一天搞懂深度学习-训练深度神经网络(DNN)的要点
前言
这是《一天搞懂深度学习》的第二部分
一、选择合适的损失函数
典型的损失函数有平方误差损失函数和交叉熵损失函数。
交叉熵损失函数:

选择不同的损失函数会有不同的训练效果
二、mini-batch和epoch
(1)什么是mini-batch和epoch
所谓的mini-batch指的是我们将原来的数据分成不重叠的若干个小的数据块。然后在每一个epoch里面分别的运行每个mini-batch。ecpoch的次数和mini-batch的大小可以由我们自己设置。
(2)进行mini-batch和epoch划分的原因
之所以要进行mini-batch和epoch的改变,一个很重要的原因是这样就可以实现并行计算。但是这样的话,每一次的L就不是全局损失而是局部损失。mini-batch采用了并行计算会比之前传统算法的速度更快。并且mini-batch的效果会比传统的方法好
(3)mini-batch和epoch的缺点
mini-batch是不稳定的。mini-batch不一定会收敛。
三、新的激励函数
深度学习并不是说神经网络的层数越多越好。因为神经网络的深度越深那么在误差回传的过程中,因为层数过多可能会有梯度消失的问题。所谓梯度消失问题指的是在训练的过程中,越靠近输出层的学习的越快越靠近输入层的学习的越慢。那么随着深度的增加,靠近输出层的隐含层权重已经收敛了,但是靠近输入层的隐含层却还没有什么变化,相当于还是像初始的时候一样权重是随机的。
为了梯度消失的问题,学者提出了使用ReLU函数作为激励函数。以下是ReLU函数:
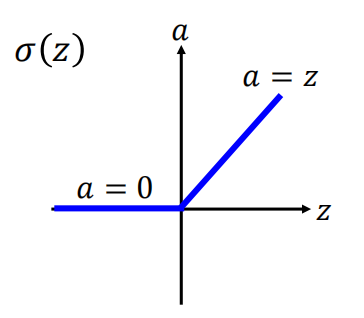
(1)为什么要选择ReLU函数作为激励函数
1.很容易计算
2.Relu函数和我们神经元的激励机制很像:神经元只有在接收一定量的刺激才能够产生反应
3.infinite sigmoid with different biases【这句话不知道咋解释】
4.解决梯度消失问题
(2)ReLU函数的变种
ReLU函数有很多种形式,上面的函数图像只是其中最原始的一种。还有Leaky ReLU和Parametric ReLU
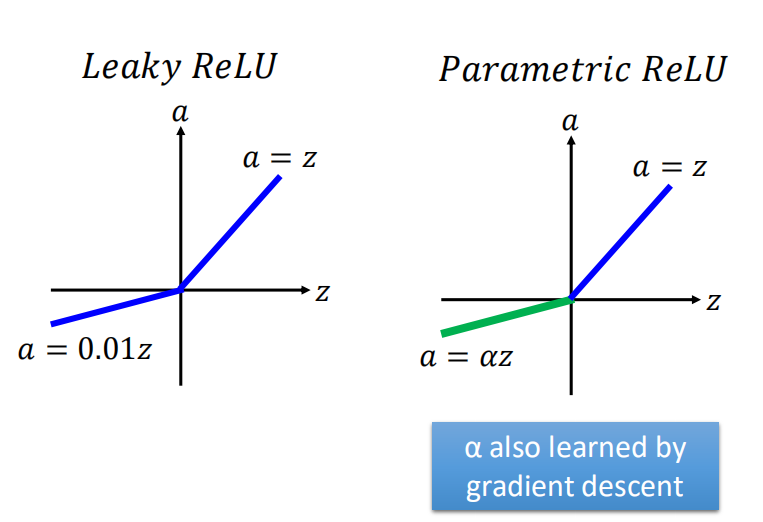
(3)Maxout激励函数
Maxout激励函数先将隐含层的神经元进行分组然后利用分段函数得到组中每一个elements的值,取最大的输出。这个分段函数分的段数是取决于一个group里面有多少个elements。其实ReLU就是一个group里面只有一个element的Maxout激励函数
