[大数据]-Logstash-5.3.1的安装导入数据到Elasticsearch5.3.1并配置同义词过滤
阅读此文请先阅读上文:[大数据]-Elasticsearch5.3.1 IK分词,同义词/联想搜索设置,前面介绍了ES,Kibana5.3.1的安装配置,以及IK分词的安装和同义词设置,这里主要记录Logstash导入mysql数据到Elasticsearch5.3.1并设置IK分词和同义词。由于logstash配置好JDBC,ES连接之后运行脚本一站式创建index,mapping,导入数据。但是如果我们要配置IK分词器就需要修改创建index,mapping的配置,下面详细介绍。
一、Logstash-5.3.1下载安装:
- 下载:https://www.elastic.co/cn/downloads/logstash
- 解压:tar -zxf logstash-5.3.1.tar.gz
- 启动:bin/logstash -e 'input { stdin { } } output { stdout {} }' (参数表示终端输入输出)如下则成功。
Sending Logstash's logs to /home/rzxes/logstash-5.3.1/logs which is now configured via log4j2.properties
[2017-05-16T10:27:36,957][INFO ][logstash.setting.writabledirectory] Creating directory {:setting=>"path.queue", :path=>"/home/rzxes/logstash-5.3.1/data/queue"}
[2017-05-16T10:27:37,041][INFO ][logstash.agent ] No persistent UUID file found. Generating new UUID {:uuid=>"c987803c-9b18-4395-bbee-a83a90e6ea60", :path=>"/home/rzxes/logstash-5.3.1/data/uuid"}
[2017-05-16T10:27:37,581][INFO ][logstash.pipeline ] Starting pipeline {"id"=>"main", "pipeline.workers"=>1, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>125}
[2017-05-16T10:27:37,682][INFO ][logstash.pipeline ] Pipeline main started
The stdin plugin is now waiting for input:
[2017-05-16T10:27:37,886][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
二、Logstash-5.3.1连接mysql作为数据源,ES作为数据输出端:
- 由于此版本的logstash已经集成了jdbc插件,我们只需要添加一个配置文件xxx.conf。内容如下test.conf:
input {
stdin {
}
jdbc {
# 数据库地址 端口 数据库名
jdbc_connection_string => "jdbc:mysql://IP:3306/dbname"
# 数据库用户名
jdbc_user => "user"
# 数据库密码
jdbc_password => "pass"
# mysql java驱动地址
jdbc_driver_library => "/home/rzxes/logstash-5.3.1/mysql-connector-java-5.1.17.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "100000"
# sql 语句文件,也可以直接写SQL,如statement => "select * from table1"
statement_filepath => "/home/rzxes/logstash-5.3.1/test.sql"
schedule => "* * * * *"
type => "jdbc"
}
}
output {
stdout {
codec => json_lines
}
elasticsearch {
hosts => "192.168.230.150:9200"
index => "test-1" #索引名称
document_type => "form" #type名称
document_id => "%{id}" #id必须是待查询的数据表的序列字段} }
- 创建一个SQL文件:如上配置test.sql内容: select * from table1
- test.conf,test.sql文件都在logstash的根目录下。
- 运行logstash脚本导入数据: bin/logstash -f test.conf 启动如下;
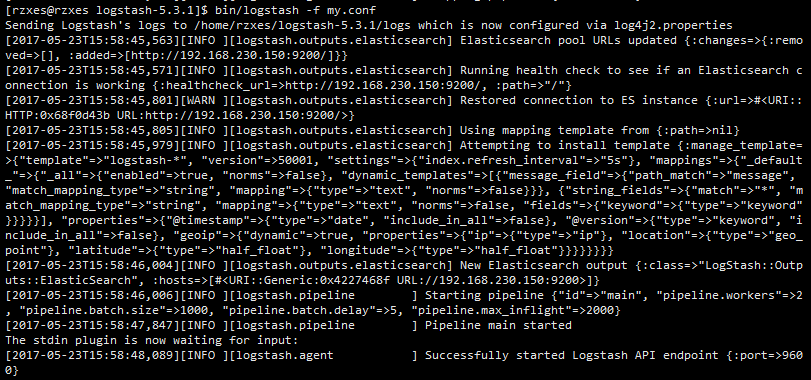
- 等待数据导入完成。开启Es-head,访问9100端口如下:
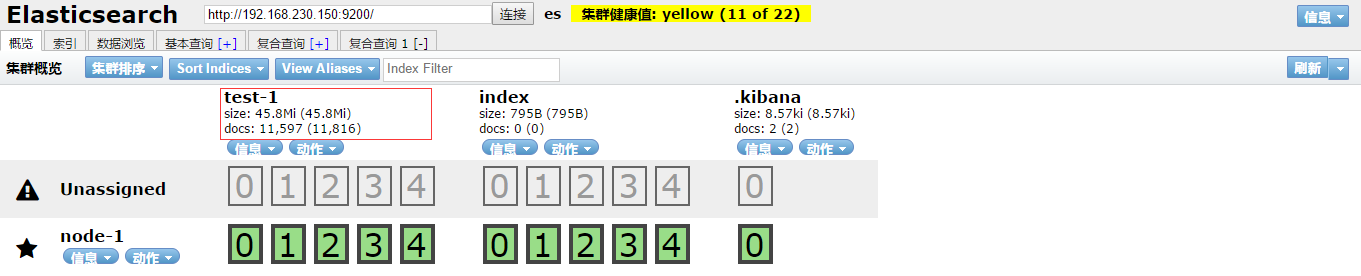
可以看到已经导入了11597条数据。
- 更多详细的配置参考官方文档:plugins-inputs-jdbc-jdbc_driver_library
三、logstash是如何创建index,mapping,并导入数据?
