Scanner类中的nextToken()方法解读
下面看一下nextToken()方法的源码实现。
1、Java中的控制字符
case ' ': // (Spec 3.6)
case '\t': // (Spec 3.6)
case FF: // (Spec 3.6) 换页符 换页字符
do {
scanChar(); // 操作的是bufferpointer指针的值
} while (ch == ' ' || ch == '\t' || ch == FF);
endPos = bufpointer;
processWhiteSpace();
break;
case LF: // (Spec 3.4)
scanChar();
endPos = bufpointer;
processLineTerminator();
break;
case CR: // (Spec 3.4) \r
scanChar();
if (ch == LF) { // \n
scanChar();
}
endPos = bufpointer;
processLineTerminator();
break;
关于 LF CR 参考https://docs.oracle.com/javase/specs/jls/se7/html/jls-3.html#jls-3.4
关于FF 或者\t 等参考https://docs.oracle.com/javase/specs/jls/se7/html/jls-3.html#jls-3.6
2、Java标识符
有如下规定:
(1)标识符是由字母、数字、下划线、美元($)符号组成的
(2)不能以数字开头
(3)不能是java中的关键字
(4)可以用中文,不会报错,但最好不要用中文
实现代码:
case 'A': case 'B': case 'C': case 'D': case 'E':
case 'F': case 'G': case 'H': case 'I': case 'J':
case 'K': case 'L': case 'M': case 'N': case 'O':
case 'P': case 'Q': case 'R': case 'S': case 'T':
case 'U': case 'V': case 'W': case 'X': case 'Y':
case 'Z':
case 'a': case 'b': case 'c': case 'd': case 'e':
case 'f': case 'g': case 'h': case 'i': case 'j':
case 'k': case 'l': case 'm': case 'n': case 'o':
case 'p': case 'q': case 'r': case 's': case 't':
case 'u': case 'v': case 'w': case 'x': case 'y':
case 'z':
case '$': case '_':
scanIdent();
return;
3、数字的表示
case '0':
scanChar();
if (ch == 'x' || ch == 'X') { // 例如int x = 0x101
scanChar();
skipIllegalUnderscores();
if (ch == '.') {
scanHexFractionAndSuffix(false);
} else if (digit(16) < 0) {
lexError("invalid.hex.number");
} else {
scanNumber(16);
}
} else if (ch == 'b' || ch == 'B') { // 例如int x = 0b101
// java7的新特性二进制字面量
if (!allowBinaryLiterals) {
// source {0} 中不支持二进制文字\n(请使用 -source 7 或更高版本以启用二进制文字)
lexError("unsupported.binary.lit", source.name);
allowBinaryLiterals = true;
}
scanChar();
skipIllegalUnderscores();
if (digit(2) < 0) {
// 二进制数字中必须包含至少一个二进制数
lexError("invalid.binary.number");
} else {
scanNumber(2);
}
} else {
putChar('0');
if (ch == '_') {
int savePos = bufpointer;
do {
scanChar();
} while (ch == '_');
if (digit(10) < 0) {
// 非法下划线
lexError(savePos, "illegal.underscore");
}
}
scanNumber(8);
}
return;
case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
scanNumber(10);
return;
case '.':
scanChar();
if ('0' <= ch && ch <= '9') {
putChar('.');
scanFractionAndSuffix();
} else if (ch == '.') {
putChar('.'); putChar('.');
scanChar();
if (ch == '.') {
scanChar();
putChar('.');
token = ELLIPSIS;
} else {
lexError("malformed.fp.lit");
}
} else {
token = DOT;
}
return;
4、斜杠
case '/':
scanChar();
if (ch == '/') {
do {
scanCommentChar();
} while (ch != CR && ch != LF && bufpointer < buflen);
if (bufpointer < buflen) {
endPos = bufpointer;
processComment(CommentStyle.LINE);
}
break;
} else if (ch == '*') { // 处理文档注释
scanChar();
CommentStyle style;
if (ch == '*') {
style = CommentStyle.JAVADOC;
