Lucene的使用与重构
忽然一想好久不写博客了,工作原因个人原因,这些天一直希望一天假如36个小时该多好,但是,假如不可能。
由于近期在项目中接触了lucene,这个已经没有人维护的全文搜索框架,确实踩了不少坑,为什么用lucene呢?其实我也不知道
关于lucene原理和全文搜索引擎的一些介绍,园子里有这几篇写的还是很好的
http://www.cnblogs.com/skybreak/archive/2013/05/06/3063520.html
http://kb.cnblogs.com/page/52642/
由于完全没有接触过lucene,一开始当然是从X度,bing上搜索关于lucene.net的教程,发现找不到好用的,lucene已经好久没有维护了,如果细心阅读源码会发现许多匪夷所思的设计。对于lucene可以理解为一个数据库,lucene提供了添加数据(创建索引),以及快速全文检索的api。
通过学习,我们发现,lucene.net给我们很多对象
Lucene.Net.Store.Directory:lucene文档的存放目录,我这里把它理解为一张表,实际上这一张表的字段可以不一样
Lucene.Net.Documents.Documents:lucene文档,相当于一条数据
Lucene.Net.Index.IndexWriter:用于向Lucene.Net.Store.Directory中添加Lucene.Net.Documents.Documents
Lucene.Net.Analysis.Standard.StandardAnalyzer:词法分析器
当然,还有一系列查询的类,这里就不列举了,说了这么多,我这篇随笔主要介绍什么呢?
既然把lucene理解为一个数据库了,从框架使用者的角度看,不需要拘泥于lucene究竟是如何存储和检索数据的,当然,第一次使用时还是要学习的,但是写完了就会发现代码写的好繁琐啊,每次都要创建Directory,Analyzer写查询语句创建对象,比如项目一开始对站内所有信息进行检索,一次加入所有数据,搜索所有数据,没有问题,后来需要对另一个模块的信息进行单表检索,会发现代码逐渐开始乱了,但是由于时间问题和开发经验一开始很难想到好的设计。刚开始时,项目经理指导将每个需要全文搜索的对象先独立出来,实现一个接口,程序运行时反射实现该接口的类(暂且成他为LuceneModel),即可实现搜索,但是后来需求要实现两种语言的搜索,根据当前前端提供的cookie来查询指定语言的数据,于是我就又给每一个LuceneModel添加一个Language字段,并且Language字段的搜索是一个且的关系(在满足搜索关键字后并且该条数据的语言必须 为从cookie中读取的)。
显然,需要对搜索这个模块进行单独的维护了,这样修改方便,并且也可以供其他项目使用,也是软件设计原则吧!
IndexerAttribute
[AttributeUsage(AttributeTargets.Property, Inherited = false, AllowMultiple = false)]
public class IndexerAttribute : Attribute
{
public bool Index;
public bool Store;
/// <summary>
///
/// </summary>
/// <param name="index">是否为其创建索引</param>
/// <param name="store">是否存储原始数据</param>
public IndexerAttribute(bool index,bool store)
{
Index = index;
Store = store;
}
}
表示对模型具体字段的索引方式
LuceneDB
public abstract class LuceneDB:IDisposable
{
private ILunceneDBPathProvider_dbPathProvider = LunceneDBPathProviders.Current;
private string _dbPath;
protected System.IO.DirectoryInfo _sysDirectory;
protected Lucene.Net.Store.Directory _luDirectory;
protected Lucene.Net.Analysis.Standard.StandardAnalyzer _analyzer;
protected Lucene.Net.Index.IndexWriter _indexWriter;
protected bool _isOpen = false;
public LuceneDB(string path)
{
_dbPath = path;
}
public LuceneDB() { }
public void SetDBPath(Type type)
{
if (null == _dbPath)
{
_dbPath = _dbPathProvider.Get(type);
}
} public string DBPath
{
get
{
return _dbPath;
}
} protected abstract void Open();
public virtual void Dispose()
{
_analyzer.Close();
_analyzer.Dispose();
}
}
首先LuceneDB,表示一个连接对象,有子类LuceneDBIndexer和LuceneDBSearcher,两者用到的资源不一样,所以提供了一个需要实现的Open方法。通常情况下一个Lucene文件夹下有多个索引文件夹,每个索引文件夹有着相似的数据结构(同一个数据类型),为了使这一个模块能够让别的项目使用,第一个要解决的问题就是Lucene文件夹位置的问题了,对于web项目,可以存在APPData也可以存在bin目录下,这里也照顾了下对于Console应用。
ILunceneDBPathProvider
public interface ILunceneDBPathProvider
{
string Get(Type type);
}
默认的是一个AppDataLunceneDBPathProvider
public class AppDataLunceneDBPathProvider : ILunceneDBPathProvider
{
private string _prePath = AppDomain.CurrentDomain.BaseDirectory;
public string Get(Type type)
{
return _prePath + @"\App_Data\Index\" + type.Name;
}
}
这样如果有需要检索的User类,他的lucene文件夹就为App_Data\Index\User
LuceneDBIndexer
public class LuceneDBIndexer: LuceneDB
{
private Dictionary<Type,IEnumerable<PropertyInfo>> _tempProps;
public LuceneDBIndexer(string path) : base(path)
{
}
public LuceneDBIndexer() { }
protected override void Open()
{
if (_isOpen)
{
Dispose();
}
if (!System.IO.Directory.Exists(DBPath))
{
System.IO.Directory.CreateDirectory(DBPath);
}
_analyzer = new Lucene.Net.Analysis.Standard.StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_30);
_luDirectory = Lucene.Net.Store.FSDirectory.Open(new System.IO.DirectoryInfo(DBPath));
_indexWriter = new Lucene.Net.Index.IndexWriter(_luDirectory, _analyzer, true, Lucene.Net.Index.IndexWriter.MaxFieldLength.LIMITED);
_isOpen = true;
}
public IEnumerable<PropertyInfo> GetProps(Type type)
{
if(null == _tempProps)
{
_tempProps = new Dictionary<Type, IEnumerable<PropertyInfo>>();
}
if (!_tempProps.ContainsKey(type))
{
_tempProps.Add(type, type.GetProperties().Where(prop => null != prop.GetCustomAttribute(typeof(IndexerAttribute), true)));
}
return _tempProps[type];
} public void Add<T>(T obj)
{
SetDBPath(typeof(T));
Open(); Document document = new Document();
foreach (var prop in GetProps(typeof(T)))
{
var value = prop.GetValue(obj)?.ToString();
if(null != value)
{
var attr = prop.GetCustomAttribute(typeof(IndexerAttribute), true) as IndexerAttribute;
var store = attr.Store ? Field.Store.YES : Field.Store.NO;
var index = attr.Index ? Field.Index.ANALYZED : Field.Index.NOT_ANALYZED; document.Add(new Field(prop.Name, value, store, index));
}
} _indexWriter.AddDocument(document);
} public void AddRange<T>(IEnumerable<T> objs)
{
SetDBPath(typeof(T));
Open(); foreach (var obj in objs)
{
Document document = new Document();
foreach (var prop in GetProps(typeof(T)))
{
var value = prop.GetValue(obj)?.ToString();
if (null != value)
{
var attr = prop.GetCustomAttribute<IndexerAttribute>();
var store = attr.Store ? Field.Store.YES : Field.Store.NO;
var index = attr.Index ? Field.Index.ANALYZED : Field.Index.NOT_ANALYZED; document.Add(new Field(prop.Name, value, store, index));
}
}
_indexWriter.AddDocument(document);
}
}
public override void Dispose()
{
_indexWriter.Optimize();
_indexWriter.Dispose();
base.Dispose();
}
}
这个类用于创建索引,会读取用在对象上的Indexer标签
LuceneDBSearcher
public class LuceneDBSearcher: LuceneDB
{
