SPFA 算法详解
适用范围:给定的图存在负权边,(快看小说网)这时类似Dijkstra等算法便没有了用武之地,而Bellman-Ford算法的复杂度又过高,SPFA算法便 派上用场了。 我们约定有向加权图G不存在负权回路,即最短路径一定存在。当然,我们可以在执行该算法前做一次拓扑排序,以判断是否存在负权回路,但这不是我们讨论的重 点。
算法思想:我们用数组d记录每个结点的最短路径估计值,用邻接表来存储图G。我们采取的方法是动态逼近法:设立一个先进先出的队列用来保存待优化的 结点,优化时每次取出队首结点u,并且用u点当前的最短路径估计值对离开u点所指向的结点v进行松弛操作,如果v点的最短路径估计值有所调整,且v点不在 当前的队列中,就将v点放入队尾。这样不断从队列中取出结点来进行松弛操作,直至队列空为止
期望的时间复杂度O(ke), 其中k为所有顶点进队的平均次数,可以证明k一般小于等于2。
实现方法:
建立一个队列,初始时队列里只有起始点,再建立一个表格记录起始点到所有点的最短路径(该表格的初始值要赋为极大值,该点到他本身的路径赋为 0)。然后执行松弛操作,用队列里有的点作为起始点去刷新到所有点的最短路,
男欢女爱如果刷新成功且被刷新点不在队列中则把该点加入到队列最后。重复执行直到队列 为空。
判断有无负环:
如果某个点进入队列的次数超过N次则存在负环(SPFA无法处理带负环的图)
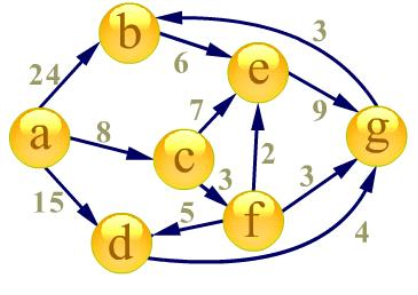
首先建立起始点a到其余各点的
最短路径表格
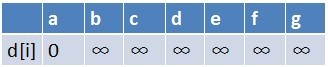
首先源点a入队,当队列非空时:
1、队首元素(a)出队,对以a为起始点的所有边的终点依次进行松弛操作(此处有b,c,d三个点),此时路径表格状态为:
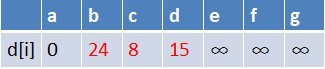
在松弛时三个点的最短路径估值变小了,而这些点队列中都没有出现,这些点
需要入队,此时,队列中新入队了三个结点b,c,d
队首元素b点出队,对以b为起始点的所有边的终点依次进行松弛操作(此处只有e点),此时路径表格状态为:
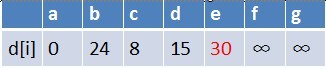
在最短路径表中,e的最短路径估值也变小了,e在队列中不存在,因此e也要
入队,此时队列中的元素为c,d,e
队首元素c点出队,对以c为起始点的所有边的终点依次进行松弛操作(此处有e,f两个点),此时路径表格状态为:
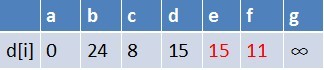
在最短路径表中,e,f的最短路径估值变小了,e在队列中存在,f不存在。因此
e不用入队了,f要入队,此时队列中的元素为d,e,f
队首元素d点出队,对以d为起始点的所有边的终点依次进行松弛操作(此处只有g这个点),此时路径表格状态为:
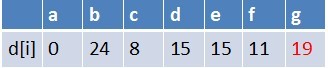
在最短路径表中,g的最短路径估值没有变小(松弛不成功),没有新结点入队,队列中元素为f,g
队首元素f点出队,对以f为起始点的所有边的终点依次进行松弛操作(此处有d,e,g三个点),此时路径表格状态为:

在最短路径表中,e,g的最短路径估值又变小,队列中无e点,e入队,队列中存在g这个点,g不用入队,此时队列中元素为g,e
队首元素g点出队,对以g为起始点的所有边的终点依次进行松弛操作(此处只有b点),此时路径表格状态为:
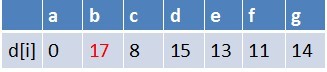
在最短路径表中,b的最短路径估值又变小,队列中无b点,b入队,此时队列中元素为e,b
队首元素e点出队,对以e为起始点的所有边的终点依次进行松弛操作黎南杨小丽(此处只有g这个点),此时路径表格状态为:
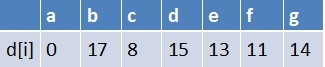
在最短路径表中,g的最短路径估值没变化(松弛不成功),此时队列中元素为b
队首元素b点出队,对以b为起始点的所有边的终点依次进行松弛操作(此处只有e这个点),此时路径表格状态为:
在最短路径表中,e的最短路径估值没变化(松弛不成功),此时队列为空了
最终a到g的最短路径为14
java代码
package spfa负权路径; import java.awt.List;