scanDocComment();
} else {
style = CommentStyle.BLOCK;
while (bufpointer < buflen) {
if (ch == '*') {
scanChar();
if (ch == '/') break;
} else {
scanCommentChar();
}
}
}
if (ch == '/') {
scanChar();
endPos = bufpointer;
processComment(style);
break;
} else {
lexError("unclosed.comment");
return;
}
} else if (ch == '=') {
name = names.slashequals;
token = SLASHEQ;
scanChar();
} else {
name = names.slash;
token = SLASH;
}
return;
5、反斜杠
case '\'':
scanChar();
if (ch == '\'') {
lexError("empty.char.lit");
} else {
if (ch == CR || ch == LF)
lexError(pos, "illegal.line.end.in.char.lit");
scanLitChar();
if (ch == '\'') {
scanChar();
token = CHARLITERAL;
} else {
lexError(pos, "unclosed.char.lit");
}
}
return;
6、双引号
case '\"':
scanChar();
while (ch != '\"' && ch != CR && ch != LF && bufpointer < buflen)
scanLitChar();
if (ch == '\"') {
token = STRINGLITERAL;
scanChar();
} else {
lexError(pos, "unclosed.str.lit");
}
return;
7、默认处理
在Java中,哪些字符组合成为一个Token是通过调用nextToken方法实现的,每调用一次方法就会构造一个Token,而这些Token必然是com.sun.tools.javac.parser.Token中的任何元素之一。其定义如下:
/** An interface that defines codes for Java source tokens
* returned from lexical analysis.
*/
public enum Token implements Formattable {
EOF,
ERROR,
IDENTIFIER, // 如类名、包名、变量名、方法名等
ABSTRACT("abstract"),
ASSERT("assert"),
BOOLEAN("boolean"),
BREAK("break"),
BYTE("byte"),
CASE("case"),
CATCH("catch"),
CHAR("char"),
CLASS("class"),
CONST("const"),
CONTINUE("continue"),
DEFAULT("default"),
DO("do"),
DOUBLE("double"),
ELSE("else"),
ENUM("enum"),
EXTENDS("extends"),
FINAL("final"),
FINALLY("finally"),
FLOAT("float"),
FOR("for"),
GOTO("goto"),
IF("if"),
IMPLEMENTS("implements"),
IMPORT("import"),
INSTANCEOF("instanceof"),
INT("int"),
INTERFACE("interface"),
LONG("long"),
NATIVE("native"),
NEW("new"),
PACKAGE("package"),
PRIVATE("private"),
PROTECTED("protected"),
PUBLIC("public"),
RETURN("return"),
SHORT("short"),
STATIC("static"),
STRICTFP("strictfp"),
SUPER("super"),
SWITCH("switch"),
SYNCHRONIZED("synchronized"),
THIS("this"),
THROW("throw"),
THROWS("throws"),
TRANSIENT("transient"),
TRY("try"),
VOID("void"),
VOLATILE("volatile"),
WHILE("while"),
INTLITERAL,
LONGLITERAL,
FLOATLITERAL,
DOUBLELITERAL,
CHARLITERAL,
STRINGLITERAL,
TRUE("true"),
FALSE("false"),
NULL("null"),
LPAREN("("),
RPAREN(")"),
LBRACE("{"),
RBRACE("}"),
LBRACKET("["),
RBRACKET("]"),
SEMI(";"),
COMMA(","),
DOT("."),
ELLIPSIS("..."),
EQ("="),
GT(">"),
LT("<"),
BANG("!"),
TILDE("~"),
QUES("?"),
COLON(":"),
EQEQ("=="),
LTEQ("<="),
GTEQ(">="),
BANGEQ("!="),
AMPAMP("&&"),
BARBAR("||"),
PLUSPLUS("++"),
SUBSUB("--"),
PLUS("+"),
SUB("-"),
STAR("*"),
SLASH("/"),
AMP("&"),
BAR("|"),
CARET("^"),
PERCENT("%"),
LTLT("<<"),
GTGT(">>"),
GTGTGT(">>>"),
PLUSEQ("+="),
SUBEQ("-="),
STAREQ("*="),
SLASHEQ("/="),
AMPEQ("&="),
BAREQ("|="),
CARETEQ("^="),
PERCENTEQ("%="),
LTLTEQ("<<="),
GTGTEQ(">>="),
GTGTGTEQ(">>>="),
MONKEYS_AT("@"),
CUSTOM;
...
