KNN算法——分类部分
1.核心思想
如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。也就是说找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。
下面看一个例子,
一个程序员面试结束后,想想知道是否拿到offer,他在网上找到几个人的工作经历和大概薪资,如下,X为年龄,Y为工资;
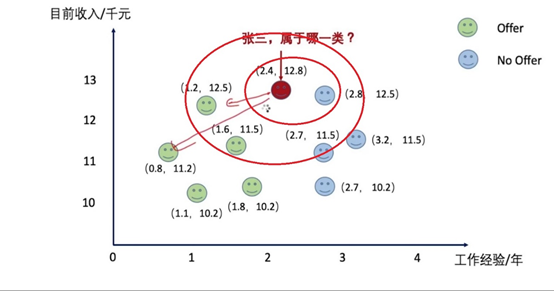
当k取1的时候,我们可以看出距离最近的no offer,因此得到目标点为不被录用。
当k取3的时候,我们可以看出距离最近的三个,分别是有offer 和no offer,根据投票决定 offer的票数较高为2 ,所以被录用。
算法流程
1. 准备数据,对数据进行预处理,常用方法,特征归一化、类别型特征的处理、高维组合特征的处理、组合特征的处理、文本表示模型的模型处理、Word2Vec、图像数据不足时的处理方法
2. 选用合适的数据结构存储训练数据和测试元组,根据模型验证方法,把样本划分不同的训练集和测试集,比如holdout只需要划分为两个部分,交叉验证划分为k个子集,自助法跟着模型来
3. 设定参数,如k的取值,这个涉及到超参数调优的问题,网络搜索、随机搜索、贝叶斯算法等
4.维护一个大小为k的的按距离由大到小的优先级队列,用于存储最近邻训练元组。随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存入优先级队列
5. 遍历训练元组集,计算当前训练元组与测试元组的距离,将所得距离L 与优先级队列中的最大距离Lmax
6. 进行比较。若L>=Lmax,则舍弃该元组,遍历下一个元组。若L < Lmax,删除优先级队列中最大距离的元组,将当前训练元组存入优先级队列。
7. 遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。
8. 测试元组集测试完毕后计算误差率,继续设定不同的k值重新进行训练,最后取误差率最小的k 值。
简单来说,knn算法最重要的是三个要素:K值选择,距离度量,分类决策规则,
K的选择
如k的取值,这个涉及到超参数调优的问题,k的取值对结果会有很大的影响。K值设置过小会降低分类精度,增加模型复杂度;若设置过大,且测试样本属于训练集中包含数据较少的类,则会增加噪声,降低分类效果。通常,K值的设定采用交叉检验的方式(以K=1,K=2,K=3依次进行),K折交叉验证如下:
1) 将全部训练集S分成K个不相交的子集,假设S中的训练样例个数为m,那么每一个子集有m/k个训练样例。
(2) 每次从分好的子集中,选出一个作为测试集,另外k-1个作为训练集。
(3) 根据训练集得到模型。
(4) 根据模型对测试集进行测试,得到分类率。
(5) 计算k次求得的分类率的平均值,作为模型的最终分类率。
以五折交叉验证为例;
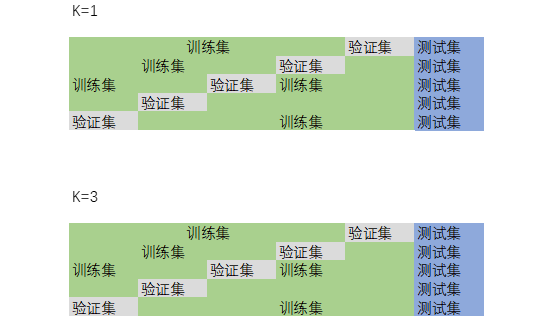
分别得出K=1时的平均分类准确度、K=1时的平均分类准确度……选出最优K值
距离度量
在KNN算法中,常用的距离有三种,分别为曼哈顿距离、欧式距离和闵可夫斯基距离。
距离通式:
当p=1时,称为曼哈顿距离
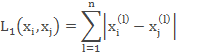
当p=2时,称为欧式距离
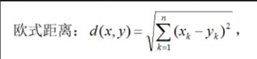
当p=∞时,
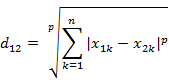
分类决策规则
:
1.多数表决:少数服从多数,即训练集里和预测的样本特征最近的K个样本,预测为里面有最多类别数的类别
2.加权表决:根据各个邻居与测试对象距离的远近来分配相应的投票权重。最简单的就是取两者距离之间的倒数,距离越小,越相似,权重越大,将权重累加,最后选择累加值最高类别属性作为该待测样本点的类别,类似大众评审和专家评审。
这两种确简单直接,在样本量少,样本特征少的时候有效,只适合数据量小的情况。因为我们经常碰到样本的特征数有上千以上,样本量有几十万以上,如果我们这要去预测少量的测试集样本,算法的时间效率很成问题。因此,这个方法我们一般称之为蛮力实现。比较适合于少量样本的简单模型的时候用。一个是KD树实现,一个是球树实现。
KNN算法——分类部分的更多相关文章
- KNN算法[分类算法]
kNN(k-近邻)分类算法的实现 (1) 简介: (2)算法描述: (3) <?php /* *KNN K-近邻方法(分类算法的实现) */ /* *把.txt中的内容读到数组中保存,$file ...
