PoiDocxDemo【Android将表单数据生成Word文档的方案之二(基于Poi4.0.0),目前只能java生成】
版权声明:本文为HaiyuKing原创文章,转载请注明出处!
前言
这个是《PoiDemo【Android将表单数据生成Word文档的方案之二(基于Poi4.0.0)】》的扩展,上一篇是根据doc模板生成doc文件,这个是根据docx模板生成docx文件。
注意:目前只能java生成,集成到Android项目中,运行报错【暂时未解决】:
Process: com.why.project.poidocxdemo, PID: 13762
java.lang.NoClassDefFoundError: Failed resolution of: Ljavax/xml/stream/XMLEventFactory;
at org.apache.poi.openxml4j.opc.internal.marshallers.PackagePropertiesMarshaller.<clinit>(PackagePropertiesMarshaller.java:41)
at org.apache.poi.openxml4j.opc.OPCPackage.<init>(OPCPackage.java:140)
at org.apache.poi.openxml4j.opc.ZipPackage.<init>(ZipPackage.java:103)
at org.apache.poi.openxml4j.opc.OPCPackage.open(OPCPackage.java:298)
at org.apache.poi.ooxml.util.PackageHelper.open(PackageHelper.java:37)
at org.apache.poi.xwpf.usermodel.XWPFDocument.<init>(XWPFDocument.java:142)
前期准备
参考《PoiDemo【Android将表单数据生成Word文档的方案之二(基于Poi4.0.0)】》
区别在于,模板的占位有所不用【docx模板文件不需要$符号】:
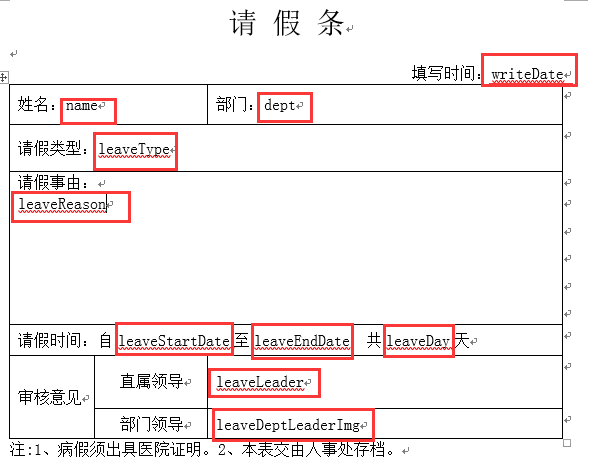
代码分析
参考《PoiDemo【Android将表单数据生成Word文档的方案之二(基于Poi4.0.0)】》
使用步骤
一、项目组织结构图

注意事项:
1、 导入类文件后需要change包名以及重新import R文件路径
2、 Values目录下的文件(strings.xml、dimens.xml、colors.xml等),如果项目中存在,则复制里面的内容,不要整个覆盖
二、导入步骤
1、将poi相关jar文件导入项目中【Demo采用的是module方式】
引用jar文件参考《【Android Studio安装部署系列】十七、Android studio引用第三方库、jar、so、arr文件》
注意:
解析docx文件,需要引用下面的jar文件:
- poi-4.0.0.jar
- poi-ooxml-4.0.0.jar
- poi-ooxml-schemas-4.0.0.jar
- ooxml-lib目录下的curvesapi-1.05.jar、xmlbeans-3.0.1.jar
- lib目录下的commons-collections4-4.2.jar
- 下载的commons-compress-1.18.jar
commons-compress-1.18.jar下载地址:http://commons.apache.org/proper/commons-compress/download_compress.cgi

2、将制作的模板文件复制到D:/temp目录下
3、将PoiUtils.java文件复制到项目中
package com.why.main; import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.apache.poi.xwpf.usermodel.XWPFRun;
import org.apache.poi.xwpf.usermodel.XWPFTable;
import org.apache.poi.xwpf.usermodel.XWPFTableCell;
import org.apache.poi.xwpf.usermodel.XWPFTableRow; import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map; public class PoiUtils { //测试
public static void main(String[] args) {
String templetDocPath = "D:/temp/请假单模板1.docx";
String targetDocPath = "D:/temp/请假单1.docx"; Map<String, Object> dataMap = new HashMap<String, Object>();
dataMap.put("writeDate", "2018年10月14日");
dataMap.put("name", "HaiyuKing");
dataMap.put("dept", "移动开发组");
dataMap.put("leaveType", "☑倒休 √年假 ✔事假 ☐病假 ☐婚假 ☐产假 ☐其他");
dataMap.put("leaveReason", "倒休一天。");
dataMap.put("leaveStartDate", "2018年10月14日上午");
dataMap.put("leaveEndDate", "2018年10月14日下午");
dataMap.put("leaveDay", "1");
dataMap.put("leaveLeader", "同意");
dataMap.put("leaveDeptLeaderImg", "同意!"); PoiUtils.writeToDocx(templetDocPath,targetDocPath,dataMap); try {
PoiUtils.readDocx(targetDocPath);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} /**
* 通过XWPFDocument对内容进行访问。对于XWPF文档而言,用这种方式进行读操作更佳。
* @throws Exception
*/
public static void readDocx(String templetDocPath) throws Exception {
InputStream is = new FileInputStream(templetDocPath);
XWPFDocument doc = new XWPFDocument(is);
List<XWPFParagraph> paras = doc.getParagraphs();
for (XWPFParagraph para : paras) {
//当前段落的属性
System.out.println("para=="+para.getText());
}
//获取文档中所有的表格
List<XWPFTable> tables = doc.getTables();
List<XWPFTableRow> rows;
List<XWPFTableCell> cells;
for (XWPFTable table : tables) {
//获取表格对应的行
rows = table.getRows();
for (XWPFTableRow row : rows) {