}
调用nextToken生成的字符集合都是一个Name对象,所有的Name对象都存储在Name.Table这个内部类中,可以参考另外一篇文章:
Keyworks会将在Token中所有的元素按照它们的Token.name先转化成Name对象,然后建立Name和Token的对应关系,这个关系保存在Keyworks类的key数组中。
Keywords类定义了如下重要的属性:
/** The names of all tokens. */ private Name[] tokenName = new Name[values().length];
初始化时填充tokenName,代码如下:
private void enterKeyword(String s, Token token) {
Name n = names.fromString(s);
tokenName[token.ordinal()] = n;
if (n.getIndex() > maxKey) {
maxKey = n.getIndex();
}
}
则数组的值为:
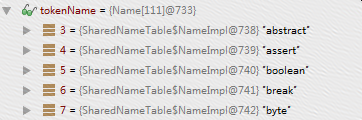
...
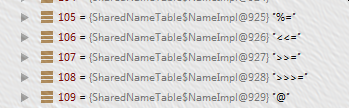
因为有tokenName的枚举常量其ordinal从3开始,到109结束。
然后就可以借助tokenName来完成name到Token的映射了,涉及到的属性如下:
/** * Keyword array. Maps name indices to Token. */ private final Token[] key; /** The number of the last entered keyword. */ private int maxKey = 0;
填充key的属性代码如下:
protected Keywords(Context context) {
// ...
key = new Token[maxKey+1];
for (int i = 0; i <= maxKey; i++) {
key[i] = IDENTIFIER;
}
for (Token t : values()) {
if (t.name != null) {
int oi = t.ordinal();
int ti = tokenName[oi].getIndex();
key[ti] = t;
}
}
}
maxKey值为2905。key中的下标为Name的index值,而值就是Token。其值如下:
2630=abstract
2638=assert
1195=boolean
2644=break
1054=byte
2649=case
2653=catch
1092=char
63=class
2658=const
2663=continue
56=default
2671=do
1173=double
2673=else
2677=enum
2681=extends
2688=final
2693=finally
1153=float
2700=for
2703=goto
2707=if
2709=implements
2719=import
2725=instanceof
1115=int
2735=interface
1135=long
2744=native
2750=new
2753=package
2760=private
2767=protected
2776=public
2782=return
1072=short
2788=static
2794=strictfp
51=super
2802=switch
2808=synchronized
47=this
2820=throw
2825=throws
2831=transient
2840=try
1219=void
2843=volatile
2851=while
2856=true
2860=false
2865=null
2869=(
2870=)
2871={
2872=}
2873=[
2874=]
45=;
44=,
43=.
2875=...
2878==
2598=>
2597=<
2574=!
2569=~
2879=?
2880=:
2603===
2599=<=
2601=>=
2605=!=
2607=&&
2609=||
2570=++
2572=--
2568=+
1=-
46=*
0=/
2587=&
2588=|
2589=^
2586=%
2590=<<
2592=>>
2594=>>>
2881=+=
2883=-=
2885=*=
3=/=
2887=&=
2889=|=
2891=^=
2893=%=
2895=<<=
2898=>>=
2901=>>>=
2905=@
Scanner类中的nextToken()方法解读的更多相关文章
- Java Scanner类中next()和nextLine()方法的区别
今天在练习中遇到了调用Scanner类中的nextLine()输入字符串自动跳过的问题,在博客上看了两篇解答,原来是nextLine()误认了前面next()输入时的Enter,但还是想了一会儿才弄清 ...
- Java基础之Scanner类中next()与nextLine()方法的区别
java中使用Scanner类实现数据输入十分简单方便,Scanner类中next()与nextLine()都可以实现字符串String的获取,所以我们会纠结二者之间的区别. 其实next()与nex ...
