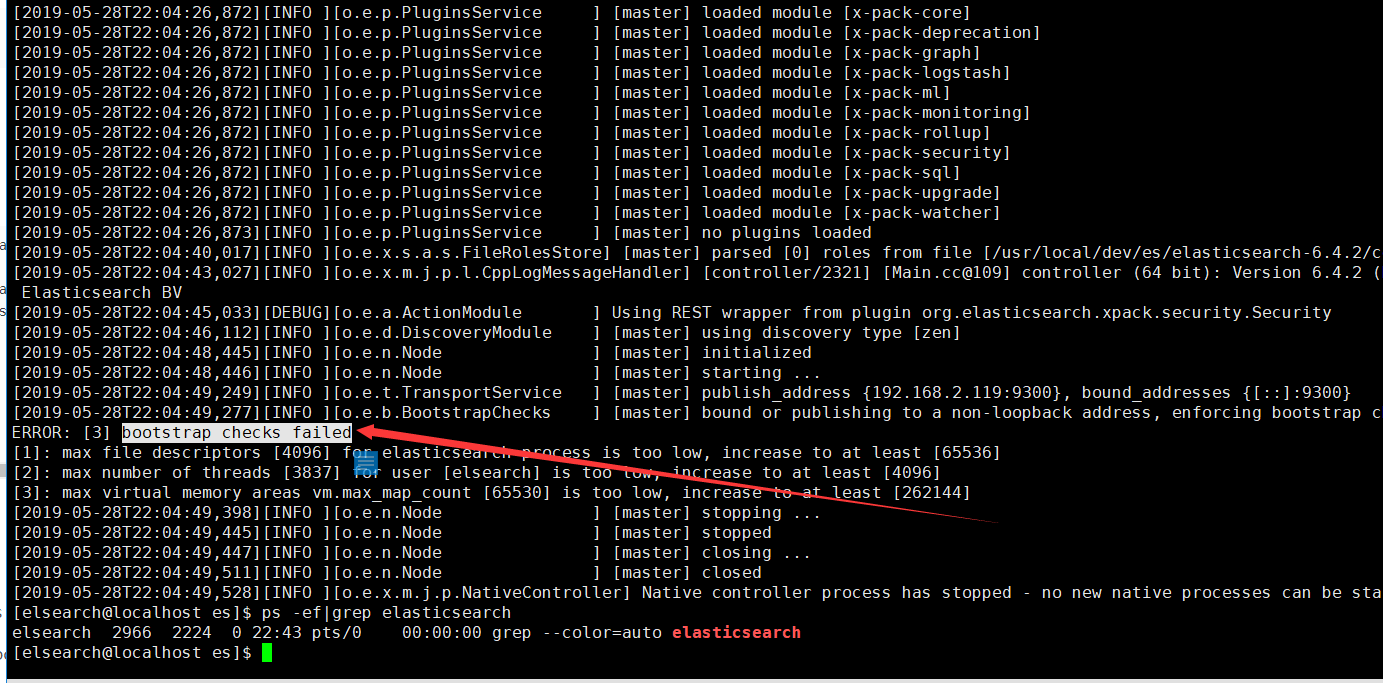
原因:虚拟机限制用户的执行内存
第二个错误解决办法操作如下:
#切换root用户
su root #打开limits.conf文件
vi /etc/security/limit.conf #在文件末尾加入以下配置
elsearch hard nofile 65536
elsearch soft nofile 65536
* soft nproc 4096
* hard nproc 4096
#保存退出后,再打开sysctl.conf配置文件
vi /etc/sysctl.conf #在行末加上vm.max_map_count = 655360 ,esc +:wq保存退出
vm.max_map_count = 655360 #保存之后,执行一下sysctl -p (被那位老哥的博客坑了一下,他收集的错误解决里没有这一条步骤:sysctl -p)
sysctl -p #切换回elsearch用户
su elsearch #重启elasticsearch
./elasticsearch
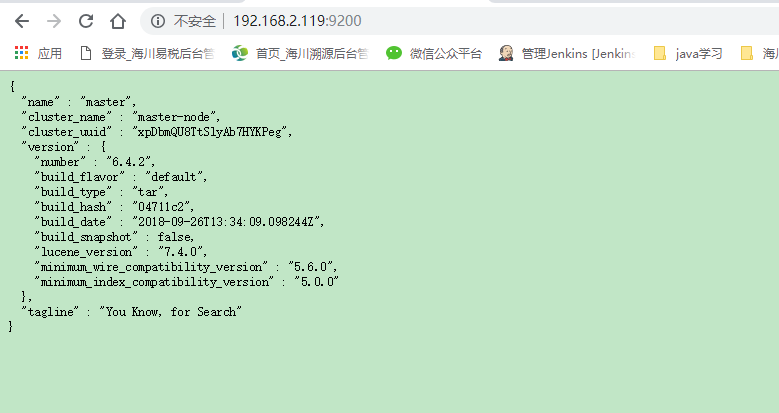
搞定啦!!!!!elasticsearch启动成功如下:浏览器打开服务器 ip:9200端口,显示出下面这个就是成功了。
下面依次启动192.168.2.115和192.168.2.116服务器上的elasticsearch,如有报错和上面错误一、错误二解决办法一样
(重点,启动elasticsearch,要用刚刚创建的elsearch用户操作,用root用户操作会失败)
》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》》
4、192.168.2.115、192.168.2.116、192.168.2.119三台服务器上的elasticsearch都配置好了,准备启动elasticsearch集群:
改变elasticsearch的启动方式,不再使用文件启动,并配置elasticsearch开机自启
借鉴博客:https://blog.csdn.net/whg18526080015/article/details/73737546
#使用service elasticsearch start 命令来启动elasticsearch服务
cd /etc/init.d
touch elasticsearch
chmod +x elasticsearch #打开elasticsearch
vi elasticsearch #输入以下配置内容:
》》》》》》》》》》》》》》》》》》》》》》》》》》》
#!bin/bash
# chkconfig: 2345 21 89
# description: elasticsearch
# JAVA_HOME=/usr/local/dev/java/jdk1.8.0_141
ES_HOME=/usr/local/dev/es/elasticsearch-6.4.2
case $1 in
start) sudo -iu elsearch $ES_HOME/bin/elasticsearch &;;
*) echo "require start" ;;
esac
》》》》》》》》》》》》》》》》》》》》》》》》》》》 #备注一下:sudo -iu elsearch 这里是指定一下elsearch用户权限 #然后就可以用service elasticsearch start 启动es服务了
4.1使用service elasticsearch start命令启动成功如下:

其他两台服务器的配置service elasticsearch start启动命令配置也是如此,不再演示。
把三台服务器上的elasticsearch服务全部启动
注意:119服务器上的elasticsearch主节点服务用service elasticsearch start命令启动后,运行日志是实时打印的,刚才启动了115服务器上的elasticsearch次节点服务,119服务器这边马上就发现了并打印了接入115服务器次节点的事件日志,如下:

直接按Ctrl+C退出当前就行了。
115服务器上的elasticsearch节点服务启动成功
116服务器上的elasticsearch节点服务启动失败,遇见一个报错(绑定节点失败):failed to obtain node locks
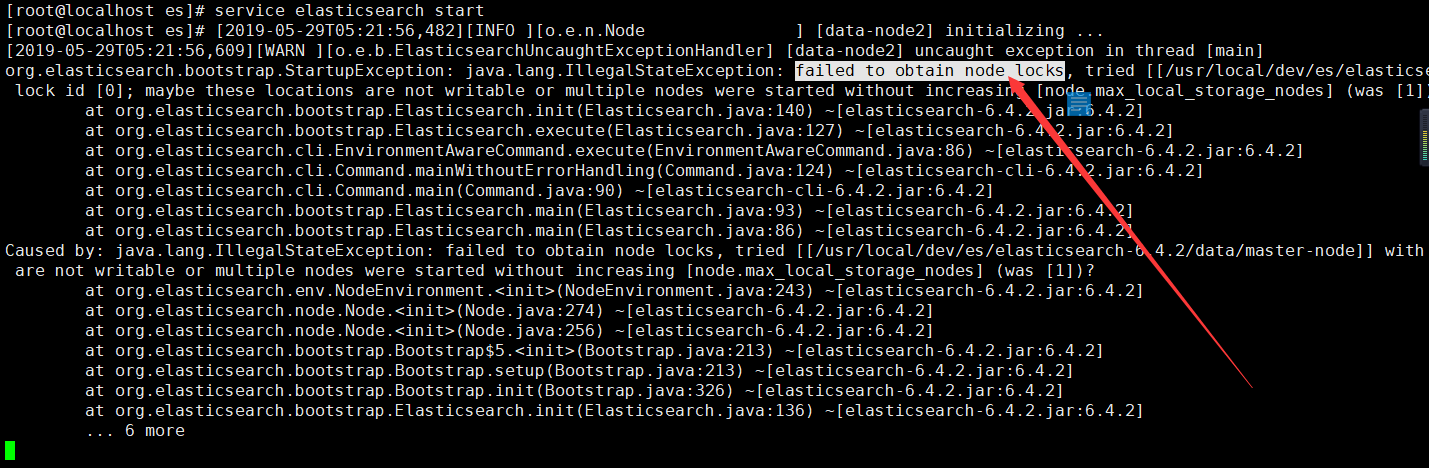
原因可能是116服务器上还启着elasticsearch的服务,查看一下,把它关闭,重启。解决如下:

116服务器上的elasticsearch服务启动成功,并且119主服务器上接收到116服务器上的elasticsearch启动响应日志:

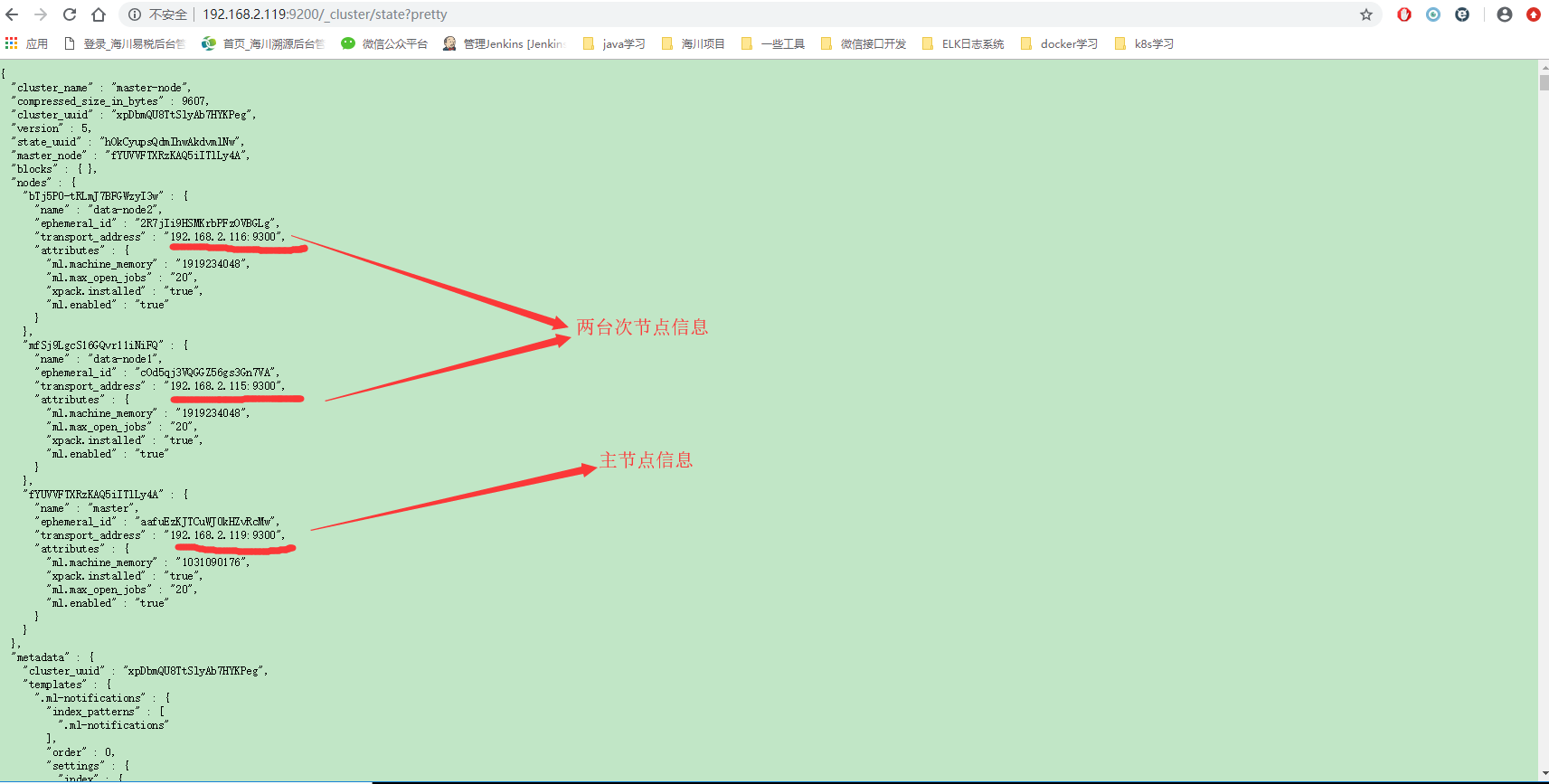
到此为止,三台服务器上的elasticsearch服务都启动成功,在浏览器上输入地址 192.168.2.119:9200/_cluster/state?pretty 查看如下:
下一篇把elasticsearch集群整合kibna、logstash、kafka
放牛咯!
01篇ELK日志系统——升级版集群之elasticsearch集群的搭建的更多相关文章
- 02篇ELK日志系统——升级版集群之kibana和logstash的搭建整合
[ 前言:01篇LK日志系统已经把es集群搭建好了,接下来02篇搭建kibana和logstash,并整合完成整个ELK日志系统的初步搭建. ] 1.安装kibana 3台服务器: 192.168.2 ...