//获取行对应的单元格
cells = row.getTableCells();
for (XWPFTableCell cell : cells) {
System.out.println("cell=="+cell.getText());;
}
}
}
if (is != null) {
try {
is.close();
} catch (IOException e) {
e.printStackTrace();
}
}
} /**
* 生成一个docx文件
* @param templetDocPath 模板文件的完整路径
* @param targetDocPath 生成的目标文件的完整路径
* @param dataMap 替换的数据*/
public static void writeToDocx(String templetDocPath, String targetDocPath, Map<String,Object> dataMap){
try
{
//得到模板doc文件的HWPFDocument对象
InputStream in = new FileInputStream(templetDocPath);
writeToDocx(in,targetDocPath,dataMap);
}
catch(IOException e)
{
e.printStackTrace();
}
} /**
* 生成一个docx文件,主要用于直接读取asset目录下的模板文件,不用先复制到sd卡中
* @param templetDocInStream 模板文件的InputStream
* @param targetDocPath 生成的目标文件的完整路径
* @param dataMap 替换的数据*/
public static void writeToDocx(InputStream templetDocInStream, String targetDocPath, Map<String,Object> dataMap){
try
{
//得到模板doc文件的HWPFDocument对象
XWPFDocument HDocx = new XWPFDocument(templetDocInStream);
//替换段落里面的变量
replaceInPara(HDocx, dataMap);
//替换表格里面的变量
replaceInTable(HDocx, dataMap); //写到另一个文件中
OutputStream os = new FileOutputStream(targetDocPath);
//把doc输出到输出流中
HDocx.write(os);
os.close();
templetDocInStream.close();
}
catch(IOException e)
{
e.printStackTrace();
}
catch(Exception e)
{
e.printStackTrace();
}
} /**
* 替换段落里面的变量
* @param doc 要替换的文档
* @param params 参数
*/
private static void replaceInPara(XWPFDocument doc, Map<String, Object> params) {
Iterator<XWPFParagraph> iterator = doc.getParagraphsIterator();
XWPFParagraph para;
while (iterator.hasNext()) {
para = iterator.next();
replaceInPara(para, params);
}
} /**
* 替换段落里面的变量
* @param para 要替换的段落
* @param params 参数
*/
private static void replaceInPara(XWPFParagraph para, Map<String, Object> params) {
List<XWPFRun> runs;
System.out.println("para.getParagraphText()=="+para.getParagraphText()); runs = para.getRuns();
for (int i=0; i<runs.size(); i++) {
XWPFRun run = runs.get(i);
String runText = run.toString();
System.out.println("runText=="+runText); // 替换文本内容,将自定义的$xxx$替换成实际文本
for(Map.Entry<String, Object> entry : params.entrySet())
{
runText = runText.replace(entry.getKey(), entry.getValue()+"");
//直接调用XWPFRun的setText()方法设置文本时,在底层会重新创建一个XWPFRun,把文本附加在当前文本后面,
//所以我们不能直接设值,需要先删除当前run,然后再自己手动插入一个新的run。
para.removeRun(i);
para.insertNewRun(i).setText(runText);
}
}
} /**
* 替换表格里面的变量
* @param doc 要替换的文档
* @param params 参数
*/
private static void replaceInTable(XWPFDocument doc, Map<String, Object> params) {
Iterator<XWPFTable> iterator = doc.getTablesIterator();
XWPFTable table;
List<XWPFTableRow> rows;
List<XWPFTableCell> cells;
List<XWPFParagraph> paras;
while (iterator.hasNext()) {
table = iterator.next();
rows = table.getRows();
for (XWPFTableRow row : rows) {
cells = row.getTableCells();
for (XWPFTableCell cell : cells) {
paras = cell.getParagraphs();
for (XWPFParagraph para : paras) {
replaceInPara(para, params);
}
}
}
}
} }
PoiUtils.java
4、运行

5、效果【生成的docx文件有问题,之前的样式全失效了】

混淆配置
暂无
参考资料
Android使用ApachePOI组件读写Worddoc和docx文件
Java:封装POI实现word的docx文件的简单模板功能
项目demo下载地址
链接:https://pan.baidu.com/s/165hpn3kZssxVvHIF9RNtkQ 提取码:3mmj
PoiDocxDemo【Android将表单数据生成Word文档的方案之二(基于Poi4.0.0),目前只能java生成】的更多相关文章
- FreemarkerJavaDemo【Android将表单数据生成Word文档的方案之一(基于freemarker2.3.28,只能java生成)】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 这个方案只能在java中运行,无法在Android项目中运行.所以此方案是:APP将表单数据发送给后台,后台通过freemarker ...