private Type _searchType;
public LuceneDBSearcher(string path) : base(path)
{
}
public LuceneDBSearcher(Type type)
{
SetDBPath(type);
}
public LuceneDBSearcher() { }
public Type SearchType
{
set
{
//判断该类型是否实现 某 约定
_searchType = value;
}
get { return _searchType; }
}
public IEnumerable<T> Search<T>(string searchText, IEnumerable<string> fields, int page, int pageSize, Dictionary<string,string> condition= null) where T : new()
{
return GetModels<T>(SearchText(searchText, fields, page, pageSize, condition));
} private IEnumerable<Document> SearchText(string searchText,IEnumerable<string> fields,int page,int pageSize, Dictionary<string,string> condition)
{
StringBuilder conditionWhere = new StringBuilder(); foreach (var item in condition)
{
conditionWhere.Append(" +" + item.Key + ":" + item.Value);
} Open(); var parser = new Lucene.Net.QueryParsers.MultiFieldQueryParser(Lucene.Net.Util.Version.LUCENE_30, fields.ToArray(), _analyzer);
var search = new Lucene.Net.Search.IndexSearcher(_luDirectory, true); var query = parser.Parse("+" + searchText + conditionWhere.ToString()); var searchDocs = search.Search(query, ).ScoreDocs; return searchDocs.Select(t => search.Doc(t.Doc));
} protected override void Open()
{
_luDirectory = Lucene.Net.Store.FSDirectory.Open(new System.IO.DirectoryInfo(DBPath));
if (Lucene.Net.Index.IndexWriter.IsLocked(_luDirectory))
{
Lucene.Net.Index.IndexWriter.Unlock(_luDirectory);
}
var lockFilePath = System.IO.Path.Combine(DBPath, "write.lock"); if (System.IO.File.Exists(lockFilePath))
{
System.IO.File.Delete(lockFilePath);
} _analyzer = new Lucene.Net.Analysis.Standard.StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_30);
}
private IEnumerable<T> GetModels<T>(IEnumerable<Document> documents) where T:new()
{
var type = typeof(T);
var props = type.GetProperties().Where(prop => null != prop.GetCustomAttribute(typeof(IndexerAttribute), true));
var objs = new List<T>();
foreach (var document in documents)
{
var obj = new T();
foreach (var prop in props)
{
var attr = prop.GetCustomAttribute<IndexerAttribute>(); if (null != attr && attr.Store)
{
object v = Convert.ChangeType(document.Get(prop.Name), prop.PropertyType);
prop.SetValue(obj, v);
}
}
objs.Add(obj);
}
return objs;
}
private T GetModel<T>(Document document) where T : new()
{
var type = typeof(T);
var props = type.GetProperties().Where(prop => null != prop.GetCustomAttribute(typeof(IndexerAttribute), true)); var obj = new T();
foreach (var prop in props)
{
var attr = prop.GetCustomAttribute<IndexerAttribute>(); if (null != attr && attr.Store)
{
object v = Convert.ChangeType(document.Get(prop.Name), prop.PropertyType);
prop.SetValue(obj, v);
}
}
return obj;
}
public override void Dispose()
{
_analyzer.Dispose();
base.Dispose();
}
}
用于检索Lucene文件夹并将数据转为对象
LuceneEntityBase
public abstract class LuceneEntityBase:ILuceneStored
{
#region private
private Dictionary<string, PropertyInfo> _propertiesCache;
#endregion #region IndexerFields
#region ILuceneStored
[Indexer(false, true)]
public string ID { get; set; }
[Indexer(true, false)]
public string _Customer { get; set; }
[Indexer(true, false)]
public string _Category { get; set; }
#endregion /// <summary>
/// 图片
/// </summary>
[Indexer(false, true)]
public string Picture { get; set; }
/// <summary>
/// 标题
/// </summary>
[Indexer(true, true)]
public string Title { get; set; }
/// <summary>
/// 简介
/// </summary>
[Indexer(true, true)]
public string Synopsis { get; set; }
/// <summary>
/// 链接
/// </summary>
[Indexer(false, true)]
public string Url { get; set; }
#endregion public LuceneEntityBase()
{ } protected IEnumerable<T> Search<T>(string searchText, int page, int pageSize, object condition = null) where T:new ()
{
var ConditionDictionary = null != condition ? InitConditionSearchFields(condition) : new Dictionary<string, string>(); var fullTextSearchFields = from propName in PropertiesCache.Select(t => t.Key)
where !ConditionDictionary.ContainsKey(propName)
select propName; using (var luceneDB = new LuceneDBSearcher(GetType()))
{
return luceneDB.Search<T>(searchText, fullTextSearchFields, page, pageSize, ConditionDictionary);
}
}
/// <summary>
/// 属性缓存
/// </summary>
protected Dictionary<string, PropertyInfo> PropertiesCache
{
get
{
if(null == _propertiesCache)
{
_propertiesCache = new Dictionary<string, PropertyInfo>();
foreach (var prop in GetType().GetProperties())
{
var attr = prop.GetCustomAttribute<IndexerAttribute>(true); if (null != attr && attr.Index)
{
_propertiesCache.Add(prop.Name, prop);
}
}
}
return _propertiesCache;
}
} /// <summary>
/// 初始化 且 条件
/// </summary>
protected virtual Dictionary<string, string> InitConditionSearchFields(object andCondition)
{
var _conditionDictionary = new Dictionary<string, string>(); var type = GetType();
var andConditionType = andCondition.GetType();
var conditions = type.GetInterfaces().Where(t => typeof(ICondition).IsAssignableFrom(t) && t!= typeof(ICondition))
.SelectMany(t => t.GetProperties() /*t.GetInterfaceMap(t).InterfaceMethods*/)
.Select(t => t.Name);
foreach (var condition in conditions)
{
if (!_conditionDictionary.ContainsKey(condition))
{
_conditionDictionary.Add(condition, andConditionType.GetProperty(condition).GetValue(andCondition)?.ToString() ?? string.Empty);
}
} return _conditionDictionary;
}
}
