HDFS- High Availability
NameNode High Availability
Background
Hadoop2.0.0之前,NameNode存在单点失败(single point of failure (SPOF) )问题(1、NameNode所在的机器挂了;2、NameNode所在的机器需要硬件或者软件上的更新维护)。
新的NameNode需要(1)将namespace image加载到内存(2)replay editlog(3)从datanodes接收到足够的block报告从而离开安全模式;才能重新开始服务。在包含大量文件和Blocks的大的集群中,namenode的冷启动可能需要30min或更久。
Architecture
NameNode HA包含两个NameNode,在任意一个时刻,只有一个NameNode是的状态是Active,另一个是NameNode的状态是Standby,此外还包含ZooKeeper Failover Controller(ZKFC)、ZooKeeper以及共享编辑日志(share edit log)。 Active NameNode负责所有客户端对集群的操作, Standby NameNode作为slave,维护状态信息以便在提供快速的故障转移。
实现HA的流程
(1)集群启动后,一个NameNode处于Active的状态,提供服务,处理客户端和DataNodes的请求,并把修改写到edit log,然后将edit log写到本地和共享编辑日志(NFS、QJM等)。
【共享编辑日志分两种,
1:如果是NFS,那么主、从NameNode访问NFS的一个目录或者共享存储设备,Active Node对namespace的修改记录到edit log中,然后将edit log存储到共享目录中。Standby NameNode将共享目录中的edit log 写到自己的namespace
2:如果是QJM,那么主、从NameNode与一组单独的称为Journal Nodes(JNs)的守护线程进行通信,Active Node将修改记录到大多数(> (N / 2) + 1,N是Journal Nodes的数量),Standby NameNode能够从JNs读到修改并写到自己的namespace中
】
(2)另外一个NameNode处于standby状态,它启动时加载Namespace Image文件,然后周期性地将共享编辑日志写到自己namespace,从而保持与Active NameNode的状态同步。在发生故障转移时,Standby节点需要确保自己已经从共享编辑日志读到了所有的edit log之后,才会变成Active节点。这保证了namespace状态的完全同步。
(3)为了实现Standby NameNode在Active NameNode失败之后能够快速提供服务,每个DataNode需要同时向两个NameNode发送块的位置信息和心跳【块报告(block report)】,因为NameNode启动最费时的工作就是处理所有DataNodes的块报告。为了实现热备,增加ZKFC和ZooKeeper,通过ZK选择主节点,Failover Controller通过RPC让NameNode转换为主或从。
(4)当Active NameNode失败时,Standby NameNode可以很快地接管,因为在Standby NameNode的内存中有最新的状态信息(1)最新的edit log(2)最新的block mapping
高可用的共享存储的两种选择:NFS和QJM
quorum journal manager(QJM)是HDFS专门的实现,唯一的目的就是提供高可用的edit log,是大多数HDFS的推荐选择。
QJM的工作过程:QJM运行一组journal nodes,每个edit必须被写入到majority的journal nodes中。通常,journal nodes的数量是3(至少是3个),因此每个edit必须被写入到至少两个journal nodes,允许一个journal nodes失败。【与ZooKeeper相似,但是QJM不是依赖ZooKeeper实现的】
使用 Fencing(隔离)来防止"split-brain"(脑裂)
Why Fencing?
slow network or a network partition可以触发故障转移,即使之前的Active NameNode仍让在正常运转并且认为它自己仍然是Active NameNode,这时HA就需要确保阻止这样的NameNode继续运行。
两种隔离
(1)通过隔离保证在同一时刻主NameNoel和从NameNode只有一个能够写 共享编辑日志
(2)DataNode隔离:对客户端进行隔离,要确保只有一个NameNode能够响应客户端的请求
对于HA集群来说,同一时刻只能有一个Active NameNode,否则namespace的状态很快就会发散成两个,造成数据丢失以及其他不正确的结果,即"split-brain"。为了防止这种情况发生,对于共享存储必须配置隔离(fencing)方法。在故障转移期间,如果不能判定之前的Active 节点放弃了他的Active状态,隔离处理负责切断切断之前的Active节点对共享编辑存储的访问,这就防止了之前Active节点对namespace的进一步编辑,从而使得新的Active节点能够安全地进行故障转移。(即一旦主NameNode失败,那么共享存储需要立即进行隔离,确保只有一个NameNode能够命令DataNodes。这样做之后,还需要对客户端进行隔离,要确保只有一个NameNode能够响应客户端的请求。让访问从节点的客户端直接失败,然后通过若干次的失败后尝试连接新的NameNode,对客户端的影响是增加一些重试时间,但对应用来说基本感觉不到。)
why QJM recommended?
QJM在同一个时刻只允许一个NameNode写edit log;然而,之前的Active NameNode仍有可能为客户端的旧的读请求服务,此时可以设置SSH fencing命令来杀死NameNode的进程。
由于NFS不可能在同一个时刻只允许一个NameNode向它写数据,因此NFS需要更强的fencing方法,包括:1、revoking the namenode’s access to the shared storage directory (typically by using a vendor-specific NFS command);2、disabling its network port via a remote management command;3、STONITH, or “shoot the other node in the head,” which uses a specialized power distribution unit to forcibly power down the host machine.
Failover Controller
从Active NameNode到Standby NameNode的转换通过Failover Controller实现。Hadoop的FC的默认实现是基于ZooKeeper的,从而确保只有一个Active NameNode。Failover Controller的作用是监控NameNode、操作系统、硬件的健康状态,如果出现NameNode的失败,则进行故障转移。
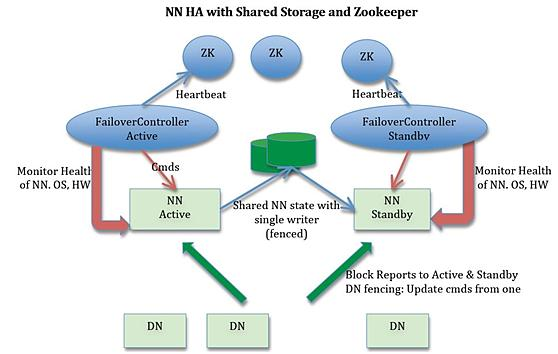
NOTE:HA集群中的Standby NameNode同时为namespace的状态执行检查点(HA上运行Secondary NameNode, CheckpointNode, or BackupNode是错误的)
参考:
(1)《Hadoop The Definitive Guide》
(2)http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HdfsUserGuide.html
HDFS- High Availability的更多相关文章
- HDFS Federation与HDFS High Availability详解
HDFS Federation NameNode在内存中保存文件系统中每个文件和每个数据块的引用关系,这意味着对于一个拥有大量文件的超大集群来说,内存将成为限制系统横向扩展的瓶颈.在2.0发行版本系列 ...
- [HDFS Manual] CH4 HDFS High Availability Using the Quorum Journal Manager
HDFS High Availability Using the Quorum Journal Manager HDFS High Availability Using the Quorum Jour ...
- Configuring HDFS High Availability
Configuring HDFS High Availability 原文请訪问 http://blog.csdn.net/ashic/article/details/47024617,突袭新闻小灵儿 ...
- HDFS High Availability(HA)高可用配置
高可用性(英语:high availability,缩写为 HA) IT术语,指系统无中断地执行其功能的能力,代表系统的可用性程度.是进行系统设计时的准则之一. 高可用性系统意味着系统服务可以更长时间 ...
- HDFS High Availability Using the Quorum Journal Manager
http://hadoop.apache.org/docs/r2.9.0/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.htm ...
- hadoop2.x HDFS HA linux环境搭建
HDFS High Availability Using the Quorum Journal Manager 准备3台机器可以更多 NN DN ZK ZKFC JN RM DM n ...
- hadoop 的HDFS 的 standby namenode无法启动事故处理
standby namenode无法启动 现象:线上使用的2.5.0-cdh5.3.2版本Hadoop,开启了了NameNode HA,HA采用QJM方式.hadoop的集群的namenode的sta ...
- HDFS NameNode HA 部署文档
简介: HDFS High Availability Using the Quorum Journal Manager Hadoop 2.x 中,HDFS 组件有三个角色:NameNode.DataN ...
- 第6章 HDFS HA配置
目录 6.1 hdfs-site.xml文件配置 6.2 core-site.xml文件配置 6.3 启动与测试 6.4 结合ZooKeeper进行自动故障转移 在Hadoop 2.0.0之前,一个H ...
- hadoop权威指南(第四版)要点翻译(4)——Chapter 3. The HDFS(1-4)
Filesystems that manage the storage across a network of machines are called distributed filesystems. ...
随机推荐
- 大数据 --> Kafka集群搭建
Kafka集群搭建 下面是以三台机器搭建为例,(扩展到4台以上一样,修改下配置文件即可) 1.下载kafka http://apache.fayea.com/kafka/0.9.0.1/ ,拷贝到三台 ...
- Algorithm --> 投资组和求最大利润
投资组和求最大利润 题目: 投资人出资一笔费用mount,投资给不同的公司(A,B,C....),求最大获取利润? 例如:投资400百万,给出两家公司A和B: 1.如果投资一百万给A公司,投资3百万给 ...
- JavaOOP-集合框架
1.Java集合框架包含的内容 Java集合框架为我们提供了一套性能优良,使用方便的接口和类,它们都位于在java.util包中. Collection 接口存储一组不唯一,无序的对象. List 接 ...
- Python中的threadlocal
在多线程中,对于共有的共享数据的操作,需要加锁. 但是,对于局部变量,则在每个线程之间相互独立. 假如线程T想要把函数F1中的局部变量V1传到函数F2中去,F2再想把这个变量传到F3中去,一层一层地传 ...
- Comparable接口和Comparator接口
1.一个类在设计之初就要实现对该类对象的排序功能,那么这个类要实现Comparable接口,实现public int compareTo(T t)方法.如代码中的Student类.对于实现Compar ...
- vue计算属性详解——小白速会
一.什么是计算属性 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的.在模板中放入太多的逻辑会让模板过重且难以维护.例如: <div id="example"> ...
- Bate版敏捷冲刺每日报告--day1
1 团队介绍 团队组成: PM:齐爽爽(258) 小组成员:马帅(248),何健(267),蔡凯峰(285) Git链接:https://github.com/WHUSE2017/C-team 2 ...
- fflush(stdin)与fflush(stdout)
1.fflush(stdin): 作用:清理标准输入流,把多余的未被保存的数据丢掉.. 如: int main() { int num; char str[10]; cin>>num; c ...
- vim配置之taglist插件安装
上次说了不带插件的vim配置,今天补充两个,来日方长,不定期更新: 首先看一个路径: 下载ctags,将其中的ctags.exe复制到上边目录下边: 地址:https://sourceforge.ne ...
- Flask 学习 四 数据库
class Role(db.Model): __tablename__='roles' id = db.Column(db.Integer,primary_key=True) name = db.Co ...