- Opencv学习之路—Opencv下基于HOG特征的KNN算法分类训练
在计算机视觉研究当中,HOG算法和LBP算法算是基础算法,但是却十分重要.后期很多图像特征提取的算法都是基于HOG和LBP,所以了解和掌握HOG,是学习计算机视觉的前提和基础. HOG算法的原理很多资 ...
- 用KNN算法分类CIFAR-10图片数据
KNN分类CIFAR-10,并且做Cross Validation,CIDAR-10数据库数据如下: knn.py : 主要的试验流程 from cs231n.data_utils import lo ...
- 吴裕雄--天生自然python机器学习实战:K-NN算法约会网站好友喜好预测以及手写数字预测分类实验
实验设备与软件环境 硬件环境:内存ddr3 4G及以上的x86架构主机一部 系统环境:windows 软件环境:Anaconda2(64位),python3.5,jupyter 内核版本:window ...
- 机器学习【三】k-近邻(kNN)算法
一.kNN算法概述 kNN算法是用来分类的,其依据测量不同特征值之间的距离,其核心思想在于用距离目标最近的k个样本数据的分类来代表目标的分类(这k个样本数据和目标数据最为相似).其精度高,对异常值不敏 ...
- 数据挖掘之分类算法---knn算法(有matlab例子)
knn算法(k-Nearest Neighbor algorithm).是一种经典的分类算法.注意,不是聚类算法.所以这种分类算法 必然包括了训练过程. 然而和一般性的分类算法不同,knn算法是一种懒 ...
- KNN邻近分类算法
K邻近(k-Nearest Neighbor,KNN)分类算法是最简单的机器学习算法了.它采用测量不同特征值之间的距离方法进行分类.它的思想很简单:计算一个点A与其他所有点之间的距离,取出与该点最近的 ...
- kNN算法:K最近邻(kNN,k-NearestNeighbor)分类算法
一.KNN算法概述 邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它 ...
- [Python]基于K-Nearest Neighbors[K-NN]算法的鸢尾花分类问题解决方案
看了原理,总觉得需要用具体问题实现一下机器学习算法的模型,才算学习深刻.而写此博文的目的是,网上关于K-NN解决此问题的博文很多,但大都是调用Python高级库实现,尤其不利于初级学习者本人对模型的理 ...
随机推荐
- 初探js
第一章 1.JS的位置 1-1.行间 1-2.内嵌 1-3.外联 2.JS的标签位置 页面中的代码在一般情况下会按从上到下的顺序,从左往右的顺序执行. 因此当JS放在了元素上面的时候,就不能正常执 ...
- WPF中MVVM模式的 Event 处理
WPF的有些UI元素有Command属性可以直接实现绑定,如Button 但是很多Event的触发如何绑定到ViewModel中的Command呢? 答案就是使用EventTrigger可以实现. 继 ...
- 嵌套函数中的this
function countDown(){ var self = this; var doWork = function(){ console.log(this);//window console.l ...
- Android开发小知识
修改Android app图标(Android Studio) 1. res\drawable 放置icon.png(此图片是你需要修改的图标); 2. 修改AndroidManifest.xml ...
- 转载来自朱小厮的博客的NIO相关基础篇
用户空间以及内核空间概念 我们知道现在操作系统都是采用虚拟存储器,那么对32位操作系统而言,它的寻址空间(虚拟存储空间)为4G(2的32次方).操心系统的核心是内核,独立于普通的应用程序,可以访问受保 ...
- POJ 1988 Cube Stacking (种类并查集)
题目地址:POJ 1988 这道题的查找合并的方法都能想的到,就是一点没想到,我一直天真的以为查询的时候,输入后能立即输出,这种话在合并的时候就要所有的结点值都要算出来,可是经过路径压缩之后,没办法所 ...
- Method and apparatus for training a memory signal via an error signal of a memory
Described herein is a method and an apparatus for training a memory signal via an error signal of a ...
- Leetcode 238 Product of Array Except Self 递推
给出一个数组 nums[i](i = 0,1,...,n-1) 输出数组output[i]满足 output[i] = nums[0] * num[1] * num[2] *..*num[i-1] ...
- ehcache hibernate4整合问题
当在原有hibernate使用ehcache缓存的项目中加入ehcache时,报如下错误时 Caused by: org.hibernate.service.spi.ServiceException: ...
- 从零开始学习 asp.net core 2.1 web api 后端api基础框架(四)-创建Controller
原文:从零开始学习 asp.net core 2.1 web api 后端api基础框架(四)-创建Controller 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog ...