漫谈未来的HDFS
前面我们提到的HDFS,了解了HDFS的特性和架构。HDFS能够存储TB甚至PB规模的数据是有前提的,首先数据要以大文件为主,其次NameNode的内存要足够大。对HDFS有所了解的同学肯定都知道,NameNode是HDFS的存储着整个集群的元数据信息,比如所有文件和目录信息等等。而且当元数据信息较多时,NameNode的启动会变得很慢,也比较容易触发GC操作。显然当数据到了一定的量级,元数据管理会成为HDFS的一个瓶颈,其实这也是为什么说它适合存储大文件的原因。如果解决了元数据管理的问题,其实HDFS是可以支撑海量小文件的。
终于到了本篇文章的重头戏:Ozone,Ozone是Hortonworks基于HDFS实现的一个对象存储服务,旨在基于HDFS的DataNode存储,支持更大规模的数据对象存储,支持各种对象大小并且拥有HDFS的可靠性,一致性和可用性,详情请看Hadoop的Jira HDFS-7240。经过这么长时间的发展和激烈的名称讨论之后最终会命名为HDDS(Hadoop Distributed Data Store)详见Jira HDFS-10419。
那么Ozone是如何解决HDFS的现有问题的呢?
Ozone的主旨就是 Scaling HDFS(缩放HDFS)。缩放HDFS即针对HDFS当前存在的问题:NameNode元数据管理瓶颈进行处理,一方面减轻NameNode的压力,一方面抽象另外一层映射保证数据的快速读取和写入。
HDFS目前的分层如下:
- A namespace layer(命名空间层) 在NameNode服务中实现
- A block layer(Block块层) 主要在DataNode服务中实现,并且NameNode也会提供一个block management服务。

Ozone的设计就是针对于HDFS目前的分层去缩放相关的功能模块。
命名空间层:
- Scaling NameSpace(缩放命名空间)
- Scaling client/rpc load on NN(缩放NameNode支撑的请求)
- NN startup time(缩短NameNode的启动时间)
Block块层:
- Scaling block namespace(缩放block块的命名空间)
- Scaling block reports(缩放block块向NN的报告请求)
- Scaling Datanode‘s block management(缩放Block块管理层)
解决HDFS现有的问题需要同时从上面两个维度对HDFS进行优化,在其设计论文中简要描述了如何实现命名空间和Block块的缩放工作,比如参考了Ceph的分布式命名空间,或者针对于频繁操作的数据保存到内存的workingSet中,其他数据进行持久化等等。同时抽象一个大小约为2G~16G的block group层叫做container,解决Block块的缩放问题,这里我们可以脑补一下Ceph的PG。
而Ozone最终实现了两个服务来实现上面的解决方案:KSM(Key Space Manager) 和 SCM(Storage Container Manager)
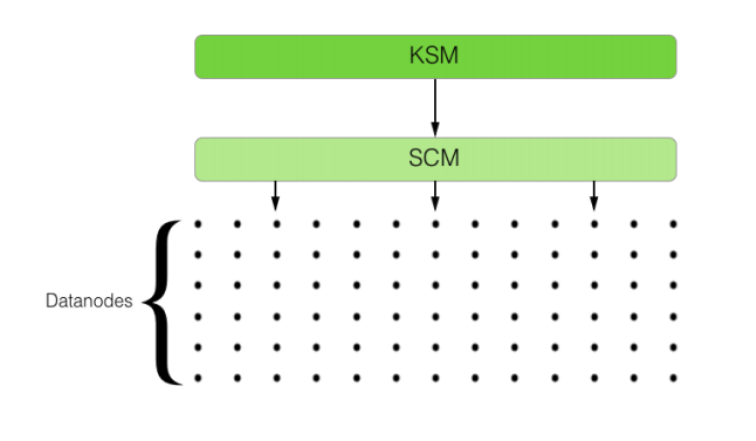
KSM:负责管理的是Ozone命名空间。所有的volume,bucket、key的记录信息都保存在了KSM中。此角色类似于HDFS的NameNode。
SCM:负责管理"Container"对象,Container在逻辑上存储的是block块对象集合。DataNode是以Container的形式来提供存储能力。SCM只负责维护这些Container信息。原先的block report就会变成container report
同时Ozone也实现了一套文件系统接口,Ozone FS,它完全兼容现有的HDFS读写方式,支持Spark,Hive等程序。可以支持方便的将数据从老的HDFS转移到Ozone中。
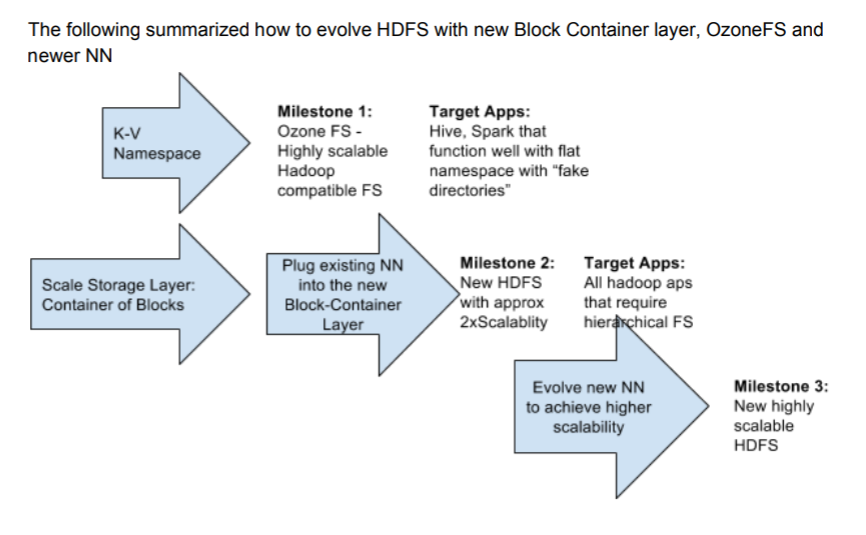
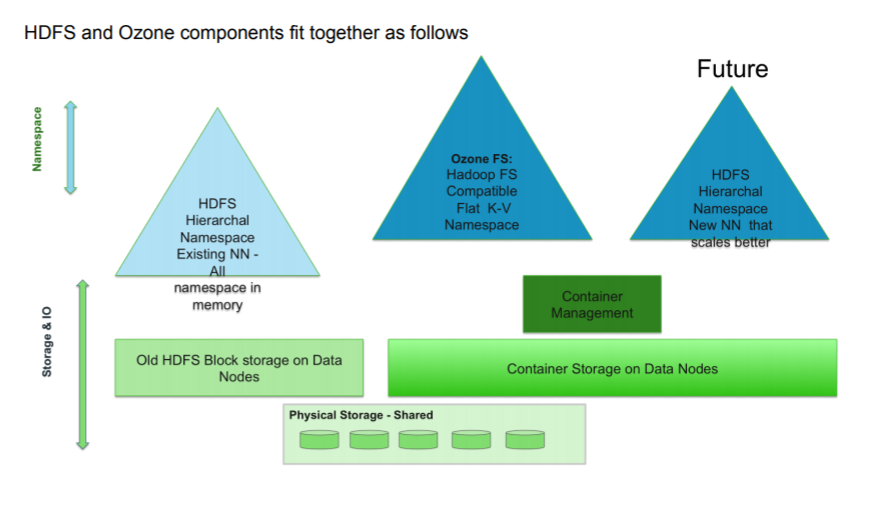
而最终我们期待的更加完美的HDFS应该是这样的。
参考资料:
聊聊HDFS和Ozone的融合
HDFS+Scalability-v2
欢迎关注我:叁金大数据(不稳定持续更新~~~)

漫谈未来的HDFS的更多相关文章
- 【转载】漫谈HADOOP HDFS BALANCER
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,比如集群中添加新的数据节点.当HDFS出现不平衡状况的时候,将引发很多问题,比如MR程序无法很好地利用本地计算的优势,机器之 ...
- 一篇文看懂Hadoop:风雨十年,未来何去何从
本文分为技术篇.产业篇.应用篇.展望篇四部分 技术篇 2006年项目成立的一开始,“Hadoop”这个单词只代表了两个组件——HDFS和MapReduce.到现在的10个年头,这个单词代表的是“核心” ...
- Hadoop 2.x HDFS新特性
Hadoop 2.x HDFS新特性 1.HDFS联邦 2. HDFS HA(要用到zookeeper等,留在后面再讲) 3.HDFS快照 回顾: HDFS两层模型 Namespa ...
- HDFS简介【全面讲解】
http://www.cnblogs.com/chinacloud/archive/2010/12/03/1895369.html [一]HDFS简介HDFS的基本概念1.1.数据块(block)HD ...
- 【Hadoop学习】HDFS中的集中化缓存管理
Hadoop版本:2.6.0 本文系从官方文档翻译而来,转载请尊重译者的工作,注明以下链接: http://www.cnblogs.com/zhangningbo/p/4146398.html 概述 ...
- PLAN :昔日未来
<昔日未来> 1. C语言: 必须要看的书:<C程序设计语言><C标准库> 像<C和指针>,<C专家编程>,<C陷阱>这种书虽很 ...
- 漫谈格兰杰因果关系(Granger Causality)——第一章 野火烧不尽,春风吹又生
2017年7月9日上午6点10分,先师胡三清同志--新因果关系的提出者.植入式脑部电极癫痫治疗法的提出者.IEEE高级会员,因肺癌医治无效于杭州肿瘤医院去世,享年50岁.余蒙先师厚恩数载,一朝忽闻先师 ...
- HDFS 分布式写入问题 AlreadyBeingCreatedException
进行追加文件时出现AlreadyBeingCreatedException错误 堆栈信息大致如下: org.apache.hadoop.ipc.RemoteException(org.apache.h ...
- 漫谈 SLAM 技术(上)
欢迎大家前往腾讯云社区,获取更多腾讯海量技术实践干货哦~ 作者:解洪文 导语 随着最近几年机器人.无人机.无人驾驶.VR/AR的火爆,SLAM技术也为大家熟知,被认为是这些领域的关键技术之一.本文对S ...
随机推荐
- Android GIS开发系列-- 入门季(9) 定位当前的位置
利用MapView定位当前的位置 这里要用到Arcgis中的LocationDisplayManager这个类,由于比较简单.直接上代码: LocationDisplayManager locatio ...
- 如何探测浏览器是否开启js功能
<body> ... ... <script type="text/javascript"> <!-- document.write("He ...
- go语言中的timer 和ticker定时任务
https://mmcgrana.github.io/2012/09/go-by-example-timers-and-tickers.html --------------------------- ...
- Memento - 备忘录模式
定义 在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态.这样以后就可将该对象恢复到原先保存的状态. 案例 比方如今有一个画图系统,我们在Viewer里面画了一些图形,可是在绘 ...
- Lighttpd 插件mod_h264 streaming (mp4)安装
1. 对于安装lighttpd须要支持mp4伪流媒体格式,建议不要到官方下载lighttpd安装文件,到 插件H264 Streaming Module官网,下载已经整合了的安装包 http://h2 ...
- Cacti监控Redis实现过程
Cacti是一套基于PHP,MySQL,SNMP及RRDTool开发的网络流量监測图形分析工具.被广泛的用于对server的运维监控中,Cacti提供了一种插件式的管理.仅仅要按要求写好特定的模板,那 ...
- SpringMVC学习指南-前言
SpringMVC是Spring框架中用于Web应用快速开发的一个模块. SpringMVC基于Spring框架.Servlet和JSP. ------------------------------ ...
- Android学习笔记-保存数据的实现方法2-SharedPreferences
Android下,数据的保存,前面介绍过了,把数据保存到内存以及SD卡上,这次我们就介绍一下,更为常用的采用SharedPreferences的方式来保存数据, 1,得到SharedPreferenc ...
- YII2 的授权(Authorization)
说明:翻译本不是我应该做的,由于我的英语水平实在太差.但由于对YII的兴趣.所以也做一点.同一时候也能显示出我的胆量还是有的...希望不误导您. 由于这里MD语法的内容显示不全.您能够去这里看看. A ...
- java后台修改ZK页面的title
Clients.evalJavaScript("document.title='"+basicDBObject.getString("systemName")+ ...