Coursera 机器学习笔记(四)
主要为第六周内容机器学习应用建议以及系统设计。
下一步做什么
当训练好一个模型,预测未知数据,发现结果不如人意,该如何提高呢?
先不要急着尝试这些方法,而是通过一些机器学习诊断方法来判断现在算法是什么情况,哪些方法是可以提高算法的有效性,如何选择更有意义的方法。
如何评估模型
假设评估
过拟合检验:将数据集分为训练集和测试集(通常70%训练集,30%测试集),训练集和测试集均要包含各种结果的数据。
测试集评估:1.对于线性回归模型,利用测试集数据计算代价函数。2.对于逻辑回归模型,可以计算代价函数,也可以计算错误分类的比例。
模型选择
数据集分类:60%的数据作为训练集; 20%的数据作为交叉验证集;20%的数据作为测试集。
模型选择方法:1.训练集训练出多个模型;2.用每个模型分别对交叉验证集计算得出交叉验证误差;3.选取代价最小的模型;4.用选出的模型对测试集计算推广误差。
诊断方法
注:high bias翻译为高偏差,high variance翻译为高方差,regularization 翻译为正则化
一.偏差和方差
之前线性回归介绍过低拟合和过拟合。高偏差和高方差问题基本上就是低拟合和过拟合的问题。
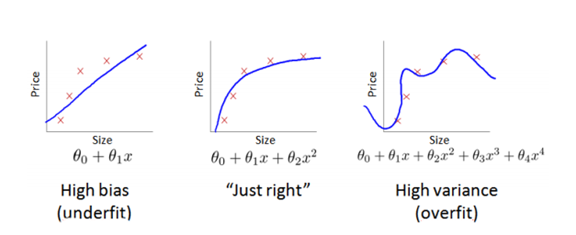
通过将训练集和交叉验证集的代价函数误差与多项式的次数绘制在同一张图表上来帮助分析:
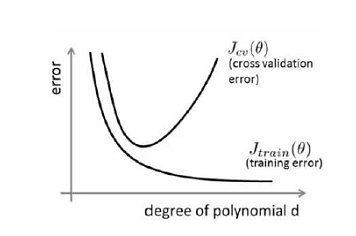
由上图可以看出:1.对于训练集,当 d 较小时,模型拟合程度更低,误差较大;随着 d 的增长,拟合程度提高,误差减小。
2.对于交叉验证集,当 d 较小时,模型拟合程度低,误差较大;但是随着 d 的增长,误差呈现先减小后增大的趋势,转折点是我们的模型开始过拟合训练数据集的时候。
我们可以知道:1.训练集误差和交叉验证集误差近似时:高偏差/低拟合;2.
交叉验证集误差远大于训练集误差时:高方差/过拟合
二.正则化
正则化可以用来防止过拟合。正则化程度由λ值控制,需要通过一定的方法选择合适的λ值。
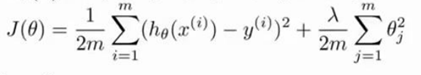
我们选择一系列的想要测试的 λ 值,通常是 0-10 之间的呈现 2 倍关系的值(如:0,0.01,0.02,0.04,0.08,0.15,0.32,0.64,1.28,2.56,5.12,10 共 12 个)。
我们同样把数据分为训练集、交叉验证集和测试集。选择λ的方法为:
1.使用训练集训练出
多个不同程度正则化的模型(即不同的λ值)
2. 用
每个模型分别对交叉验证集计算的出交叉验证误差
3. 选择得出交叉验证误差最小的模型
4. 运用步骤 3 中选出模型对测试集计算得出推广误差
同时将训练集和交叉验证集模型的代价函数误差与λ的值绘制在一张图表上:
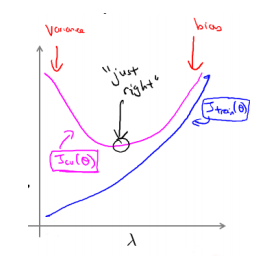
由上图可以看出:1.当λ较小时,训练集误差较小(过拟合)而交叉验证集误差较大;2.随着λ的增加,训练集误差不断增加(低拟合),而交叉验证集误差则是先减小后增加。
三.学习曲线
学习曲线是将训练集误差和交叉验证集误差作为训练集实例数量(m)的函数绘制的图表,是学习算法的一个很好的合理检验。
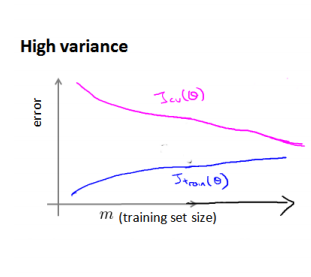
高偏差和高方差的情况如下图所示:
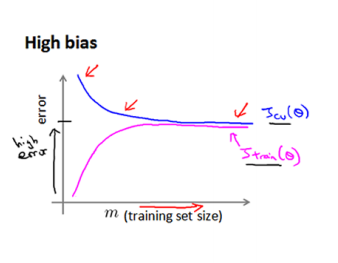
由上图可以看出:在高偏差/低拟合的情况下,训练集增加数量不一定有帮助。
在高方差/过拟合的情况下,增加数据到训练集可以提高模型的效果。
解决方案
数据多就是好?由上面的分析可以知道获得更多的数据只能解决高方差问题。
回到开头提出的六种方法,可以看出它们对应解决的问题,可不能乱用哟!
1.获得更多的训练实例——解决高方差问题
2.尝试减少特征的数量——解决高方差问题