四、自适应的学习率
学习率是一个很重要的参数,如果学习率选择的太大的话就会出现无法收敛的情况,如果学习率选择的太小的话收敛的太慢,训练过程太长。
我们选择学习率一般不是选择一个固定的值,而是让它随着训练次数的不断增加而减少。学习率针对不同的参数应该是不同的。并且对于所有的参数来说学习率应该越来越小。导数越大,学习率越小;导数越小,学习率越大。【这里导数是有正负性的】
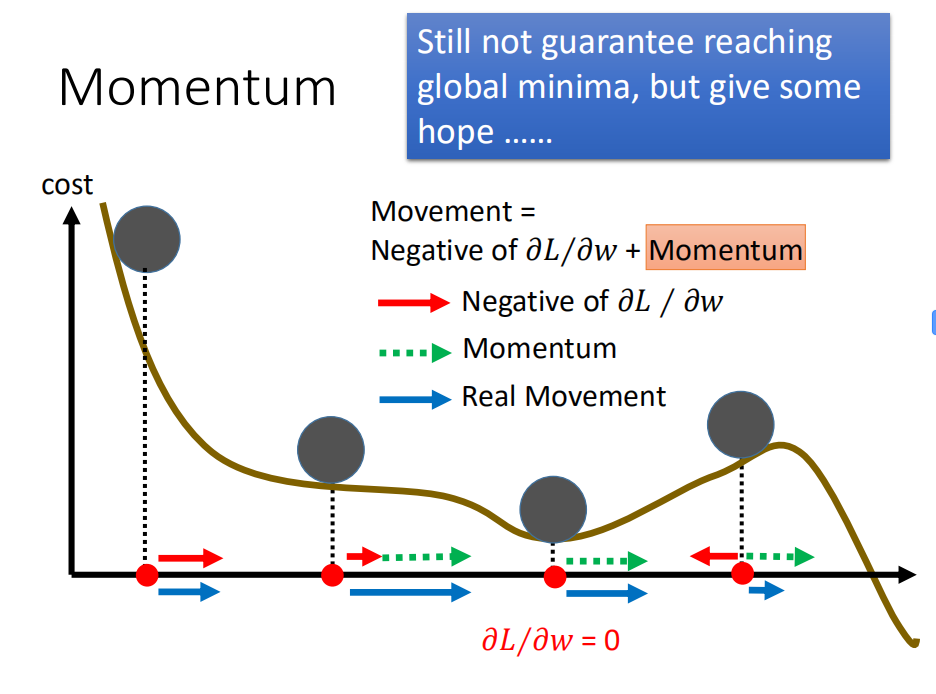
五、Momentum
单纯的使用导数用于改变学习率,很容易陷入局部最小,或者极值点。为了避免这一点,我们使用了Momentum。虽然加上Momentum并不能完全的避免陷入局部最小,但是可以从一定的程度上减缓这个现象。
六、过拟合
所谓的过拟合,就是过度的学习训练集的特征,将训练集独有的特征当做了数据的全局特征,使得其无法适应测试集的分布。
防止过拟合的方法叫做正则化,正则化的方式有很多。
在神经网络中正则化的方法主要有四种:
1.早起停止(eary stopping):比如我们可以设置训练的最大轮数等
2.权重衰减:减少无用的边的权重
3.droupout:每次训练的时候都删除一些节点单元,这样会使网络结构变得简单,训练过程也变得更加简单。它的定义是如果你在训练的阶段对于某一层删除了p%节点,那么你在训练时该层的神经元的权重也要衰减p%。droupout可以看做是一个ensamble的过程。
4.网络结构:比如CNN
一天搞懂深度学习-训练深度神经网络(DNN)的要点的更多相关文章
- java web应用调用python深度学习训练的模型
之前参见了中国软件杯大赛,在大赛中用到了深度学习的相关算法,也训练了一些简单的模型.项目线上平台是用java编写的web应用程序,而深度学习使用的是python语言,这就涉及到了在java代码中调用p ...
- 中文译文:Minerva-一种可扩展的高效的深度学习训练平台(Minerva - A Scalable and Highly Efficient Training Platform for Deep Learning)
Minerva:一个可扩展的高效的深度学习训练平台 zoerywzhou@gmail.com http://www.cnblogs.com/swje/ 作者:Zhouwan 2015-12-1 声明 ...
