Tensorflow笔记——神经网络图像识别(四)搭建模块化的神经网络八股(正则化,指数衰减学习率,滑动平均等优化)
实战案例:
数据X【x0,x1】为正太分布随机点,
标注Y_,当x0*x0+x1*x1<2时,y_=1(红),否则y_=0(蓝)

建立三个.py文件
1. generateds.py生成数据集
import numpy as np
import matplotlib.pyplot as plt
seed = 2
def generateds():
#基于seed产生随机数
rdm = np.random.RandomState(seed)
#随机数返回200列2行的矩阵,表示300组坐标点(x0,x1)作为输入数据集
X = rdm.randn(300,2)
#如果X中的2个数的平方和<2,y=1,否则y=2
#作为输入数据集的标签(正确答案)
Y_ = [int(x0*x0 + x1*x1 <2) for (x0,x1) in X]
#为方便可视化,遍历Y_中的每个元素,1为红,0为蓝
Y_c = [['red' if y else 'blue'] for y in Y_]
#对数据集X和标签Y进行形状整理,-1表示n,n行2列写为reshape(-1,2)
X = np.vstack(X).reshape(-1,2)
Y_ = np.vstack(Y_).reshape(-1,1)
#print(X)
#print(Y)
#print(Y_c)
return X,Y_,Y_c '''
if __name__ == '__main__':
X,Y_,Y_c=generateds() #用 plt.scatter画出数据集X中的点(x0.x1),Y_c表示颜色
plt.scatter(X[:,0], X[:,1],c=np.squeeze(Y_c))
plt.show()
'''
2. forward.py 前向传播
#coding:utf-8
import tensorflow as tf #定义神经网络的输入、参数和输出,定义前项传播过程
def get_weight(shape, regularizer):
w = tf.Variable(tf.random_normal(shape),dtype=tf.float32)
#把每个w的正则化损失加到总损失losses中
tf.add_to_collection('losses', tf.contrib.layers.l2_regularizer(regularizer)(w))
return w def get_bias(shape):
b=tf.Variable(tf.constant(0.01, shape=shape))
return b #搭建前向传播框架
def forward(x, regularizer): w1 = get_weight([2,11], regularizer)
b1 = get_bias([11])
#(x和w1实现矩阵乘法 + b1)过非线性函数(激活函数)
y1 = tf.nn.relu(tf.matmul(x, w1) + b1) w2 = get_weight([11,1], regularizer)
b2 = get_bias([1])
#输出层不过激活函数
y = tf.matmul(y1, w2) + b2 return y
3. backward.py 反向传播
#coding:utf-8
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import generateds
import forward STEPS = 40000#共进行40000轮
BATCH_SIZE = 30#表示一次为喂入NN多少组数据
LEARNING_RATE_BASE = 0.001#学习率基数,学习率初始值
LEARNING_RATE_DECAY = 0.999#学习率衰减率
REGULARIZER = 0.01#参数w的loss在总losses中的比例,即正则化权重 def backward():
