【Tool】 深度学习常用工具
1. caffe 网络结构可视化
http://ethereon.github.io/netscope/quickstart.html
将网络结构复制粘贴到左侧的编辑框,按Shift+Enter就可以显示出你的网络结构
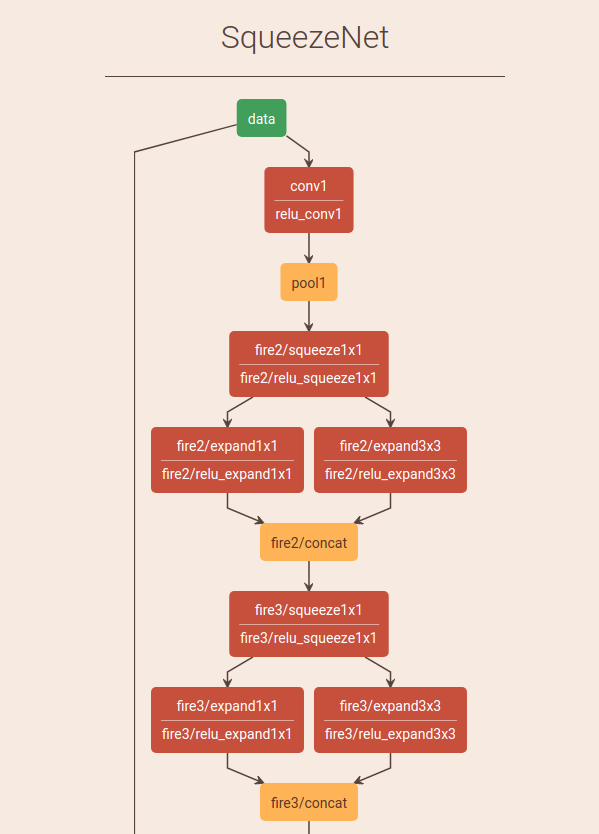
2. caffe计算图片的均值
使用caffe自带的均值计算工具
./build/tools/compute_image_mean ROOT_OF_IMAGES ROOT_TO_PLACE_MEAN_FILE
第一个参数:需要计算均值的图片路径,格式为LMDB训练数据
第二个参数:计算出来的结果保存路径
./build/tools/compute_image_mean project/SqueezeNet/SqueezeNet_v1.0/test_lmdb project/SqueezeNet/SqueezeNet_v1.0/test_mean.binaryproto
python格式的均值计算
先用LMDB格式数据,计算出二进制格式均值,然后转换成python格式均值
#!/usr/bin/env python
import numpy as np
import sys,caffe if len(sys.argv)!=3:
print "Usage: python convert_mean.py mean.binaryproto mean.npy"
sys.exit() blob = caffe.proto.caffe_pb2.BlobProto()
bin_mean = open( sys.argv[1] , 'rb' ).read()
blob.ParseFromString(bin_mean)
arr = np.array( caffe.io.blobproto_to_array(blob) )
npy_mean = arr[0]
np.save( sys.argv[2] , npy_mean )
脚本保存为convert_mean.py
调用格式:
sudo python convert_mean.py mean.binaryproto mean.npy
mean.npy是我们需要的python格式二进制文件
3. 可视化训练过程中的 training/testing loss
- NVIDIA-DIGITS: caffe训练可视化工具(数据准备,模型选择,学习曲线可视化,多GPU训练
- 训练时 --solver=solver.ptototxt 2>&1 | tee train.log, 然后使用 ./tools/extra/parse_log.py train.log将其转为两个csv 文件分别包括train loss和test loss, 然后使用以下脚本画图:
import pandas as pd
from matplotlib import *
from matplotlib.pyplot import * train_log = pd.read_csv("./lenet_train.log.train")
test_log = pd.read_csv("./lenet_train.log.test")
_, ax1 = subplots(figsize=(15, 10))
ax2 = ax1.twinx()
ax1.plot(train_log["NumIters"], train_log["loss"], alpha=0.4)
ax1.plot(test_log["NumIters"], test_log["loss"], 'g')
ax2.plot(test_log["NumIters"], test_log["acc"], 'r')
ax1.set_xlabel('iteration')
ax1.set_ylabel('train loss')
ax2.set_ylabel('test accuracy')
savefig("./train_test_image.png") #save image as png
【Tool】 深度学习常用工具的更多相关文章
- Linux下深度学习常用工具的安装
.Matlab 2015 64bit 的安装 (一)安装包下载 百度网盘: [https://pan.baidu.com/s/1gf9IeCN], 密码: 4gj3 (二)Vmware 使用Windo ...