- 12-01 Java Scanner类,Scanner类中的nextLine()产生的换行符问题
分析理解:Scanner sc = new Scanner(System.in); package cn.itcast_01; /* * Scanner:用于接收键盘录入数据. * * 前面的时候: ...
- Java中是否可以调用一个类中的main方法?
前几天面试的时候,被问到在Java中是否可以调用一个类中的main方法?回来测试了下,答案是可以!代码如下: main1中调用main2的主方法 package org.fiu.test; impor ...
- 重写Object类中的equals方法
Object是所有类的父亲,这个类有很多方法,我们都可以直接调用,但有些方法并不适合,例如下面的student类 public class Student { //姓名.学号.年纪 private S ...
- PHP通过反射方法调用执行类中的私有方法
PHP 5 具有完整的反射 API,添加了对类.接口.函数.方法和扩展进行反向工程的能力. 下面我们演示一下如何通过反射,来调用执行一个类中的私有方法: <?php //MyClass这个类中包 ...
- Java String类中的intern()方法
今天在看一本书的时候注意到一个String的intern()方法,平常没用过,只是见过这个方法,也没去仔细看过这个方法.所以今天看了一下.个人觉得给String类中加入这个方法可能是为了提升一点点性能 ...
- Java线程状态及Thread类中的主要方法
要想实现多线程,就必须在主线程中创建新的线程对象. 不论什么线程一般具有5种状态,即创建,就绪,执行,堵塞,终止. 创建状态: 在程序中用构造方法创建了一个线程对象后,新的线程对象便处于新建状态,此时 ...
- [SignalR]在非Hub继承类中使用脚本方法
原文:[SignalR]在非Hub继承类中使用脚本方法 新建一个普通类OutHub,里面包含一个脚本方法OutHubTest. 因为大家知道,若能让脚本调用到的话,必须继承Hub,那怎么实现了?通过G ...
随机推荐
- Git config 配置文件
一.Git已经在你的系统中了,你会做一些事情来客户化你的Git环境.你只需要做这些设置一次:即使你升级了,他们也会绑定到你的环境中.你也可以在任何时刻通过运行命令来重新更改这些设置. Git有一个工具 ...
- URAL1991 The battle near the swamp 2017-04-12 18:07 92人阅读 评论(0) 收藏
The battle near the swamp Gungan: Jar Jar, usen da booma! Jar Jar: What? Mesa no have a booma! Gun ...
- Python学习-14.Python的输入输出(三)
在Python中写文件也是得先打开文件的. file=open(r'E:\temp\test.txt','a') file.write('append to file') file.close() 第 ...
- wp8.1 调用智慧天气SmartWeatherAPI
在调用api应用的过程,我们需要用hmac加密技术,它是一种基于hash的加密算法,通过一个双方共同约定的密钥,在发送message前,对密钥进行了sha散列计算,在生成消息又对此密钥进行了二次加密, ...
- jenkins启动失败,提示Starting Jenkins Jenkins requires Java8 or later, but you are running 1.7.0
# 背景 centos安装jenkins后,先启动jenkins服务,结果报错如下: 但自己明明已经安装了java8的 # 解决方法 既然安装了java8的话,那么证明是jenkins启动的是还是用的 ...
- Java : java.util.ConcurrentModificationException
在删除 List 元素的时候,要用 Iterator,不要直接遍历 List,否则会出现 Fatal Exception: java.util.ConcurrentModificationExcept ...
- Python 开发安卓Android及IOS应用库Kivy安装尝试
Python 开发安卓Android及IOS应用库Kivy安装尝试: 先来看看这货可以用来制作什么应用: Create a package for Windows Create a package f ...
- Writing analyzers
Writing analyzers There are times when you would like to analyze text in a bespoke fashion, either b ...
- canvas绘制五角星详细过程
canvas绘制 <canvas id="straight"></canvas> <script> var canvas = document. ...
- java----session
什么是session? 在WEB开发中,服务器可以为每个用户浏览器创建一个会话对象(session对象),也就是说他是保存在服务端的.注意:一个浏览器独占一个session对象(默认情况下).因此,在 ...