ES导入数据必须先创建index,mapping,但是在logstash中并没有直接创建,我们只传入了index,type等参数,logstash是通过es的mapping template来创建的,这个模板文件不需要指定字段,就可以根据输入自动生成。在logstash启动的时候这个模板已经输出了如下log:
[2017-05-23T15:58:45,801][WARN ][logstash.outputs.elasticsearch] Restored connection to ES instance {:url=>#<URI::HTTP:0x68f0d43b URL:http://192.168.230.150:9200/>}
[2017-05-23T15:58:45,805][INFO ][logstash.outputs.elasticsearch] Using mapping template from {:path=>nil}
[2017-05-23T15:58:45,979][INFO ][logstash.outputs.elasticsearch] Attempting to install template {:manage_template=>{"template"=>"logstash-*", "version"=>50001, "settings"=>{"index.refresh_interval"=>"5s"}, "mappings"=>{"_default_"=>{"_all"=>{"enabled"=>true, "norms"=>false}, "dynamic_templates"=>[{"message_field"=>{"path_match"=>"message", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false}}}, {"string_fields"=>{"match"=>"*", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false, "fields"=>{"keyword"=>{"type"=>"keyword"}}}}}], "properties"=>{"@timestamp"=>{"type"=>"date", "include_in_all"=>false}, "@version"=>{"type"=>"keyword", "include_in_all"=>false}, "geoip"=>{"dynamic"=>true, "properties"=>{"ip"=>{"type"=>"ip"}, "location"=>{"type"=>"geo_point"}, "latitude"=>{"type"=>"half_float"}, "longitude"=>{"type"=>"half_float"}}}}}}}}
- 添加IK分词,只需要创建一个json文件: vim /home/rzxes/logstash-5.3.1/template/logstash.json 添加如下内容:
{
"template": "*",
"version": 50001,
"settings": {
"index.refresh_interval": "5s"
},
"mappings": {
"_default_": {
"_all": {
"enabled": true,
"norms": false
},
"dynamic_templates": [
{
"message_field": {
"path_match": "message",
"match_mapping_type": "string",
"mapping": {
"type": "text",
"norms": false
}
}
},
{
"string_fields": {
"match": "*",
"match_mapping_type": "string",
"mapping": {
"type": "text",
"norms": false,
"analyzer": "ik_max_word",#只需要添加这一行即可设置分词器为ik_max_word
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
],
"properties": {
"@timestamp": {
"type": "date",
"include_in_all": false
},
"@version": {
"type": "keyword",
"include_in_all": false
}
}
}
}
}如需配置同义词,需自定义分词器,配置同义词过滤<IK分词同义词详见上一篇文章>。修改模板logstash.json如下:
{
"template" : "*",
"version" : 50001,
"settings" : {
"index.refresh_interval" : "5s",
#分词,同义词配置:自定义分词器,过滤器,如不配同义词则没有index这一部分
"index": {
"analysis": {
"analyzer": {
"by_smart": {
"type": "custom",
"tokenizer": "ik_smart",
"filter": ["by_tfr","by_sfr"],
"char_filter": ["by_cfr"]
},
"by_max_word": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": ["by_tfr","by_sfr"],
"char_filter": ["by_cfr"]
}
},
"filter": {
"by_tfr": {
"type": "stop",
"stopwords": [" "]
},
"by_sfr": {
"type": "synonym",
"synonyms_path": "analysis/synonyms.txt" #同义词路径
}
},
"char_filter": {
"by_cfr": {
"type": "mapping",
"mappings": ["| => |"]
}
}
}
} # index --end--
},
"mappings" : {
"_default_" : {
"_all" : {
"enabled" : true,
"norms" : false
},
"dynamic_templates" : [
{
"message_field" : {
"path_match" : "message",
"match_mapping_type" : "string",
"mapping" : {
"type" : "text",
"norms" : false
}}
},
{
"string_fields" : {