import java.util.ArrayList;
import java.util.Scanner;
public class SPFA {
/**
* @param args
*/
public long[] result; //用于得到第s个顶点到其它顶点之间的最短距离
//数组实现邻接表存储
class edge{
public int a;//边的起点
public int b;//边的终点
public int value;//边的值
public edge(int a,int b,int value){
this.a=a;
this.b=b;
this.value=value;
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
SPFA spafa=new SPFA();
Scanner scan=new Scanner(System.in);
int n=scan.nextInt();
int s=scan.nextInt();
int p=scan.nextInt();
edge[] A=new edge[p];
for(int i=0;i<p;i++){
int a=scan.nextInt();
int b=scan.nextInt();
int value=scan.nextInt();
A[i]=spafa.new edge(a,b,value);
}
if(spafa.getShortestPaths(n,s,A)){
for(int i=0;i<spafa.result.length;i++){
System.out.println(spafa.result[i]+" ");
}
}else{
System.out.println("存在负环");
}
}
/*
* 参数n:给定图的顶点个数
* 参数s:求取第s个顶点到其它所有顶点之间的最短距离
* 参数edge:给定图的具体边
* 函数功能:如果给定图不含负权回路,则可以得到最终结果,如果含有负权回路,则不能得到最终结果
*/
private boolean getShortestPaths(int n, int s, edge[] A) {
// TODO Auto-generated method stub
ArrayList<Integer> list = new ArrayList<Integer>();
result=new long[n];
boolean used[]=new boolean[n];
int num[]=new int[n];
for(int i=0;i<n;i++){
result[i]=Integer.MAX_VALUE;
used[i]=false;
}
result[s]=0;//第s个顶点到自身距离为0
used[s]=true;//表示第s个顶点进入数组队
num[s]=1;//表示第s个顶点已被遍历一次
list.add(s); //第s个顶点入队
while(list.size()!=0){
int a=list.get(0);//获取数组队中第一个元素
list.remove(0);//删除数组队中第一个元素
for(int i=0;i<A.length;i++){
//当list数组队的第一个元素等于边A[i]的起点时
if(a==A[i].a&&result[A[i].b]>(result[A[i].a]+A[i].value)){
result[A[i].b]=result[A[i].a]+A[i].value;
if(!used[A[i].b]){
list.add(A[i].b);
num[A[i].b]++;
if(num[A[i].b]>n){
return false;
}
used[A[i].b]=true;//表示边A[i]的终点b已进入数组队
}
}
}
used[a]=false; //顶点a出数组对
}
return true;
}
}
SPFA 算法详解的更多相关文章
- 图的最短路径-----------SPFA算法详解(TjuOj2831_Wormholes)
这次整理了一下SPFA算法,首先相比Dijkstra算法,SPFA可以处理带有负权变的图.(个人认为原因是SPFA在进行松弛操作时可以对某一条边重复进行松弛,如果存在负权边,在多次松弛某边时可以更新该 ...
