package(1):tm
tm包是R语言中为文本挖掘提供综合性处理的package,进行操作前载入tm包,vignette命令可以让你得到相关的文档说明。使用默认安装的R平台是不带tm package的,在安装的过程中,它会依赖于NLP’,‘BH’ ,‘slam’包,所以最简单的方式就是采用在线安装。 在tm 中主要的管理文件的结构被称为语料库(Corpus),代表了一系列的文档集合
tm包安装
- 在安装依赖的slam包时,出现如下异常,R版本3.2.5
> install.packages("slam", type = "source")
Installing package into ‘C:/Users/zhushy/Documents/R/win-library/3.2’
(as ‘lib’ is unspecified)
Warning in install.packages :
package ‘slam’ is not available (for R version 3.2.5) - 通过如下方式解决:
- 参考:https://cran.r-project.org/web/packages/tm/index.html
- 参考:http://stackoverflow.com/questions/40419015/install-packagestm-dependency-slam-is-not-available
library(devtools)
install_url("https://cran.r-project.org/src/contrib/Archive/slam/slam_0.1-37.tar.gz")
基本函数
- 基本用法参考:http://blog.163.com/zzz216@yeah/blog/static/162554684201412892742116/
- vignette("tm") //会打开一个tm.pdf的英文文件,讲述tm package的使用及相关函数
- VectorSource函数: 可以将字符向量创建为corpus,示例如下:
> library(tm)
> library(NLP)
> doc=c("halo halo !","this is second word!")
> corpus1=Corpus(VectorSource(doc))
> corpus1
<<SimpleCorpus>>
Metadata: corpus specific: 1, document level (indexed): 0
Content: documents: 2 - system.file(): 在指定的package中找到每个文件的地址
#找到tm包下texts/crude文件夹的位置,里面含有20个xml文档
adress=system.file("texts","crude",package="tm")
reuters=Corpus(DirSource(adress),readerControl=list(reader=readReut21578XML)) - DirSource():建立一个目录,除此之外还可以利用如下的函数导入不同形式的数据
- VectorSource:由文档构成的向量
- DataframeSource:数据框,就像 CSV 文件
- readerControl=list(reader=,language=),ReadControl中有ReadDOC,readPDF,readPlain,readReut21578XML等不同的读入方式,可以使用getReaders()函数显示出所用的可能的方式,如下:
> getReaders()
[1] "readDOC" "readPDF" "readPlain"
[4] "readRCV1" "readRCV1asPlain" "readReut21578XML"
[7] "readReut21578XMLasPlain" "readTabular" "readTagged"
[10] "readXML" - Corpus:会将此目录下的文件当做一个个的文档
查看及写语料包
- writeCorpus() :将生成的语料库保存成多个纯文本文件
writeCorpus(corpus1,"E:\\R\\",c("a1.txt","a2.txt")) - 结果如下图:(说明:原字符中下图中字符,有敏感词变禁止提交,so 上面的代码换成字母类)
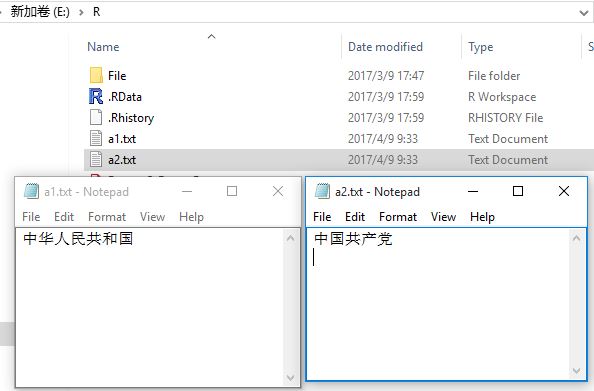
- 查看:inspect\print\summary
> inspect(reuters)
<<VCorpus>>
Metadata: corpus specific: 0, document level (indexed): 0
Content: documents: 20 [[1]]
<<XMLTextDocument>>
Metadata: 16
........ > print(reuters)
<<VCorpus>>
Metadata: corpus specific: 0, document level (indexed): 0
Content: documents: 20 > summary(reuters)
Length Class Mode
127 2 XMLTextDocument list
144 2 XMLTextDocument list
191 2 XMLTextDocument list
194 2 XMLTextDocument list
.......
