python django 使用 haystack:全文检索的框架
haystack:全文检索的框架
whoosh:纯Python编写的全文搜索引擎
jieba:一款免费的中文分词包
首先安装这三个包
pip install django-haystack
pip install whoosh
pip install jieba
1.修改settings.py文件,安装应用haystack,
2.在settings.py文件中配置搜索引擎
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
3. 在templates目录下创建“search/indexes/blog/”目录 采用blog应用名字下面创建一个文件blog_text.txt
#指定索引的属性
{{ object.title }}
{{ object.text}}
{{ object.keywords }}
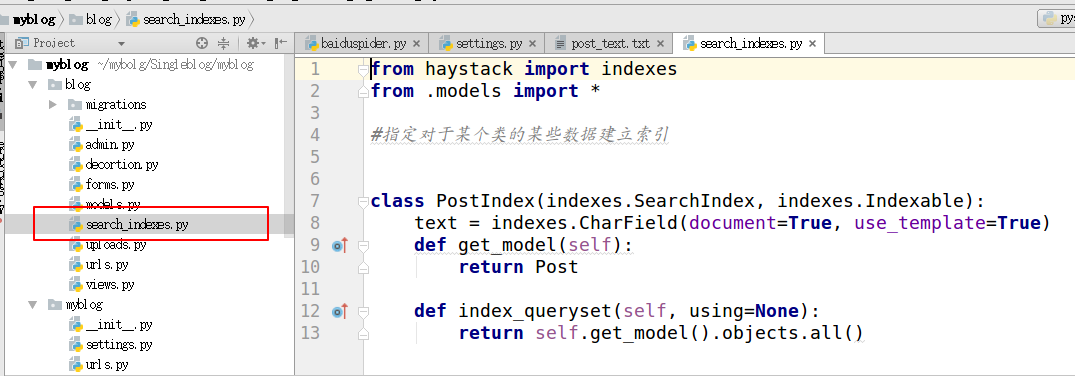
4.在需要搜索的应用下面创建search_indexes
from haystack import indexes
from models import Post #指定对于某个类的某些数据建立索引
class GoodsInfoIndex(indexes.SearchIndex, indexes.Indexable):
text = indexes.CharField(document=True, use_template=True)
def get_model(self):
return Post #搜索的模型类
def index_queryset(self, using=None):
return self.get_model().objects.all()
5.
1. 修改haystack文件
2. 找到虚拟环境py_django下的haystack目录 这个目录根据自己使用的python环境不同,路径也不一样。
3. site-packages/haystack/backends/ 创建一个文件名为ChineseAnalyzer.py文件写入下面代码,用于中文分词
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()
6.
1复制whoosh_backend.py文件,改为如下名称
whoosh_cn_backend.py
在复制出来的文件中导入中文分词模块
from .ChineseAnalyzer import ChineseAnalyzer
2. 更改词语分析类 改成中文
查找analyzer=StemmingAnalyzer()改为analyzer=ChineseAnalyzer()
7. 最后一步就是建初始化索引数据
python manage.py rebuild_index
8. 创建搜索模板 在templates/indexes/ 创建search.html模板
搜索结果进行分页,视图向模板中传递的上下文如下
query:搜索关键字
page:当前页的page对象
paginator:分页paginator对象
9. 在自己的应用视图中导入模块
from haystack.generic_views import SearchView
定义一个类重写get_context_data 方法,这样就可以往模板中传递自定义的上下文。
class GoodsSearchView(SearchView):
def get_context_data(self, *args, **kwargs):
context = super().get_context_data(*args, **kwargs)
context['iscart']=1
context['qwjs']=2
return context
应用的urls文件中添加这条url 将类当一个视图的方法使用 .as_view()
url('^search/$', views.BlogSearchView.as_view())
python django 使用 haystack:全文检索的框架的更多相关文章
- Django:haystack全文检索详细教程
参考:https://blog.csdn.net/AC_hell/article/details/52875927 一.安装第三方库及配置 1.1 安装插件 pip install whoosh dj ...
- Haystack全文检索框架
一.什么是Haystack Haystack是django的开源全文搜索框架(全文检索不同于特定字段的模糊查询,使用全文检索的效率更高 ),该框架支持Solr,Elasticsearch,Whoosh ...