需要索引的抽象基类
一般而言搜索结果有一个标题,介绍,图片等等,介绍和标题是数据库(这里是db)中实际存储的,然而对于搜索的关键字确实没有的,比如(在博客园中)有一个博客表,表里面存博客标题,博客主要内容,还有一个问道表,用户提的问题,介绍,等等,此时如果用户来到博客园中,键入博客(可能已进入首页都是博客,但是用户还是键入了博客),然而db中却不知道那个是博客??仔细想是不是这样子的,这里_Customer就是设定这些数据的,当然也可以是_Category。
结下来介绍一个比较重要的接口。
ICondition
public interface ICondition { }
作为一个空接口,如果不能找到一个它不应该存在的理由,那它就真的不应该存在了。在上面说的LuceneEntityBase中,所有的字段都是全文搜索的,即任何一个字段数据匹配用户键入的值都可能称谓匹配的文档,这是假如需要匹配另一个条件该如何?写代码之初只考虑到一个语言条件,再添加一个参数,具体改一下搜索的方法就可以了,这样一样知识需要改三处,搜索入口(控制器),给该模型添加一个语言字段,具体的搜索方法也要改一下,甚至写索引的方法也都要改。然而有了这个接口,我们只需要实现一个ILanguage继承该接口,然后事具体的模型也继承ILanguage就行。
public interface ILanguage: ICondition
{
string Language { get; set; }
}
在看一下上面LuceneEntityBase中创建且条件的方法,会解析出ICondition中的属性并设置为必须条件
var _conditionDictionary = new Dictionary<string, string>();
var type = GetType();
var andConditionType = andCondition.GetType();
var conditions = type.GetInterfaces().Where(t => typeof(ICondition).IsAssignableFrom(t) && t!= typeof(ICondition))
.SelectMany(t => t.GetProperties() /*t.GetInterfaceMap(t).InterfaceMethods*/)
.Select(t => t.Name);
foreach (var condition in conditions)
{
if (!_conditionDictionary.ContainsKey(condition))
{
_conditionDictionary.Add(condition, andConditionType.GetProperty(condition).GetValue(andCondition)?.ToString() ?? string.Empty);
}
}
实例之三国人物
用上面封装后的类建立了一个简易的搜索示例
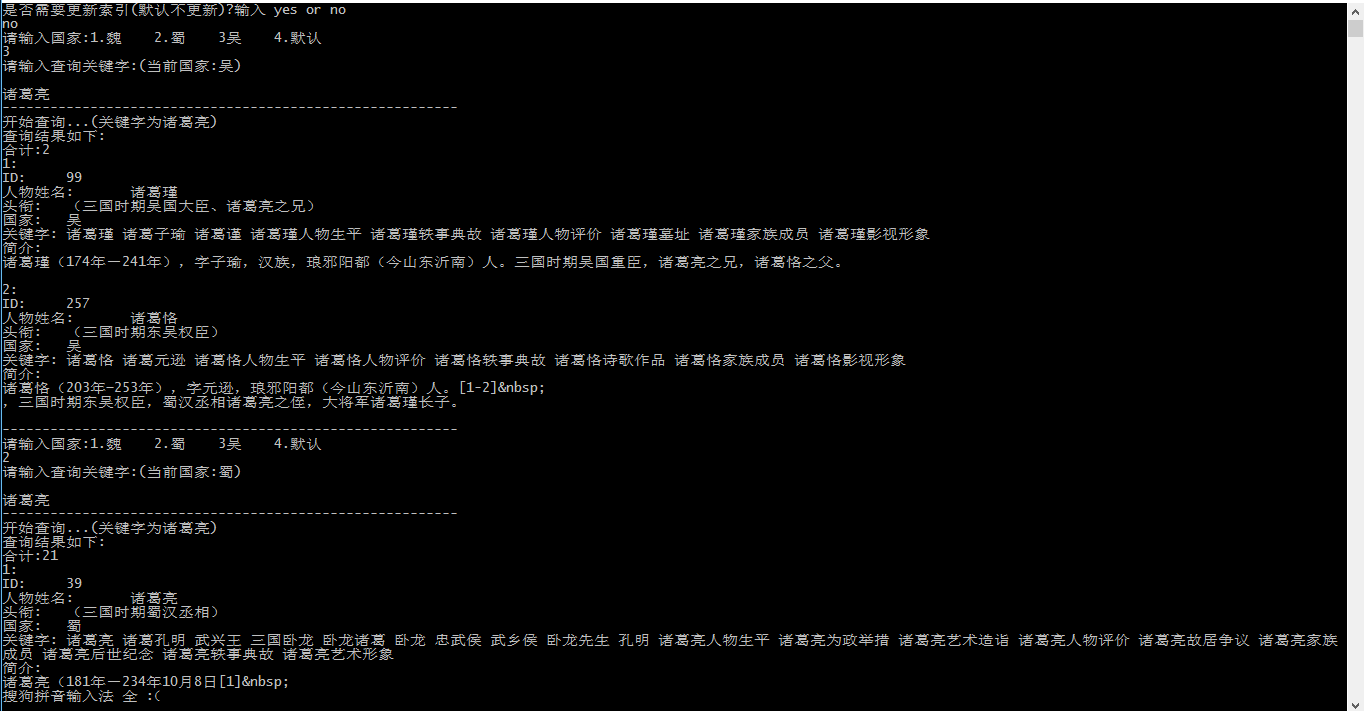
核心代码只有以下三部分,数据的话都爬虫字自百度百科
public class Figure : Lyrewing.Search.LuceneEntityBase, ICountry
{
[Indexer(true,true)]
public string Country { get; set; }
[Indexer(true,true)]
public string FigureName { get; set; }
/// <summary>
/// 称谓
/// </summary>
[Indexer(true,true)]
public string Appellation { get; set; }
/// <summary>
/// 关键字
/// </summary>
[Indexer(true,true)]
public string KeyWords { get; set; }
public IEnumerable<Figure> Search(string searchText, int page, int pageSize, object condition = null)
{
return Search<Figure>(searchText, page, pageSize, condition);
}
}
public interface ICountry : ICondition
{
string Country { get; set; }
}
using (var luceneDB = new LuceneDBIndexer())
{
luceneDB.AddRange(Figures);
}
var seacher = new Figure();
var result = seacher.Search(key, , , country != Country.默认 ? new { Country = country.ToString() } : null);
小结:
通过这次从lucene的踩坑,到lucene的重构,以及代码的一些思考,发现过程是艰辛的,代码现在也不是完美的,lucene的一些其他复杂的查询也没有加进去,但是从这个过程来说对自己来说是值得的,依稀记得实习的时候以为老师讲过的一句话,貌似高三语文老师也讲过哈,信达雅,但是这个过程是不易的,还需要更多的学习和挑战!
Lucene的使用与重构的更多相关文章
- lucene学习-3 - 代码重构
内容就是标题了.是要重构下上一节的代码,大体上按如下的思路: 功能拆分: 创建必要的工具类: 两个工具类StringUtils和TxtUtils. StringUtils,主要是获取当前系统的换行符: ...
- Lucene核心--构建Lucene搜索(上篇,理论篇)
2.1构建Lucene搜索 2.1.1 Lucene内容模型 一个文档(document)就是Lucene建立索引和搜索的原子单元,它由一个或者多个字段(field)组成,字段才是Lucene的真实内 ...