- TensorRT深度学习训练和部署图示
TensorRT深度学习训练和部署 NVIDIA TensorRT是用于生产环境的高性能深度学习推理库.功率效率和响应速度是部署的深度学习应用程序的两个关键指标,因为它们直接影响用户体验和所提供服务的 ...
- 基于NVIDIA GPUs的深度学习训练新优化
基于NVIDIA GPUs的深度学习训练新优化 New Optimizations To Accelerate Deep Learning Training on NVIDIA GPUs 不同行业采用 ...
- MLPerf结果证实至强® 可有效助力深度学习训练
MLPerf结果证实至强 可有效助力深度学习训练 核心与视觉计算事业部副总裁Wei Li通过博客回顾了英特尔这几年为提升深度学习性能所做的努力. 目前根据英特尔 至强 可扩展处理器的MLPerf结果显 ...
- 深度学习训练过程中的学习率衰减策略及pytorch实现
学习率是深度学习中的一个重要超参数,选择合适的学习率能够帮助模型更好地收敛. 本文主要介绍深度学习训练过程中的6种学习率衰减策略以及相应的Pytorch实现. 1. StepLR 按固定的训练epoc ...
- 学习笔记︱Nvidia DIGITS网页版深度学习框架——深度学习版SPSS
DIGITS: Deep Learning GPU Training System1,是由英伟达(NVIDIA)公司开发的第一个交互式深度学习GPU训练系统.目的在于整合现有的Deep Learnin ...
- 深度学习之卷积神经网络(CNN)的应用-验证码的生成与识别
验证码的生成与识别 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10755361.html 目录 1.验证码的制 ...
- 深度学习之循环神经网络RNN概述,双向LSTM实现字符识别
深度学习之循环神经网络RNN概述,双向LSTM实现字符识别 2. RNN概述 Recurrent Neural Network - 循环神经网络,最早出现在20世纪80年代,主要是用于时序数据的预测和 ...
随机推荐
- Scipy教程 - 统计函数库scipy.stats
http://blog.csdn.net/pipisorry/article/details/49515215 统计函数Statistical functions(scipy.stats) Pytho ...
- Java创建柱状图及饼状图
Java创建图表其实还是很方便的,但是要引入相关的jar包.如下 jfreechart.jar jcommon,jar gnujaxp.jar 其中最主要的是jfreechart.jar. 下面就让我 ...
- 《.NET最佳实践》与Ext JS/Touch的团队开发
概述 持续集成 编码规范 测试 小结 概述 有不少开发人员都问过我,Ext JS/Touch是否支持团队开发?对于这个问题,我可以毫不犹豫的回答:支持.原因是在Sencha官网博客中客户示例中,有不少 ...
- Struts Chain ClassCastException Aop
我们知道struts的restult type 有很多,但主要就是四种 dispatch,rediret,chain,drdirectaction 要让数据从一个action传到另一个action,就 ...
- listview的工作原理
/** * Unsorted views that can be used by the adapter as a convert view. */ private ArrayList<View ...
- 对C语言中递归算法的分析
C通过运行时堆栈支持递归函数的实现.递归函数就是直接或间接调用自身的函数. 许多教科书都把计算机阶乘和菲波那契数列用来说明递归,非常不幸我们可爱的著名的老潭老师的<C语言程序设计> ...
- centos下安装mysql(安装,启动,停止,服务端口查询,用户密码设定)
http://www.2cto.com/database/201305/208114.html http://smilemonkey.iteye.com/blog/673848 netstat -na ...
- 网站开发进阶(二十三)Address already in use: JVM_Bind <null>:8088
Address already in use: JVM_Bind <null>:8088 注:请点击此处进行充电! 阿里云服务器又莫名其妙的宕掉!内存泄漏问题依然存在,又出现了端口占用的情 ...
- LeetCode之“树”:Balanced Binary Tree
题目链接 题目要求: Given a binary tree, determine if it is height-balanced. For this problem, a height-balan ...
- ERP-非财务人员的财务培训教(三)------公司/部门预算编制与评价
一.预算管理中的行为问题 二.编制预算中的问题 三.经营计划与预算制度 第一节 经营目标 第二节 预算编制的内容及说明 第三节 推行预算制度的组织 第 ...