"match" : "*",
"match_mapping_type" : "string",
"mapping" : {
"type" : "text",
"norms" : false,
#选择分词器:自定义分词器,或者ik_mmax_word
"analyzer" : "by_max_word",
"fields" : {
"keyword" : {
"type" : "keyword"
}
}
}
}
}
],
"properties" : {
"@timestamp" : {
"type" : "date",
"include_in_all" : false
},
"@version" : {
"type" : "keyword",
"include_in_all" : false
}
}
}
}
}- 有了自定义模板文件,test.conf中配置模板覆盖使模板生效。test.conf最终配置如下:
input {
stdin {
}
jdbc {
# 数据库地址 端口 数据库名
jdbc_connection_string => "jdbc:mysql://IP:3306/dbname"
# 数据库用户名
jdbc_user => "user"
# 数据库密码
jdbc_password => "pass"
# mysql java驱动地址
jdbc_driver_library => "/home/rzxes/logstash-5.3.1/mysql-connector-java-5.1.17.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "100000"
# sql 语句文件
statement_filepath => "/home/rzxes/logstash-5.3.1/mytest.sql"
schedule => "* * * * *"
type => "jdbc"
}
}
output {
stdout {
codec => json_lines
}
elasticsearch {
hosts => "192.168.230.150:9200"
index => "test-1"
document_type => "form"
document_id => "%{id}" #id必须是待查询的数据表的序列字段
template_overwrite => true
template => "/home/rzxes/logstash-5.3.1/template/logstash.json"
}
}- 删除上次创建的index(由于数据导入时会根据原有数据的index,mapping进行索引创建),重新启动logstash。
- 最终在Kibana中检索关键词 番茄,就会发现西红柿也会被检索到。如下图:

- 致此logstash数据导入的template重写就完成了。
- 另一种方式配置IK分词:全局配置,不需要自定义模板。
curl -XPUT "http://192.168.230.150:9200/_template/rtf" -H 'Content-Type: application/json' -d'
{
"template" : "*",
"version" : 50001,
"settings" : {
"index.refresh_interval" : "5s",
"index": {
"analysis": {
"analyzer": {
"by_smart": {
"type": "custom",
"tokenizer": "ik_smart",
"filter": ["by_tfr","by_sfr"],
"char_filter": ["by_cfr"]
},
"by_max_word": {
"type": "custom",
"tokenizer": "ik_max_word",
"filter": ["by_tfr","by_sfr"],
"char_filter": ["by_cfr"]
}
},
"filter": {
"by_tfr": {
"type": "stop",
"stopwords": [" "]
},
"by_sfr": {
"type": "synonym",
"synonyms_path": "analysis/synonyms.txt"
}
},
"char_filter": {
"by_cfr": {
"type": "mapping",
"mappings": ["| => |"]
}
}
}
}
},
"mappings" : {
"_default_" : {
"_all" : {
"enabled" : true,
"norms" : false
},
"dynamic_templates" : [
{
"message_field" : {
"path_match" : "message",
"match_mapping_type" : "string",
"mapping" : {
"type" : "text",
"norms" : false
}}
},
{
"string_fields" : {
"match" : "*",
"match_mapping_type" : "string",
"mapping" : {
"type" : "text",
"norms" : false,
"analyzer" : "by_max_word",
"fields" : {
"keyword" : {
"type" : "keyword"
}
}
}
}
}
],
"properties" : {
"@timestamp" : {
"type" : "date",
"include_in_all" : false
},
"@version" : {
"type" : "keyword",
"include_in_all" : false
}
}
}
}
}'- 可以使用curl查看模板: curl -XGET "http://192.168.230.150:9200/_template"
[大数据]-Logstash-5.3.1的安装导入数据到Elasticsearch5.3.1并配置同义词过滤的更多相关文章
- [大数据]-Fscrawler导入文件(txt,html,pdf,worf...)到Elasticsearch5.3.1并配置同义词过滤
fscrawler是ES的一个文件导入插件,只需要简单的配置就可以实现将本地文件系统的文件导入到ES中进行检索,同时支持丰富的文件格式(txt.pdf,html,word...)等等.下面详细介绍下f ...
- Java使用JDBC连接数据库逐条插入数据、批量插入数据、以及通过SQL语句批量导入数据的效率对比
测试用的示例java代码: package com.zifeiy.test.normal; import java.io.File; import java.io.FileOutputStream; ...