3.尝试获得更多的特征——解决高偏差问题
4.尝试增加二项式特征——解决高偏差问题
5.尝试减少归一化程度λ——解决高方差问题
6.尝试增加归一化程度λ——解决高偏差问题
神经网络与高偏差和高方差的关系:
1.使用较小的神经网络,类似于参数较少的情况,容易导致高偏倚和低拟合,但计算代价较小
2.使用较大的神经网络,类似于参数较多的情况,容易导致高偏差和过拟合,虽然计算代价比较大,但是可以通过归一化手段来调整而更加适应数据。
通常选择较大的神经网络并采用正则化处理会比采用较小的神经网络效果要好。对于神经网络中的隐藏层的层数的选择,通常从一层开始逐渐增加层数。为了更好地作选择,可以把数据分为训练集、交叉验证集和测试集,针对不同隐藏层层数的神经网络训练神经网络,然后选择交叉验证集代价最小的神经网络。
误差分析
误差分析是指人工检查交叉验证集中我们算法中产生预测误差的实例,看看这些实例是否有某种系统化的趋势。误差分析可以帮助我们系统化地选择该做什么。
以我们的垃圾邮件过滤器为例,误差分析要做的既是检验交叉验证集中我们的算法产生错误预测的所有邮件,看:
1.是否能将这些邮件按照类分组。例如医药品垃圾邮件,仿冒品垃圾邮件或者密码窃取邮件等。然后看分类器对哪一组邮件的预测误差最大,并着手优化。
2.思考怎样能改进分类器。例如,发现是否缺少某些特征,记下这些特征出现的次数。例如记录下错误拼写出现了多少次,异常的邮件路由情况出现了多少次等等,然后从出现次数最多的情况开始着手优化。
误差度量
将算法预测的结果分成四种情况:
1.正确肯定(True Positive,TP):预测为真,实际为真
2.正确否定(True Negative,TN):预测为假,实际为真
3.错误肯定(False Positive,FP):预测为真,实际为假
4.错误否定(False Negative,FN):预测为假,实际为假
相应的查准率(Precision)和查全率(Recall)的计算:
查准率=TP/(TP+FP)
查全率=TP/(TP+FN)
查准率(Precision)和查全率(Recall)的关系:
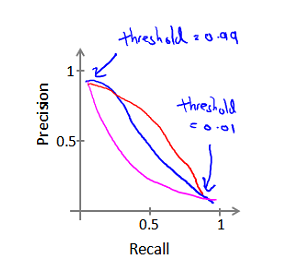
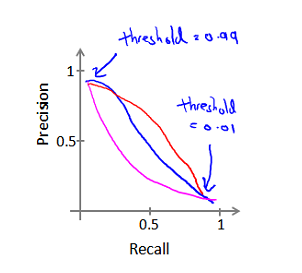
值(F1 Score),其计算公式为:
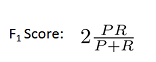
F1能平衡查准率和查全率,选择F1最高的值。
系统设计
构建一个学习算法的推荐方法为:
1. 从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算法
2. 绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择
3. 进行误差分析
Coursera 机器学习笔记(四)的更多相关文章
- coursera机器学习笔记-机器学习概论,梯度下降法
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-建议,系统设计
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-神经网络,学习篇
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-神经网络,初识篇
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-多元线性回归,normal equation
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- Coursera 机器学习笔记(三)
主要为第四周.第五周课程内容:神经网络 神经网络模型引入 之前学习的线性回归还是逻辑回归都有个相同缺点就是:特征太多会导致计算量太大.如100个变量,来构建一个非线性模型.即使只采用两两特征组合,都会 ...