transformation
- 主要是tm_map函数,可以使用 getTransformations()函数查看所有的字符处理方式(好象不全)
> getTransformations()
[1] "removeNumbers" "removePunctuation" "removeWords" "stemDocument" "stripWhitespace" 示例:
#将reuters转换为纯文本,去除标签
reuters=tm_map(reuters,PlainTextDocument)
# 所有字母转换成小写
corpus_clean <- tm_map(reuters, tolower)
# 去除text中的数字
corpus_clean <- tm_map(reuters, removeNumbers)
# 去除停用词,例如and,or,until...
corpus_clean <- tm_map(reuters, removeWords, stopwords())
# 去除标点符号
corpus_clean <- tm_map(reuters, removePunctuation)
# 去除多余的空格,使单词之间只保留一个空格
corpus_clean <- tm_map(reuters, stripWhitespace)
meta
- 元数据是为了标记语料库的附加信息,最简单的使用范式就是调用meta()函数 .文档会被预先被定义一些属性,比如作者信息,但也可能是任意自定义的元数据标签。这些附加的元数据标签都是独立的附加在单个文档上。从语料库的视角上看,这些元数据标签被独立的存储在每个文档上。除了meta()函数外,DublinCore()函数提供了一套介于SimpleDublin Core元数据和tm元数据之间的映射机制,用于画的或设置文档的元数据信息
- DublinCore:按照都柏林核心的国际标准显示
- 示例:
data("crude")
meta(crude[[1]])
DublinCore(crude[[1]]) 可以对其进行相应的修改、添加
> data("crude")
> meta(crude[[1]],tag="author")
character(0)
> meta(crude[[1]],tag="author") <- "ZZ"
> meta(crude[[1]])
author : ZZ
datetimestamp: 1987-02-26 17:00:56
.......
词条-文档关系矩阵
- 在tm 包里,根据词条、文档分别作为行、列或反之,对应有TermDocumentMatrix 和 DocumentTermMatrix 两类稀疏矩阵, 如下:
> doc=c("This is Frist Word.","That is Second Word!")
> corpus1=Corpus(VectorSource(doc))
> dtm <- DocumentTermMatrix(corpus1)
> inspect(dtm)
<<DocumentTermMatrix (documents: 2, terms: 5)>>
Non-/sparse entries: 6/4
Sparsity : 40%
Maximal term length: 6
Weighting : term frequency (tf)
Sample :
Terms
Docs frist second that this word
1 1 0 0 1 1
2 0 1 1 0 1 字典是一个字符集合。经常用于在文本挖掘中展现相关的词条时。使用Dictionary() 函数实现,当将字典传递到DocumentTermMatrix() 以后,生成的矩阵会根据字典提取计算,而不是全部提取
> d=c("word")
> inspect(DocumentTermMatrix(corpus1, list(dictionary = d)))
<<DocumentTermMatrix (documents: 2, terms: 1)>>
Non-/sparse entries: 2/0
Sparsity : 0%
Maximal term length: 4
Weighting : term frequency (tf)
Sample :
Terms
Docs word
1 1
2 1实际上对于矩阵的操作R 有大量的函数(比如聚类、分类算法等)支持,但这个包还是提供了一些常用的函数支持。
- 假如需要找出发生2 次及以上的条目,可以使用findFreqTerms() 函数:
> findFreqTerms(dtm,2)
[1] "word" 找到相关性,比如对于opec,找到相关系数在0.8 以上的条目,使用findAssocs(),以上小节示例为例
- 词条-文档关系矩阵一般都是非常庞大的数据集,因此这里提供了一种删减稀疏条目的方法removeSparseTerms,比如有些条目尽在很少的文档中出现。一般来说,这样做不会对矩阵的信息继承带来显著的影响。
- 因为生成的term-document矩阵dtm是一个稀疏矩阵,再进行降维处理,之后转为标准数据框格式,以上节示例说明:
#进行降维处理
dtm2 <- removeSparseTerms(dtm, sparse=0.95)
#将term-document矩阵生成数据框
data <- as.data.frame(inspect(dtm2))
完整示例
library(tm)
library(NLP) #找到tm包下texts/crude文件夹的位置,里面含有20个xml文档
adress=system.file("texts","crude",package="tm")
reuters=Corpus(DirSource(adress),readerControl=list(reader=readReut21578XML)) #将reuters转换为纯文本,去除标签
reuters=tm_map(reuters,PlainTextDocument)
# 所有字母转换成小写
corpus_clean <- tm_map(reuters, tolower)
# 去除text中的数字
corpus_clean <- tm_map(reuters, removeNumbers)
# 去除停用词,例如and,or,until...
corpus_clean <- tm_map(reuters, removeWords, ("english"))
# 去除标点符号
corpus_clean <- tm_map(reuters, removePunctuation)
# 去除多余的空格,使单词之间只保留一个空格
corpus_clean <- tm_map(reuters, stripWhitespace)
#将文档转为稀疏矩阵,
dtm <- DocumentTermMatrix(reuters)
#找出发生5次及以上的条目
findFreqTerms(dtm, 5)
#找相关性,比如对于opec,找到相关系数在0.8 以上的条目
findAssocs(dtm, "opec", 0.8)
#要考察多个文档中特有词汇的出现频率,可以手工生成字典,并将它作为生成矩阵的参数
d <- Dictionary(c("prices", "crude", "oil")))
inspect(DocumentTermMatrix(reuters, list(dictionary = d))) #进行降维处理
dtm2 <- removeSparseTerms(dtm, sparse=0.95)
#将term-document矩阵生成数据框
data <- as.data.frame(inspect(dtm2))
package(1):tm的更多相关文章
- hackyviewpager有什么用
继承于viewpager 可以和photoView一起使用,实现相册图片的左右滑动,放大缩小,等 package davidwang.tm.view; import android.content.C ...