- Lucene 源码分析之倒排索引(二)
本文以及后面几篇文章将讲解如何定位 Lucene 中的倒排索引.内容很多,唯有静下心才能跟着思路遨游. 我们可以思考一下,哪个步骤与倒排索引有关,很容易想到检索文档一定是要查询倒排列表的,那么就从此处 ...
- lucene学习教程
1Lucene的介绍 ①Lucene是什么: 是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎 ②Lu ...
- Lucene 4.0 正式版发布,亮点特性中文解读[转]
http://blog.csdn.net/accesine960/article/details/8066877 2012年10月12日,Lucene 4.0正式发布了(点击这里下载最新版),这个版本 ...
- lucene实现初级搜索引擎
一.系统设计 搜索引擎项目代码主要分为三个部分,第一部分是构建索引,全文检索:第二部分是输入问题,对问题进行分词.提取关键词.关键词扩展:第三部分是将搜索结果输出到GUI图形用户界面. 二.搜索引擎 ...
- 万亿级日志与行为数据存储查询技术剖析(续)——Tindex是改造的lucene和druid
五.Tindex 数果智能根据开源的方案自研了一套数据存储的解决方案,该方案的索引层通过改造Lucene实现,数据查询和索引写入框架通过扩展Druid实现.既保证了数据的实时性和指标自由定义的问题,又 ...
- lucene LZ4 会将doc存储在一个chunk里进行Lz4压缩 ES的_source便如此
默认情况下,Elasticsearch 用 JSON 字符串来表示文档主体保存在 _source 字段中.像其他保存的字段一样,_source 字段也会在写入硬盘前压缩.The _source is ...
- Lucene 查询原理 传统二级索引方案 倒排链合并 倒排索引 跳表 位图
提问: 1.倒排索引与传统数据库的索引相比优势? 2.在lucene中如果想做范围查找,根据上面的FST模型可以看出来,需要遍历FST找到包含这个range的一个点然后进入对应的倒排链,然后进行求并集 ...
随机推荐
- springboot 获取hibernate 的 SessionFactory
注入bean package cn.xiaojf; import cn.xiaojf.today.data.rdb.repository.RdbCommonRepositoryImpl; import ...
- mysql之 mysqldump 备份恢复详解
mysqldump是MySQL用于转存储数据库的客户端程序.转储包含创建表和/或装载表的SQL语句 ,用来实现轻量级的快速迁移或恢复数据库,是mysql数据库实现逻辑备份的一种方式. mysqldum ...
- LINUX 硬盘分区及文件系统
一,top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器. 1. 第一行是任务队列信息 2. 第二.三行为进程和CPU的信息 3. 第 ...
- 微信小程序 获取OpenId
微信小程序 官方API:https://mp.weixin.qq.com/debug/wxadoc/dev/api/ 首先 以下代码是 页面加载请求用户 是否同意授权 同意之后 用code 访问 微信 ...
- 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- mysql之 mysql 5.6不停机主从搭建(一主一从基于GTID复制)
环境说明:版本 version 5.6.25-log 主库ip: 10.219.24.25从库ip:10.219.24.22os 版本: centos 6.7已安装热备软件:xtrabackup 防火 ...
- Akka(7): FSM:通过状态变化来转换运算行为
在上篇讨论里我们提到了become/unbecome.由于它们本质上是堆栈操作,所以只能在较少的状态切换下才能保证堆栈操作的协调及维持程序的清晰逻辑.对于比较复杂的程序流程,Akka提供了FSM:一种 ...
- HTML中那些不常用标签
先思考一个问题:为什么H5里面又多了那么多看似没用的标签? 我们知道,<div>能干百分之99的标签能干的事,而标签的主要作用是用来包裹内容,只要把基本内容都包含进去不就好了??胡闹!不带 ...
- Thinkphp中的内置标签用法
Thinkphp中的内置标签有:Volist,Foreach,For,Switch,比较标签,范围判断标签,IF,Present,Empty,Defined,Assign,Define,标签嵌套,im ...
- iOS内购图文流程(2017)
什么是内购? 只要在iPhone App上购买的不是实物产品(也就是虚拟产品如qq币.虎牙币.电子书......) 都需要走内购流程,苹果这里面抽走三成. 使用内购需要走的流程. 1,填写协议,税 ...