- 深度学习标注工具 LabelMe 的使用教程(Windows 版本)
深度学习标注工具 LabelMe 的使用教程(Windows 版本) 2018-11-21 20:12:53 精灵标注助手:http://www.jinglingbiaozhu.com/ LabelM ...
- 深度学习常用数据集 API(包括 Fashion MNIST)
基准数据集 深度学习中经常会使用一些基准数据集进行一些测试.其中 MNIST, Cifar 10, cifar100, Fashion-MNIST 数据集常常被人们拿来当作练手的数据集.为了方便,诸如 ...
- 卷积神经网络CNN与深度学习常用框架的介绍与使用
一.神经网络为什么比传统的分类器好 1.传统的分类器有 LR(逻辑斯特回归) 或者 linear SVM ,多用来做线性分割,假如所有的样本可以看做一个个点,如下图,有蓝色的点和绿色的点,传统的分类器 ...
- python数据可视化、数据挖掘、机器学习、深度学习 常用库、IDE等
一.可视化方法 条形图 饼图 箱线图(箱型图) 气泡图 直方图 核密度估计(KDE)图 线面图 网络图 散点图 树状图 小提琴图 方形图 三维图 二.交互式工具 Ipython.Ipython not ...
- 包含深度学习常用框架的Docker环境
相关的代码都在Github上,请参见我的Github,https://github.com/lijingpeng/deep-learning-notes 敬请多多关注哈~~~ All in one d ...
- 深度学习开源工具——caffe介绍
本页是转载caffe的一个介绍,之前的页面图都down了,更新一下. 目录 简介 要点记录 提问 总结 简介 报告时间是北京时间 12月14日 凌晨一点到两点,主讲人是 Caffe 团队的核心之一 E ...
- 深度学习常用的数据源(MNIST,CIFAR,VOC2007系列数据)
MINIST手写数据集 压缩包版: http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz http://yann.lecun.com/ ...
- 深度学习可视化工具--tensorboard的使用
tensorboard的使用 官方文档 # writer.add_scalar() # 添加标量 """ Args: tag (string): Data identif ...
随机推荐
- 树状数组||归并排序求逆序对+离散化 nlogn
我好咸鱼. 归并排序之前写过,树状数组就是维护从后往前插入,找比现在插入的数大的数的数量. 如果值域大,可以离散化 #include <cstdio> #include <cstri ...
- linux github 添加ssh
1.本地生成key, xxx 是github 的账号, 执行下面命令一路下一步 ssh-keygen -t rsa -C "xxx" 2.复制下面的public key 到git ...
- GNU/Linux分支图
- Hadoop安装和使用
1.安装 1.1.下载hadoop-2.5.1.tar.gz 1.2.解压至安装目录 tar -zxv -f hadoop-2.5.1.tar.gz -C ../soft/ 1.3.配置hadoop相 ...
- maven引入jsp相关依赖
<!--引入Servlet开始--> <dependency> <groupId>javax.servlet</groupId> <artifac ...
- oracle schema彻底理解
oracle中的Schema简析 在一个数据库中可以有多个应用的数据表,这些不同应用的表可以放在不同的schema之中,同时,每一个schema对应一个用户,不同的应用可以以不同的用户连接数据库,这样 ...
- Tween动画TranslateAnimation细节介绍
Tween动画有下面这几种: Animation 动画 AlphaAnimation 渐变透明度 RotateAnimation 画面旋转 ScaleAnimation 渐变尺寸缩放 Transl ...
- 0x04 二分
二分.三分其实没什么.. 但是真心觉得市面上的朴素二分打法千奇百怪,假如是像我的标程应该是比较稳妥的,然而poj2018那题(前缀和又想起来了)是向下取整,精度有点问题(经常拍出一些什么xxx.999 ...
- 关于QObject类的一些理解
QRunnable并没有继承自QObject,所以它和其他QObject组件的通信不能使用传统的信号和槽,要是用信号和槽我们必须将其继承自QObject自动的添加 QThread的退出最好用exit( ...
- php的分页代码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...