x = tf.placeholder(tf.float32,(None,2))
y_ = tf.placeholder(tf.float32,(None,1)) X,Y_,Y_c = generateds.generateds() y=forward.forward(x, REGULARIZER) global_step = tf.Variable(0, trainable = False) learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,300/BATCH_SIZE,
LEARNING_RATE_DECAY,
staircase = True) #定义损失函数
loss_mse = tf.reduce_mean(tf.square(y-y_))#利用均方误差
loss_total = loss_mse + tf.add_n(tf.get_collection('losses')) #定义反向传播方法:包含正则化
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss_total) with tf.Session() as sess :
init_op = tf.global_variables_initializer()
sess.run(init_op)
for i in range(STEPS):
start =(i*BATCH_SIZE) % 300
end = start + BATCH_SIZE
sess.run(train_step, feed_dict={x:X[start:end], y_:Y_[start:end]})
if i % 2000 == 0:
loss_v = sess.run(loss_total, feed_dict={x:X,y_:Y_})
print('After %d steps, loss if %f '%(i,loss_v)) #xx在-3到3之间步长为0.01,yy在-3到3之间步长为0.01生成二维网格坐标点
xx, yy = np.mgrid[-3:3.01, -3:3:.01]
#将xx,yy拉直,并合并成一个2列的矩阵,得到一个网格坐标点的集合
grid = np.c_[xx.ravel(), yy.ravel()]
#将网格坐标点喂入神经网络,probs为输出
probs = sess.run(y, feed_dict={x:grid})
#将probs的shape调整成xx的样子
probs = probs.reshape(xx.shape) #画出离散点
plt.scatter(X[:,0], X[:,1], c=np.squeeze(Y_c))
#画出probs,0.5的曲线
plt.contour(xx, yy, probs, levels=[.5])
plt.show() if __name__ == '__main__':
backward()
输出:
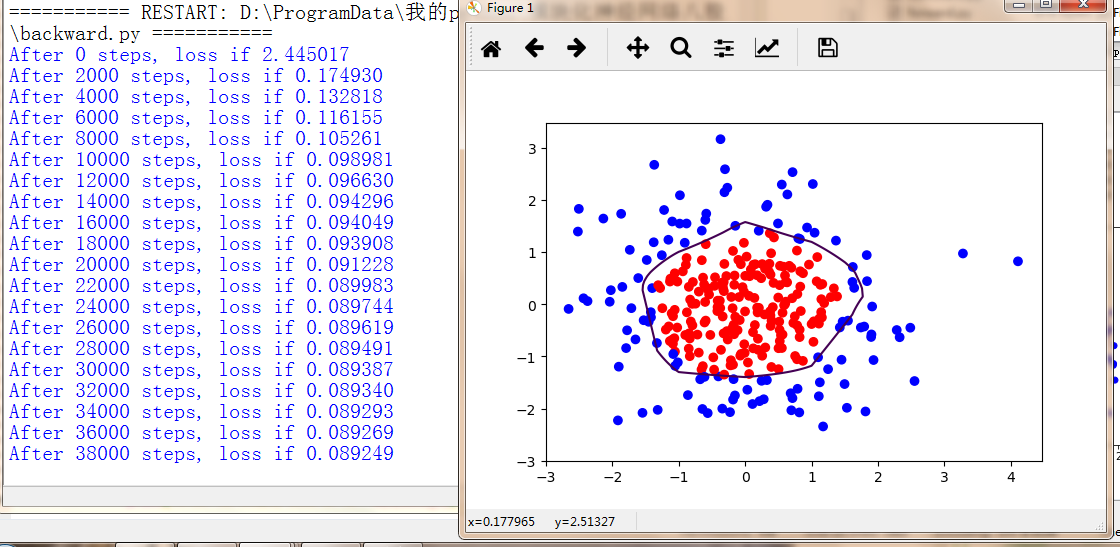
如果对你有帮助,欢迎打赏!

Tensorflow笔记——神经网络图像识别(四)搭建模块化的神经网络八股(正则化,指数衰减学习率,滑动平均等优化)的更多相关文章
- TensorFlow笔记-05-反向传播,搭建神经网络的八股
TensorFlow笔记-05-反向传播,搭建神经网络的八股 反向传播 反向传播: 训练模型参数,在所有参数上用梯度下降,使用神经网络模型在训练数据上的损失函数最小 损失函数:(loss) 计算得到的 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- TensorFlow笔记-07-神经网络优化-学习率,滑动平均
TensorFlow笔记-07-神经网络优化-学习率,滑动平均 学习率 学习率 learning_rate: 表示了每次参数更新的幅度大小.学习率过大,会导致待优化的参数在最小值附近波动,不收敛:学习 ...
