Coursera 机器学习笔记(三)
主要为第四周、第五周课程内容:神经网络
神经网络模型引入
之前学习的线性回归还是逻辑回归都有个相同缺点就是:特征太多会导致计算量太大。如100个变量,来构建一个非线性模型。即使只采用两两特征组合,都会有接近5000个组成的特征。这对于普通的线性回归和逻辑回归计算特征量太大了。因此,神经网路孕育而生。
神经网络最初产生的目的是制造能模拟大脑的机器,能很好地解决不同的机器学习问题。模型表示为:
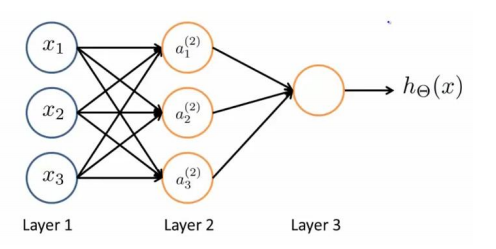
第一层为输入层,最后一层为输出层,中间的层为隐藏层。如把逻辑回归最为神经网络模型的神经元,a(j)I 代表第j层的第i个激活单元,θ(j)表示从第j层映射到第j+1层时的权重矩阵,其尺寸为第j+1层的激活单元数量为行数,第j层的激活单元数+1为列数的矩阵,如θ(1)尺寸为3*4。对于上图所示模型的表达为:
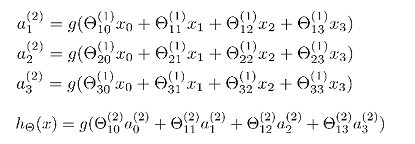
正向传播算法(Forward Propagation)
利用向量化的方法会使计算大为简便。计算上图第二层为例:

这只是针对训练集中一个训练实例所进行的计算。如果我们要对整个训练集进行计算,我们需要将训练集特征矩阵进行转置,使得同一个实例的特征都在同一列里。
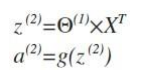
而计算第三层(输出层),可以把第二层看成是输入层,第三层为上述的第二层。

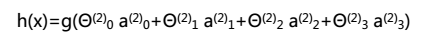
我们可以把 a0,a1,a2,a3看成更为高级的特征值,也就是 x0,x1,x2,x3的进化体,并且它们是由 x 与决定的,因为是梯度下降的,所以 a 是变化的,并且变得越来越厉害,所以这些更高级的特征值远比仅仅将 x 次方厉害,也能更好的预测新数据。
多分类
当我们有不止两种分类时(也就是 y=1,2,3….),比如以下这种情况,该怎么办?如y=4
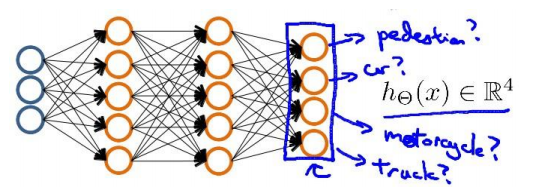
利用one-vs-all思想:神经网络算法的输出结果为四种可能情形之一