- PoiDemo【Android将表单数据生成Word文档的方案之二(基于Poi4.0.0)】
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 使用Poi实现android中根据模板文件生成Word文档的功能.这里的模板文件是doc文件.如果模板文件是docx文件的话,请阅读 ...
- Android根据word模板文档将表单数据生成word文档的方案整理
版权声明:本文为HaiyuKing原创文章,转载请注明出处! 前言 尝试的方案包括以下几种: freemarker 只能在java项目上运行,无法在Android项目上运行: 参考资料:<Fre ...
- Java Web项目中使用Freemarker生成Word文档
Web项目中生成Word文档的操作屡见不鲜.基于Java的解决方式也是非常多的,包含使用Jacob.Apache POI.Java2Word.iText等各种方式,事实上在从Office 2003開始 ...
- Java 导出数据库表信息生成Word文档
一.前言 最近看见朋友写了一个导出数据库生成word文档的业务,感觉很有意思,研究了一下,这里也拿出来与大家分享一波~ 先来看看生成的word文档效果吧 下面我们也来一起简单的实现吧 二.Java 导 ...
- PowerDesigner将PDM导出生成WORD文档
PowerDesigner将PDM导出生成WORD文档 环境 PowerDesigner15 1.点击Report Temlates 制作模板 2.如果没有模板,单击New图标创建.有直接双击进入. ...
- 将HTML导出生成word文档
前言: 项目开发中遇到了需要将HTML页面的内容导出为一个word文档,所以有了这边随笔. 当然,项目开发又时间有点紧迫,第一时间想到的是用插件,所以百度了下.下面就介绍两个导出word文档的方法. ...
- POI生成word文档完整案例及讲解
一,网上的API讲解 其实POI的生成Word文档的规则就是先把获取到的数据转成xml格式的数据,然后通过xpath解析表单式的应用取值,判断等等,然后在把取到的值放到word文档中,最后在输出来. ...
- 使用freemarker模板引擎生成word文档的开发步骤
1.准备模板文档,如果word文档中有表格,只保留表头和第一行数据:2.定义变量,将word文档中的变量用${var_name}替换:3.生成xml文件,将替换变量符后的word文档另存为xml文件: ...
随机推荐
- Android 路由框架ARouter最佳实践
转载请标明出处:http://blog.csdn.net/zhaoyanjun6/article/details/76165252 本文出自[赵彦军的博客] 一:什么是路由? 说简单点就是映射页面跳转 ...
- (七):C++分布式实时应用框架 2.0
C++分布式实时应用框架 2.0 技术交流合作QQ群:436466587 欢迎讨论交流 上一篇:(六):大型项目容器化改造 版权声明:本文版权及所用技术归属smartguys团队所有,对于抄袭,非经同 ...
- centos/linux 禁止root用户远程登录
注意:在禁止root等前要建立一个用户用来远程登录,否则退出后无法通过远程登录服务器. 编辑 /etc/ssh/sshd_config 文件 更改参数 PermitRootLogin yes 为 Pe ...
- C++程序内存布局
代码区(code area) 程序内存空间 全局数据区(data area) 堆区(heap area) 栈区(stack area) 一个由C/C++编译的程序占用的内存分为以下几个部分, 1) ...
- IntelliJ IDEA添加jar包
以JDBC-MySQL驱动包为例 1.在IntelliJ IDEA中打开要添加jar包的Project 2.File – Project Structure如下图 3.选择Moudules – 再选择 ...
- Vim手册
什么是 vim? Vim是从 vi 发展出来的一个文本编辑器.代码补完.编译及错误跳转等方便编程的功能特别丰富,在程序员中被广泛使用. 简单的来说, vi 是老式的字处理器,不过功能已经很齐全了,但是 ...
- Kali Linux虚拟机安装完整安装过程及简单配置(视频)
点击播放视频 附:视频中出现的两个txt文本,包含了大致的安装与配置过程: 文本1:KaliLinux虚拟机安装和初步配置 Kali Linux虚拟机安装和初步配置 大家好,今天给大家演示一下在VMw ...
- InnoDB页压缩技术
Ⅰ.想起一个报错 1.1 创建表报错 (root@localhost) [(none)]> create tablespace ger_space add datafile 'ger_space ...
- Javascript继承,再谈
说到Javascript的继承,相信只要是前端开发者都有所了解或应用,因为这是太基础的知识了.但不知各位有没有深入去理解其中的玄机与奥秘.今本人不才,但也想用自己的理解来说一说这其中的玄机和奥秘. 一 ...
- repr调试python程序
一般调试程序的时候都比较倾向print,利用直接打印的方法作出判断,但是print只能打印出结果,对类型无法作出判断.例如: a = 5 b = ' print(a) print(b) 结果为: 5 ...