- 【tensorflow】】模型优化(一)指数衰减学习率
指数衰减学习率是先使用较大的学习率来快速得到一个较优的解,然后随着迭代的继续,逐步减小学习率,使得模型在训练后期更加稳定.在训练神经网络时,需要设置学习率(learning rate)控制参数的更新速 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现
https://blog.csdn.net/zouxy09/article/details/9993371 自己平时看了一些论文,但老感觉看完过后就会慢慢的淡忘,某一天重新拾起来的时候又好像没有看过一 ...
- tensorflow笔记2(北大网课实战)
1.正则化缓解过拟合 正则化在损失函数中引入模型复杂度指标,利用给w加权值,弱化了训练数据的噪声 一般不会正则化b. 2.matplotlib.pyplot 3.搭建模块化的神经网络八股: 前向传播就 ...
- tensorflow中使用mnist数据集训练全连接神经网络-学习笔记
tensorflow中使用mnist数据集训练全连接神经网络 ——学习曹健老师“人工智能实践:tensorflow笔记”的学习笔记, 感谢曹老师 前期准备:mnist数据集下载,并存入data目录: ...
- TensorFlow笔记-01-开篇概述
人工智能实践:TensorFlow笔记-01-开篇概述 从今天开始,从零开始学习TensorFlow,有相同兴趣的同志,可以互相学习笔记,本篇是开篇介绍 Tensorflow,已经人工智能领域的一些名 ...
- Tensorflow 笔记
TensorFlow笔记-08-过拟合,正则化,matplotlib 区分红蓝点 TensorFlow笔记-07-神经网络优化-学习率,滑动平均 TensorFlow笔记-06-神经网络优化-损失函数 ...
随机推荐
- Codeforces Round #417 (Div. 2) D. Sagheer and Kindergarten(树中判祖先)
http://codeforces.com/contest/812/problem/D 题意: 现在有n个孩子,m个玩具,每次输入x y,表示x孩子想要y玩具,如果y玩具没人玩,那么x就可以去玩,如果 ...
- MySQL事务处理实现方法步骤
需求说明: 案例背景:银行的转账过程中,发生意外是在所难免.为了避免意外而造成不必要的损失,使用事务处理的方式进行处理: A账户现有余额1000元,向余额为200的B账户进行转账500元.可能由于某原 ...
- 递归--练习2--noi6261汉诺塔
递归--练习2--noi6261汉诺塔 一.心得 先把递推公式写出来,会很简单的 二.题目 6261:汉诺塔问题 总时间限制: 1000ms 内存限制: 65536kB 描述 约19世纪末,在欧州 ...
- vSphere Client的拷贝 粘帖 功能
Windows Client OS的情况下, Remote Desktop 自带拷贝/粘帖 功能, 所以一直没在意. 这回用CentOS, 比起vnc viewer , 感觉还是自带的 vSphere ...
- rails5.2新特性--ActiveStorage, 使用80percent/rails-template
看guide,看ruby-China的好贴,看最新版的书上案例. 以下摘自https://ruby-china.org/topics/36666 作者lyfi2003 用户对上传文件的要求体验: 上传 ...
- SNMP:使用net-snmp捕捉trap
管理端:172.18.0.135 win7系统 代理端:172.18.0.212 Debian7.2 前提:代理端已配置snmp,可正常实现用SNMP协议实现系统信息监控 1.管理端下 ...
- Java网络编程和NIO详解9:基于NIO的网络编程框架Netty
Java网络编程和NIO详解9:基于NIO的网络编程框架Netty 转自https://sylvanassun.github.io/2017/11/30/2017-11-30-netty_introd ...
- 位于/var/log目录下的20个Linux日志文件
位于/var/log目录下的20个Linux日志文件[译] from:http://buptguo.com/2014/01/16/linux-var-log-files/ 原文地址:20 Linux ...
- lister.ora配置
SID_LIST_LISTENER = (SID_LIST = (SID_DESC = (SID_NAME = PLSExtProc) (ORACLE_HOME = D:\ ...
- 045——VUE中组件之父组件使用scope定义子组件模板结构
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...