- SPFA 算法详解( 强大图解,不会都难!) (转)
适用范围:给定的图存在负权边,这时类似Dijkstra等算法便没有了用武之地,而Bellman-Ford算法的复杂度又过高,SPFA算法便 派上用场了. 我们约定有向加权图G不存在负权回路,即最短路径 ...
- SPFA算法详解
前置知识:Bellman-Ford算法 前排提示:SPFA算法非常容易被卡出翔.所以如果不是图中有负权边,尽量使用Dijkstra!(Dijkstra算法不能能处理负权边,但SPFA能) 前排提示*2 ...
- Bellman-Ford算法与SPFA算法详解
PS:如果您只需要Bellman-Ford/SPFA/判负环模板,请到相应的模板部分 上一篇中简单讲解了用于多源最短路的Floyd算法.本篇要介绍的则是用与单源最短路的Bellman-Ford算法和它 ...
- Bellman-Ford&&SPFA算法详解
Dijkstra在正权图上运行速度很快,但是它不能解决有负权的最短路,如下图: Dijkstra运行的结果是(以1为原点):0 2 12 6 14: 但手算的结果,dist[4]的结果显然是5,为什么 ...
- 【最短路径Floyd算法详解推导过程】看完这篇,你还能不懂Floyd算法?还不会?
简介 Floyd-Warshall算法(Floyd-Warshall algorithm),是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法,与Dijkstra算法类似.该算法名称以 ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
随机推荐
- jQuery对象的创建(一)
在jQuery的常规用法中,执行"$()"返回的是一个jQuery对象,在源码中,它是这样定义的: ... var jQuery = function() { return new ...
- Ionic进行PC端Web开发时通过脚本压缩提高第一次加载效率
1. 问题 1.1. 问题上下文描述: 基于Ionic进行PC端的Web应用开发: 使用Tomcat作为最终服务发布容器. 1.2. 问题描述: 编译后main.js的大小为4-6MByte.(集成第 ...
- 关于QT中的音频通信问题
今天给大家讲说一个新的东西,使用QT实现音频通信的功能,挺起来是不是很高大上啊,哈哈,实际上我们只是使用一些接口做一些简单的工作而已,并不是让你写一个传输协议和采集音频信息,好了,那我们就来说一说关于 ...
- CI Weekly #20 | 从持续集成的角度看 “云” 的价值
很多移动开发工程师对 fastlane 耳熟能详,最近 flow.ci 的 iOS 工作流「编译」这步已采用 fastlane gym 工具(iOS 应用打包签名自动化),进一步优化了构建打包速度.快 ...
- 当react框架遇上百度地图
百度地图官方文档的使用指导是这样说的:在页面中引入<script type="text/javascript" src="http://api.map.baid ...
- DFS and BFS
DFS https://github.com/Premiumlab/Python-for-Algorithms--Data-Structures--and-Interviews/blob/master ...
- node.js零基础详细教程(3):npm包管理、git github的使用
第三章 建议学习时间4小时 课程共10章 学习方式:详细阅读,并手动实现相关代码 学习目标:此教程将教会大家 安装Node.搭建服务器.express.mysql.mongodb.编写后台业务逻辑 ...
- lucene全文搜索之二:创建索引器(创建IKAnalyzer分词器和索引目录管理)基于lucene5.5.3
前言: lucene全文搜索之一中讲解了lucene开发搜索服务的基本结构,本章将会讲解如何创建索引器.管理索引目录和中文分词器的使用. 包括标准分词器,IKAnalyzer分词器以及两种索引目录的创 ...
- C#开发移动应用系列(2.使用WebView搭建WebApp应用)
前言 上篇文章地址:C#开发移动应用系列(1.环境搭建) 嗯..一周了 本来打算2天一更的 - - ,结果 出差了..请各位原谅.. 今天我们来讲一下使用WebView搭建WebApp应用. 说明一下 ...
- 【基础】Asp.Net操作Cookie总结
一.什么是Cookie? Cookie是存储在客户端文件系统的文本文件或客户端浏览器对话的内存中的少量数据.它主要用来跟踪数据设置,例如:当我们要访问一个网站网页的时候,用户请求网页时,应用程序可能会 ...