- Python Django框架笔记(五):模型
#前言部分来自Django Book (一) 前言 大多数web应用本质上: 1. 每个页面都是将数据库的数据以HTML格式进行展现. 2. 向用户提供修改数据库数据的方法.(例如:注册.发表评 ...
- python django框架(一)
s4day63内容回顾: 1. 安装 2. 创建用户 + 授权 3. 连接 - 数据库 终端创建数据库(字符编码) - 数据表 终端 ORM pymysql create ...)engine=inn ...
- [Python] Django框架入门
说明:Django框架入门 当前项目环境:python3.5.django-1.11 项目名:test1 应用名:booktest 命令可简写为:python manager.py xxx => ...
- 利用 Python django 框架 输入汉字,数字,字符,等。。转成二维码!
利用 Python django 框架 输入汉字,数字,字符,等..转成二维码! 模块必备:Python环境 + pillow + qrcode 模块 核心代码import qrcode qr = ...
- Python Django框架笔记(六):模板
(一){%%}和{{ }} {% for post in posts %} <a href=""><h2>{{ post.title }}</h2&g ...
- Haystack全文检索
1.什么是Haystack Haystack是django的开源全文搜索框架(全文检索不同于特定字段的模糊查询,使用全文检索的效率更高 ),该框架支持Solr,Elasticsearch(java写的 ...
- django使用haystack对接Elasticsearch实现商品搜索
# 原创,转载请留言联系 前言: 在做一个商城项目的时候,需要实现商品搜索功能. 说到搜索,第一时间想到的是数据库的 select * from tb_sku where name like %苹果手 ...
随机推荐
- struts2快速入门
1. 下载开发包 课程 以 struts2 3.15.1 讲解 2. 目录结构 apps : struts2官方demo docs : 文档 lib : jar包 src : 源码 3. 导入jar包 ...
- C# 爬虫 Jumony html解析
前言 前几天写了个爬虫,然后认识到了自己的不足.感谢 "倚天照海- -" ,我通过你推荐的文章,意外的发现了html解析的类库——Jumony. 研究了2天,我发现这个东西简单粗暴 ...
- Keil提示premature end of file错误 无法生成HEX文件
今天舍友在使用Keil UV4的时候遇到一个问题:Keil提示premature end of file,无法生成hex文件. 代码是没有错误的.那么问题就出在设置上面了. 百度了一圈,发现很少人解答 ...
- jre1.8使用ikvm.net8将jar转换为dll以供c#调用
由于合作方使用.net编程,jar包不能用,需要转换成dll格式,来回转换了十几个dll文件,终于生成了一个可用的.在这里将走过的弯弯绕绕总结下,希望遇到相似问题的同好们,能走得顺利些. 版本问题: ...
- HTML5新增属性data-*和js/jquery之间的交互
HTML5新增属性data- data-自定义属性,这种方式的自定义属性解决属性混乱无状态管理的现状 书写实例 <div data-role="page" data-last ...
- Wampserver查看php配置信息
Wampserver安装完成之后输入localhost会有欢迎Wampserver界面. [查看php配置信息]:在页面点击"phpinfo()"进入php配置信息页面. [使用p ...
- poj 3635 带花费的Dij+head优化
练习!! 这里主要需要注意的是进队的条件和dp[][]状态的控制,dp[i][j]表示到第i个城市剩余汽油为j的最小花费. 代码: #include<iostream> #include& ...
- 移动端适配方案以及rem和px之间的转换
背景 开发移动端H5页面 面对不同分辨率的手机 面对不同屏幕尺寸的手机 视觉稿 在前端开发之前,视觉MM会给我们一个psd文件,称之为视觉稿. 对于移动端开发而言,为了做到页面高清的效果,视觉稿的规范 ...
- oracle12之 多租户容器数据库架构
解读: 这张幻灯片展示了三个被部署的应用程序的整合 三个不同的非cdbs成为一个单一的.幻灯片中的图形显示了一个多租户 容器数据库有四个容器:根和三个可插入的数据库.每一个 可插入数据库有它自己的专用 ...
- socket和抓包工具wireshark
socket和抓包工具wireshark 最近在学习Python代码中的socket和抓包工具wireshark,故又将socket等概念又学习了一遍,温故而知新: Python代码如下: serve ...