- 【机器学习与R语言】3-概率学习朴素贝叶斯(NB)
目录 1.理解朴素贝叶斯 1)基本概念 2)朴素贝叶斯算法 2.朴素贝斯分类应用 1)收集数据 2)探索和准备数据 3)训练模型 4)评估模型性能 5)提升模型性能 1.理解朴素贝叶斯 1)基本概念 ...
- R语言︱文本挖掘套餐包之——XML+SnowballC+tm包
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- R语言︱文本挖掘套餐包之--XML+tm+Sn ...
- R语言 文本挖掘 tm包 使用
#清除内存空间 rm(list=ls()) #导入tm包 library(tm) library(SnowballC) #查看tm包的文档 #vignette("tm") ##1. ...
- 新手根据菜鸟教程安装docker,从No package docker-io available开始遇到的坑...(转)
转文地址:https://www.cnblogs.com/maodot/p/7654918.html 新手centos6.9安装docker时从遇到No package docker-io avail ...
- javac compiling error ( mising package)
javac 编译java源文件时,提示 package does not exist 的错误 Test.java import java.security.MessageDigest; import ...
- vuepress & package.json lock version
vuepress & package.json lock version npm 锁版 bug npm lock version holy shit { "name": & ...
- NPM (node package manager) 入门 - 基础使用
什么是npm ? npm 是 nodejs 的包管理和分发工具.它可以让 javascript 开发者能够更加轻松的共享代码和共用代码片段,并且通过 npm 管理你分享的代码也很方便快捷和简单. 截至 ...
- npm package.json属性详解
概述 本文档是自己看官方文档的理解+翻译,内容是package.json配置里边的属性含义.package.json必须是一个严格的json文件,而不仅仅是js里边的一个对象.其中很多属性可以通过np ...
随机推荐
- 卷积神经网络(CNN)模型结构
在前面我们讲述了DNN的模型与前向反向传播算法.而在DNN大类中,卷积神经网络(Convolutional Neural Networks,以下简称CNN)是最为成功的DNN特例之一.CNN广泛的应用 ...
- JavaScript的for循环中嵌套一个点击事件为何点击一次弹出多个相同的值
先看下面一段代码: for(var i=0; i<10; i++) { $('#ul').bind('click', function() { alert(i) }) } 对于这段代码,当点击I ...
- Git commit message和工作流规范
目的 统一团队Git commit日志标准,便于后续代码review,版本发布以及日志自动化生成等等. 统一团队的Git工作流,包括分支使用.tag规范.issue等 Git commit日志参考案例 ...
- 分页控件AspNetPager学习笔记
1.AspNetPager简介 AspNetPager是一款开源.简单易用.可定制化等等各种优点的Web分页控件. 2.使用方法 1)下载AspNetPager.dll文件(http://www.we ...
- 初探nginx负载均衡集群
借LVS的环境: A(dir):192.168.122.129 B(rs1):192.168.122.140 C(rs2):192.168.122.141 Centos 6下如果安装过epel的yum ...
- Java进制转换示例
收藏的代码,以备查询之用.进制之间转换都是以十进制作为中间层的. int os = 16; //十进制转成十六进制: Integer.toHexString(os); //十进制转成八进制 Integ ...
- 从depth buffer中构建view-space position
观察透视投影矩阵: 对于x和y,矩阵变换只是一个缩放系数,那么逆变换就是缩放系数的倒数,所以 设Xndc Yndc为NDC空间中的XY坐标,Xview Yview Zview为view space中的 ...
- Vue基本入门
介绍 1.Vue.js是什么? Vue.js(读音:/vju:/,类似于view)是一套构建用户界面的渐进式框架,与其他重量级框架不同的是,Vue采用的是自底向上增量开发的设计. Vue的核心库只关注 ...
- 基于SSH协议的端口转发
[前言] 最近一直在使用ssh协议的端口转发(隧道)功能,完成对内网空透等.这篇文章将主要讲解3种常用的ssh tunnelling使用方法和基本原理. 在介绍具体内容前,我先奉上端口转发的常用情景: ...
- multiSelect 下拉多选插件
multiSelect是一款很好用的下拉多选插件,可以在下拉框中实现多选框,全选及取消全选等方法.使用方法:1.引用 multiSelect.css及 multiSelect.js.下载地址 http ...