- 03篇ELK日志系统——升级版集群之ELK日志系统整合springboot项目
[ 前言:整个ELK日志系统已经搭建好了,接下来的流程就是: springboot项目中的logback日志配置通过tcp传输,把springboot项目中所有日志数据传到————>logsta ...
- 创业公司做数据分析(四)ELK日志系统
作为系列文章的第四篇.本文将重点探讨数据採集层中的ELK日志系统.日志.指的是后台服务中产生的log信息,一般会输入到不同的文件里.比方Django服务下,一般会有nginx日志和uWSGI日志. ...
- 创业公司做数据分析(四)ELK日志系统 (转)
http://blog.csdn.net/zwgdft/article/details/53842574 作为系列文章的第四篇,本文将重点探讨数据采集层中的ELK日志系统.日志,指的是后台服务中产生的 ...
- ELK日志系统之通用应用程序日志接入方案
前边有两篇ELK的文章分别介绍了MySQL慢日志收集和Nginx访问日志收集,那么各种不同类型应用程序的日志该如何方便的进行收集呢?且看本文我们是如何高效处理这个问题的 日志规范 规范的日志存放路径和 ...
- 【7.1.1】ELK日志系统单体搭建
ELK是什么? 一般来说,为了提高服务可用性,服务器需要部署多个实例,每个实例都是负载均衡转发的后的,如果还用老办法登录服务器去tail -f xxx.log,有很大可能错误日志未出现在当前服务器中, ...
- ELK日志系统:Elasticsearch+Logstash+Kibana+Filebeat搭建教程
ELK日志系统:Elasticsearch + Logstash + Kibana 搭建教程 系统架构 安装配置JDK环境 JDK安装(不能安装JRE) JDK下载地址:http://www.orac ...
- Centos6.7 ELK日志系统部署
Centos6.7 ELK日志系统部署 原文地址:http://www.cnblogs.com/caoguo/p/4991602.html 一. 环境 elk服务器:192.168.55.134 lo ...
- ELK日志系统之kibana的使用操作
1.ELK日志系统打开后,打开kibana的操作界面,第一步创建索引模式: 第2步:创建日志索引 第3步:创建成功 第4步:查看30分钟时间段内的日志数据,也可以查今天的,今月的,今年的 放牛去
随机推荐
- angular 学习记录
3章3小结 路由传参的3种方式和路由快照,订阅, @相同路由的跳转(只是参数不同),并不会触发Oninit ,因为没有重新创建component @子路由 //此种情况 是当我路由地址是 ../Hom ...
- 树莓派跑yolo
https://blog.csdn.net/u011304078/article/details/85772764 https://blog.csdn.net/weixin_41665225/arti ...
- linux-部署1
0.python安装 ubuntu16.04默认:安装了python2.7和python3.5: Ubuntu18.04默认:只有python3.6.8 下面是针对16.04: python/pyth ...
- 1-开发共享版APP(搭建指南)-快速搭建到自己的服务器
该APP安装包下载链接: http://www.mnif.cn/appapk/IotDevelopmentVersion/20190820/app-debug.apk 或者扫描二维码下载 注:该下载可 ...
- options模块介绍
一. options是什么? 是tornado中为我们提供好的一个模块. 二. options的作用? 用来定义, 存储, 转换全局参数. 即定义变量 三. options如何使用? import t ...
- requests--重定向,序列化
重定向 默认情况下,除了 HEAD, Requests 会自动处理所有重定向.可以使用响应对象的 history 方法来追踪重定向. Response.history 是一个 Response 对象的 ...
- vijos2054 SDOI2019 热闹的聚会与尴尬的聚会
题目链接 思路 首先观察题目最后的式子\(\lfloor \frac{n}{p + 1} \rfloor \le q\) 并且\(\lfloor \frac{n}{q+1} \rfloor \le p ...
- [LeetCode] 19. Remove Nth Node From End of List 移除链表倒数第N个节点
Given a linked list, remove the nth node from the end of list and return its head. For example, Give ...
- win10安装docker并结合Idea2018.1部署springboot项目
一.准备工作 1..工具:win10,idea2018,maven3.5,jdk8 二.win10安装docker 1.win10安装docker:http://www.runoob.com/dock ...
- 热情组——项目冲刺 Day3
项目相关 作业相关 具体描述 班级 班级链接 作业要求 链接地址 团队名称 热情组 作业目标 实现软件制作,以及在福大的传播 Github链接 链接地址 SCRUM部分: 成员昵称 昨日目标 开始时间 ...