- Coursera机器学习笔记(一) - 监督学习vs无监督学习
转载 http://daniellaah.github.io/2016/Machine-Learning-Andrew-Ng-My-Notes-Week-1-Introduction.html 一. ...
- Coursera 机器学习笔记(八)
主要为第十周内容:大规模机器学习.案例.总结 (一)随机梯度下降法 如果有一个大规模的训练集,普通的批量梯度下降法需要计算整个训练集的误差的平方和,如果学习方法需要迭代20次,这已经是非常大的计算代价 ...
- Coursera 机器学习笔记(七)
主要为第九周内容:异常检测.推荐系统 (一)异常检测(DENSITY ESTIMATION) 核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非 ...
随机推荐
- 第一个 lua 程序
第一个 lua 程序 lua 提供一个交互式编程模式, 直接在命令行输入 lua 开启 $ lua > -- 此处可以输入 lua 程序 lua 脚本执行时的 2 种方式 lua + lua 脚 ...
- [转]DevExpress GridControl 关于使用CardView的一点小结
最近项目里需要显示商品的一系列图片,打算用CardView来显示,由于第一次使用,遇到许多问题,发现网上这方面的资源很少,所以把自己的一点点实际经验小结一下,供自己和大家以后参考. 1.选择CardV ...
- 《阿里巴巴Java开发手册(正式版》读记
前几天,阿里巴巴发布了<阿里巴巴Java开发手册(正式版>,第一时间下载阅读了一番. 不同于一般大厂内部的代码规范,阿里巴巴的这本Java开发手册,可谓包罗万象,几乎日常Java开发中方方 ...
- JQuery插件之Animate.css和 jquery-aniview
Animate.css 一款强大的预设css3动画库 简介 animate.css 是一个来自国外的 CSS3 动画库,它预设了抖动(shake).闪烁(flash).弹跳(bounce).翻转(fl ...
- java线程控制安全
synchronized() 在线程运行的时候,有时会出现线程安全问题例如:买票程序,有可能会出现不同窗口买同一张编号的票 运行如下代码: public class runable implement ...
- 苹果笔记本只能上QQ,微信,任何浏览器不能打开网页的问题。
我的笔记本一共遇到过两次这种情况.第一次是浏览器输入域名打不开网页,而输入ip地址可以打开.这就是DNS服务器的问题,解决方法很简单.在系统偏好设置里面找到网络,然后,点击正在连接的网络的高级选项,选 ...
- Magento中URL路径的获取
//获得 media 带 http 的url 地址. Mage::getBaseUrl('media') //获得skin 和js 目录的地址: Mage::getBaseUrl('skin'); M ...
- 一个只有99行代码的JS流程框架(二)
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 张镇圳,腾讯Web前端高级工程师,对内部系统前端建设有多年经验,喜欢钻研捣鼓各种前端组件和框架. 导语 前面写 ...
- windows下安装Redis并部署成服务
windows下安装Redis并部署成服务 Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库.缓存和消息中间件. 一:下载 下载地址: windows版本: http ...
- 2017Unity开发者大会备受关注的原因有哪些?
Unite大会是由Unity举办的全球开发者大会,至今已有10年的历史.从最开始Unity开发者大会仅500人,到现在Unity大会已经增长到5000人,10倍的参与人数,Unity开发者大会仅仅用了 ...