11scrapy
一. Scrapy基础概念
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量的代码,就能够快速的抓取。Scrapy 使用了 Twisted异步网络框架,可以加快我们的下载速度。
二. 操作
1. 基本操作
1)创建一个scrapy项目
scrapy startproject mySpider
2)生成一个爬虫
scrapy genspider itcast "itcast.cn”
3)提取数据
完善spider,使用xpath等方法
4)保存数据
pipeline中保存数据
2. 完善spdier


3. spdier数据传到pipeline


4. 使用·pipeline

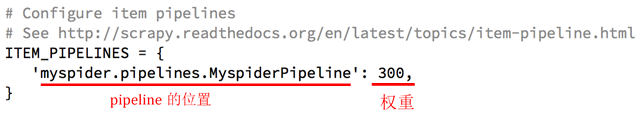
5. 设置log
为了让我们自己希望输出到终端的内容能容易看一些:
我们可以在setting中设置log级别
在setting中添加一行(全部大写):LOG_LEVEL = "WARNING”
默认终端显示的是debug级别的log信息
三. 实行翻页操作
1. 获取地址,使用scrapy.Request方法

需要传递数据时,可以在方法中传递meta:
yield scrapy.Request(next_page_url,callback=self.parse,meta=…)
dont_filter:让scrapy不会过滤当前url
四. 定义Item
1. 方法

2. 实例


3. 在不同的解析函数中传递参数
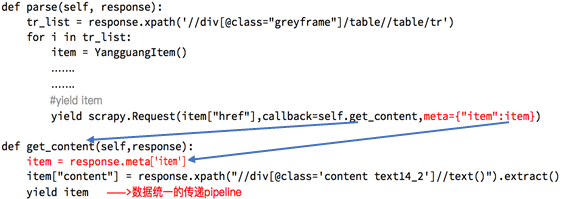
五. 深入pipeline

可以将一些需要初始化的数值添加在open_spider方法中
而close_spider可以做一些收尾工作
六. CrawlSpider
1. 功能
1)我们把满足某个条件的url地址传给rules,同时能够指定callback函数。不需要手动去找下一页的url地址,达到简化代码的目的
2)生成CrawlSpider的命令
scrapy genspider –t crawl 项目名 “域名”
2. 实例
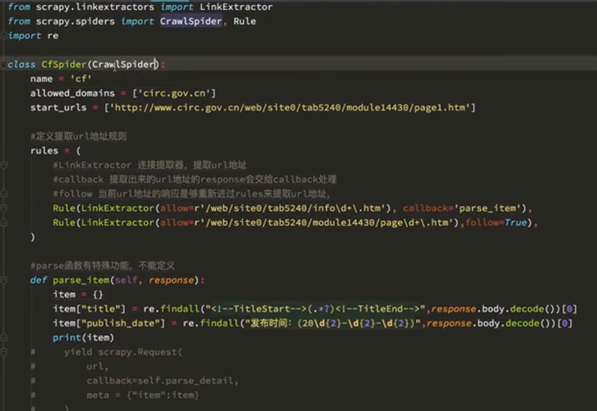
rules内的几个参数:
1) LinkExtractor 连接提取器,提取url地址
2) callback 提取出来的url地址的response会交给callback来处理
3) follow 当前url地址的响应是否重新进rules来提取url地址
3. 注意点

七. Scrapy模拟登录
1. 携带cookie登录
1)直接携带cookie,在浏览器登录之后获取检查里边cookies的值
2)找到发送post请求的url地址,带上信息,发送请求
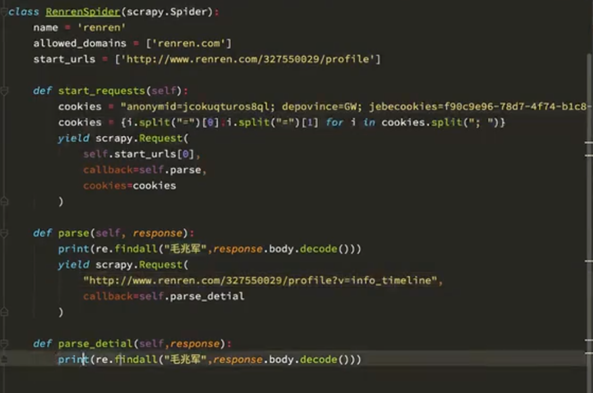
可以在settings里边添加参数【COOKIES_DEBUG=True】观察cookies的传递过程。
不能把cookies放在headers中
2. 使用FormRequest
1) scrapy.FormRequest(url,formdata={},callback) formdata请求体
2) formdata里边的数据,可以试着在浏览器输入用户名和密码之后,在session的Headers里边找到formdata,接着在Elements中查找对应的组件

3)示例

3. 自动寻找Form表单中action的url
1) scrapy.FormRequest.from_response(response,formdata={},callback)
2) 示例