- 【neo4j】文件管理路径、数据备份、创建新数据库、导入数据等操作记录
neo4j一般的配置路径如下 一.备份数据 使用neo4j-admin命令. 首先,先找到数据的存储路径,然后关闭数据库. 关闭数据库的语句如下: #切换到/bin目录下 ./neo4j stop 然 ...
- 第十节:Web爬虫之数据存储与MySQL8.0数据库安装和数据插入
用解析器解析出数据之后,接下来就是存储数据了,保存的形式可以多种多样,最简单的形式是直接保存为文本文件,如 TXT.JSON.csv 另外,还可以保存到数据库中,如关系型数据库MySQL ,非关系型数 ...
- 使用BCP批量导入数据
本文原创,转载请标明出处 BCP 工具的使用 The bulk copy program utility (bcp) bulk copies data between an instance of M ...
- geotrellis使用(二十一)自动导入数据
目录 前言 整体介绍 前台界面 后台控制 总结 一.前言 之前Geotrellis数据导入集群采用的是命令行的方式,即通过命令行提交spark任务来ingest数据,待数据导入完毕再启动 ...
- 一起学Hive——详解四种导入数据的方式
在使用Hive的过程中,导入数据是必不可少的步骤,不同的数据导入方式效率也不一样,本文总结Hive四种不同的数据导入方式: 从本地文件系统导入数据 从HDFS中导入数据 从其他的Hive表中导入数据 ...
- 记录一次向TiDB数据库导入数据的例子
导出数据 今天从Mysql的某个库中导出一个表大概有20分钟吧,等了一会终于导出成功了.查看一下文件的大小: [tidb@:vg_adn_CkhsTest ~]$du -h ./creative_ou ...
- Hive数据导入——数据存储在Hadoop分布式文件系统中,往Hive表里面导入数据只是简单的将数据移动到表所在的目录中!
转自:http://blog.csdn.net/lifuxiangcaohui/article/details/40588929 Hive是基于Hadoop分布式文件系统的,它的数据存储在Hadoop ...
随机推荐
- Asp.NetCore之组件写法
本章内容和大家分享的是Asp.NetCore组件写法,在netcore中很多东西都以提供组件的方式来使用,比如MVC架构,Session,Cache,数据库引用等: 这里我也通过调用验证码接口来自定义 ...
- State模式学习笔记
选用了一个假设需要用户验证的例子进行State模式学习,这个例子并不恰当.无所谓了,只要能学习到其中的内容即可. 适用性: 1,一个对象的行为取决于他的状态,并且它必须在运行时刻依据状态改变他的行为. ...
- JavaScript基础学习(九)—DOM
一.DOM概述 DOM(Document Object Model)文本对象模型. D: 文档,HTML文档或XML文档. O: 对象,document对象的属性和方法. ...
- NDK 线程同步
使用场景 对底层代码进行 HOOK, 不可避免的要考虑多线程同步问题, 当然也可以写个类似 java 的线程本地变量来隔离内存空间. 死锁分析 恩, 道理其实大家都懂的, 毕竟大学就学了操作系统,理论 ...
- seo从业者发展方向
对于很多朋友来说,seo就是一项比较简单的技能,内容+外链,就可以基本囊括seo的基本内容了.可能很多朋友对此不屑一顾,会说seo可是包含万象, 你需要懂网页设计.标签设计,分词优化.企业建站等等方面 ...
- Java线程池(ThreadPool)详解
线程五个状态(生命周期): 线程运行时间 假设一个服务器完成一项任务所需时间为:T1 创建线程时间,T2 在线程中执行任务的时间,T3 销毁线程时间. 如果:T1 + T3 远大于 T2,则可以 ...
- HTML5的localStorage和sessionStorage
HTMl5提供了sessionStorage和localStorage数据存储方法,用于临时或者永久的存储客户端的数据: sessionStorage:用于保存回话数据 localStorage:用于 ...
- http协议的八种请求类型
GET:向特定的资源发出请求. POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件).数据被包含在请求体中.POST请求可能会导致新的资源的创建和/或已有资源的修改. OPTIONS: ...
- Vue.js动画在项目使用的两个示例
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 李萌,16年毕业,Web前端开发从业者,目前就职于腾讯,喜欢node.js.vue.js等技术,热爱新技术,热 ...
- [转载]前端构建工具gulpjs的使用介绍及技巧
转载地址:http://www.cnblogs.com/2050/p/4198792.html gulpjs是一个前端构建工具,与gruntjs相比,gulpjs无需写一大堆繁杂的配置参数,API也非 ...