代价函数
引入标记表示方法:
- L代表神经网络的层数
- Si代表第i层的处理单元(包括偏见单元)的个数
- SL代表最后一层中的处理单元的个数
- K代表希望分类的个数,与SL相等
逻辑回归中的代价函数为:
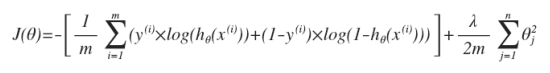
逻辑回归中只有一个输出变量,而在神经网络中有很多输出变量,h(x) 是个一个维度为K的向量,因此因变量也是一个维度为K的向量。神经网络相应的代价函数为:
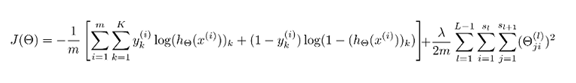
反向传播算法
综合
网络结构:
第一件要做的事是选择网络结构,即决定选择多少层以及决定每层分别有多少个单元。
- 第一层的单元数即我们训练集的特征数量
- 最后一层的单元数是我们训练集的结果的类的数量
- ,确保每个隐藏层的单元个数相同,通常情况下隐藏层单元的个数越多越好
我们真正要决定的是隐藏层的层数和每个中间层的单元数。
训练神经网络:
1. 参数的随机初始化
2. 利用正向传播方法计算所有的 hθ(x)
3. 编写计算代价函数 J 的代码
4. 利用反向传播方法计算所有偏导数
5. 利用数值检验方法检验这些偏导数
6. 使用优化算法来最小化代价函数
Coursera 机器学习笔记(三)的更多相关文章
- coursera机器学习笔记-建议,系统设计
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-多元线性回归,normal equation
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-机器学习概论,梯度下降法
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-神经网络,学习篇
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- coursera机器学习笔记-神经网络,初识篇
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- Coursera 机器学习笔记(八)
主要为第十周内容:大规模机器学习.案例.总结 (一)随机梯度下降法 如果有一个大规模的训练集,普通的批量梯度下降法需要计算整个训练集的误差的平方和,如果学习方法需要迭代20次,这已经是非常大的计算代价 ...
- Coursera 机器学习笔记(六)
主要为第八周内容:聚类(Clustering).降维 聚类是非监督学习中的重要的一类算法.相比之前监督学习中的有标签数据,非监督学习中的是无标签数据.非监督学习的任务是对这些无标签数据根据特征找到内在 ...
- Coursera 机器学习笔记(四)
主要为第六周内容机器学习应用建议以及系统设计. 下一步做什么 当训练好一个模型,预测未知数据,发现结果不如人意,该如何提高呢? 1.获得更多的训练实例 2.尝试减少特征的数量 3.尝试获得更多的特征 ...
- Coursera 机器学习笔记(七)
主要为第九周内容:异常检测.推荐系统 (一)异常检测(DENSITY ESTIMATION) 核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非 ...
随机推荐
- sed命令详解-应用篇
本篇从实用的角度讲解sed,关于sed的详细帮助文档,请参考前篇 http://www.cnblogs.com/the-capricornus/p/5279979.html 本篇用到的选项请参考前篇. ...
- Java数据类型(基本数据类型)学习
Java数据类型(基本数据类型)学习 与其他语言一样,Java编程同样存在,比如int a,float b等.在学习变量之前我就必须先了解Java的数据类型啦. Java的数据类型包括基本数据类型和引 ...
- 【CSS】思考和再学习——关于CSS中浮动和定位对元素宽度/外边距/其他元素所占空间的影响
一.width:auto和width:100%的区别 1.width:100%的作用是占满它的参考元素的宽度.(一般情况下参考元素 == 父级元素,这里写成参考元素而不是父级元素,在下面我会再 ...
- Spring+SpringMVC+MyBatis+easyUI整合优化篇(十四)谈谈写博客的原因和项目优化
阶段总结 又到了优化篇的收尾阶段了,这其实是一篇阶段总结性的文章,今天是4月29号,距离第一次发布博客已经两个月零5天,这两个多月的时间,完成了第一个项目ssm-demo的更新,过程中也写了33篇博客 ...
- iOS 使用 UIMenuController 且不隐藏键盘的方法
iOS 使用 UIMenuController 且不隐藏键盘的方法 在键盘显示的时候使用 UIMenuController 弹出菜单,保持键盘显示且可输入的状态. 实现方法有 修改响应链(推荐) 遵循 ...
- 计算进程消费cpu和内存
Linux下没有直接可以调用系统函数知道CPU占用和内存占用.那么如何知道CPU和内存信息呢.只有通过proc伪文件系统来实现. proc伪文件就不介绍了,只说其中4个文件.一个是/proc/stat ...
- C++ 常见的 Undefined symbols for architecture *
出现 Undefined symbols for architecture x86_64: 的原因 1.函数申明了,却未被定义. 2.申明的虚函数未被实现. NOTE: a missing vtabl ...
- maven(03)
修改本地库路径 windows下maven默认路径应该是${user.home}/.m2/repository 修改方法:找到maven安装的根路径,里面有一个conf的文件夹,打开里面有一个sett ...
- SSO单点登录的研究
一.单点登录的概述 单点登录(Single Sign On),简称为 SSO,SSO的定义是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统. 用以解决同一公司不同子产 ...
- RabbitMQ学习2---使用场景
RabbitMQ主页:https://www.rabbitmq.com/ AMQP AMQP协议是一个高级抽象层消息通信协议,RabbitMQ是AMQP协议的实现.它主要包括以下组件: 1.Serve ...