八. 案例分析
1. 贴吧爬虫
1.1 补充不完整的链接
注意:需要导入import urllib
通过urljoin方法自动把链接补全
1.2 对图片解码以及翻页时处理内容覆盖的问题
1) 图片解码:需要import requests
item["img_list"] = [requests.utils.unquote(i).split("src=")[-1] for i in item["img_list"]]
2) 翻页使用extend()来处理
item["img_list"].extend(response.xpath("//img[@class='BDE_Image']/@src").extract())
1.3 spider下的tb.py完整代码
import scrapy
import urllib
import requests
class TbSpider(scrapy.Spider):
name = 'tb'
allowed_domains = ['tieba.baidu.com']
start_urls = ['http://tieba.baidu.com/mo/q----,sz@320_240-1-3---2/m?kw=%E6%9D%8E%E6%AF%85&lp=9001']
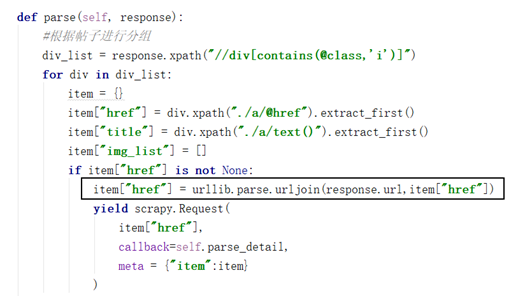
def parse(self, response):
#根据帖子进行分组
div_list = response.xpath("//div[contains(@class,'i')]")
for div in div_list:
item = {}
item["href"] = div.xpath("./a/@href").extract_first()
item["title"] = div.xpath("./a/text()").extract_first()
item["img_list"] = []
if item["href"] is not None:
item["href"] = urllib.parse.urljoin(response.url,item["href"])
yield scrapy.Request(
item["href"],
callback=self.parse_detail,
meta = {"item":item}
)
#列表页的翻页
next_url = response.xpath("//a[text()='下一页']/@href").extract_first()
if next_url is not None:
next_url = urllib.parse.urljoin(response.url,next_url)
yield scrapy.Request(
next_url,
callback=self.parse,
)
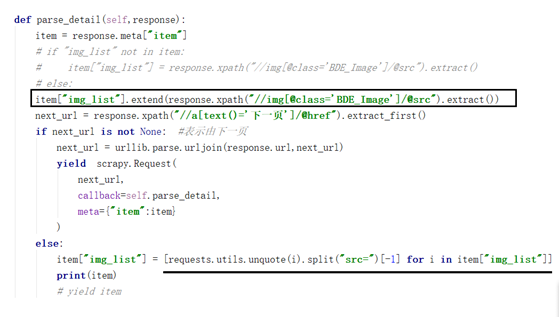
def parse_detail(self,response):
item = response.meta["item"]
# if "img_list" not in item:
#item["img_list"] = response.xpath("//img[@class='BDE_Image']/@src").extract()
# else:
item["img_list"].extend(response.xpath("//img[@class='BDE_Image']/@src").extract())
next_url = response.xpath("//a[text()='下一页']/@href").extract_first()
if next_url is not None: #表示由下一页
next_url = urllib.parse.urljoin(response.url,next_url)
yield scrapy.Request(
next_url,
callback=self.parse_detail,
meta={"item":item}
)
else:
item["img_list"] = [requests.utils.unquote(i).split("src=")[-1] for i in item["img_list"]]
print(item)
# yield item
11scrapy的更多相关文章
- 11-scrapy(递归解析,post请求,日志等级,请求传参)
一.递归解析: 需求:将投诉_阳光热线问政平台中的投诉标题和状态网友以及时间爬取下来永久储存在数据库中 url:http://wz.sun0769.com/index.php/question/que ...
随机推荐
- h.264的POC计算(转载)
转自:http://www.cnblogs.com/TaigaCon/p/3551001.html 本文参考自http://wenku.baidu.com/link?url=ZPF0iSKzwLQg_ ...
- E20170510-hm
prototype n. 原型,雏形,蓝本; omit (omitted) vt. 省略; 遗漏; autonomous adj. 自治的; 有自主权的; fold ...
- hdoj1827
图的强连通,缩点,求个入度为0的点的数量,和入度为0的点集里面最小的花费和. //很死板的题,模板题的一样的- #include<cstdio> #include<queue> ...
- MySQL的分支
1.MariaDB MariaDB数据库管理系统是 MySQL 的一个分支,主要由开源社区在维护,采用GPL授权许可 MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MyS ...
- 天空盒的制作方法 Max来生成天空盒的六张图片
在虚拟现实技术中,需要产品展示,场景漫游等,只要想在内部有一个虚拟的3D天空,那么都要用到天空球:天空球目前基本做法主要有两种:分别是正方形的和球形的. 目前360度全景图主要用的是球形的,针对目前已 ...
- bzoj1257[CQOI2007]余数之和(除法分块)
1257: [CQOI2007]余数之和 Time Limit: 5 Sec Memory Limit: 128 MBSubmit: 6117 Solved: 2949[Submit][Statu ...
- 树的直径初探+Luogu P3629 [APIO2010]巡逻【树的直径】By cellur925
题目传送门 我们先来介绍一个概念:树的直径. 树的直径:树中最远的两个节点间的距离.(树的最长链)树的直径有两种方法,都是$O(N)$. 第一种:两遍bfs/dfs(这里写的是两遍bfs) 从任意一个 ...
- Swift typealias associatedType
使用typealias为常用数据类型起一个别名, 一方面更容易通过别名理解该类型的用途, 另一方面还可以减少日常开发的代码量. typealias使用实例: // 网络请求常用回调闭包 typeali ...
- CoreData修改了数据模型报错 The model used to open the store is incompatible with the one used to create the store
在iOS 6 – Core Data 应用程序的开发过程中, App启动时出现如下异常信息: reason = “The model used to open the store is incompa ...
- [BZOJ2761][JLOI2011]不重复数字 暴力
题目链接:http://www.lydsy.com/JudgeOnline/problem.php?id=2761 直接暴力. #include<cstdio> #include<c ...