storm如何保证at least once语义?
背景
前期收到的问题:
1、在Topology中我们可以指定spout、bolt的并行度,在提交Topology时Storm如何将spout、bolt自动发布到每个服务器并且控制服务的CPU、磁盘等资源的?
2、Storm处理消息时会根据Topology生成一棵消息树,Storm如何跟踪每个消息、如何保证消息不丢失以及如何实现重发消息机制?
本篇看看storm是通过什么机制来保证消息至少处理一次的语义的,并回答第2个问题。
storm中的一些原语##
要说明上面的问题,得先了解storm中的一些原语,比如:

tuple和message
在storm中,消息是通过tuple来抽象表示的,每个tuple知道它从哪里来,应往哪里去,包含了其在tuple-tree(如果是anchored的话)或者DAG中的位置,等等信息。spout
spout充当了tuple的发送源,spout通过和其它消息源,比如kafka交互,将消息封装为tuple,发送到流的下游。bolt
bolt是tuple的实际处理单元,通过从spout或者另一个bolt接收tuple,进行业务处理,将自己加入tuple-tree(通过在emit方法中设置anchors)或DAG,然后继续将tuple发送到流的下游。acker
acker是一种特殊的bolt,其接收来自spout和bolt的消息,主要功能是追踪tuple的处理情况,如果处理完成,会向tuple的源头spout发送确认消息,否则,会发送失败消息,spout收到失败的消息,根据配置和自定义的情况会进行消息的丢弃、重放处理。
spout、bolt、acker的关系
- spout将tuple发送给流的下游的bolts.
- bolt收到tuple,处理后发送给下游的bolts.
- spout向acker发送请求ack的消息.
- bolt向acker发送请求ack的消息.
- acker向bolt和spout发送确认ack的消息.
简单的关系如下所示:

上图展示了spout、bolts等形成了一个DAG,如何追踪这个DAG的执行过程,就是storm保证仅处理一次消息的语义的机制所在。
storm如何追踪消息(tuple)的处理##

spout在调用emit/emitDirect方法发送tuple时,会以单播或者广播的方式,将消息发送给流的下游的component/task/bolt,如果配置了acker,那么会在每次emit调用之后,向acker发送请求ack的消息:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; spout向acker发送请求ack消息
;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; rooted?表示是否设置了acker
(if (and rooted?
(not (.isEmpty out-ids)))
(do
(.put pending root-id [task-id
message-id
{:stream out-stream-id :values values}
(if (sampler) (System/currentTimeMillis))])
(task/send-unanchored task-data
;;表示这是一个流初始化的消息
ACKER-INIT-STREAM-ID
;;将下游组件的out-id和0组成一个异或链,发送给acker用于追踪
[root-id (bit-xor-vals out-ids) task-id]
overflow-buffer))
;; 如果没有配置acker,则调用自身的ack方法
(when message-id
(ack-spout-msg executor-data task-data message-id
{:stream out-stream-id :values values}
(if (sampler) 0) "0:")))
从上面的代码可以看出,每次emit tuple后,spout会向acker发送一个流ID为ACKER-INIT-STREAM-ID的消息,用于将DAG或者tuple-tree中的节点信息交给acker,acker会利用这个信息来追踪tuple-tree或DAG的完成。
而spout调用emit/emitDirect方法,将tuple发到下游的bolts,也同时会发送用于追踪DAG完成情况的信息:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;; spout向流的下游emit消息
;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(let [tuple-id (if rooted?
;; 如果有acker,tuple的MessageId会包含一个<root-id,id>的哈希表
;; root-id和id都是long型64位整数
(MessageId/makeRootId root-id id)
(MessageId/makeUnanchored))
;;实例化tuple
out-tuple (TupleImpl. worker-context
values
task-id
out-stream-id
tuple-id)]
;; 发送至队列,最终发送给流的下游的task/bolt
(transfer-fn out-task
out-tuple
overflow-buffer)
))
这个追踪信息是什么呢?

如果是spout -> bolt或者bolt -> bolt,这个信息就是tuple的MessageId,其内部维护一个哈希表:
// map anchor to id
private Map<Long, Long> _anchorsToIds;
键为root-id,表示spout,值表示tuple在tuple-tree或者DAG的根(spout)或者经过的边(bolt),但这里没有利用任何常规意义上的“树”的算法,而是采用异或的方式来存储这个值:
- spout -> bolt,值被初始化为一个long型64位整数.
- bolt -> bolt,值被初始化为一个long型64位整数,并和_anchorsToIds中的旧值进行按位异或,将结果更新到_anchorsToIds中.
如果是spout -> acker,或者bolt -> acker,那么用于追踪的是tuple的values:
- spout -> acker :
[root-id (bit-xor-vals out-ids) task-id] - bolt -> acker :
[root (bit-xor id ack-val) ..]
下面给出上面调用的bit-xor-vals和bit-xor方法的代码:
(defn bit-xor-vals
[vals]
(reduce bit-xor 0 vals))
(defn bit-xor
"Bitwise exclusive or"
{:inline (nary-inline 'xor)
:inline-arities >1?
:added "1.0"}
([x y] (. clojure.lang.Numbers xor x y))
([x y & more]
(reduce1 bit-xor (bit-xor x y) more)))
示例##
说起来有点抽象,看个例子。
假设我们有1个spout,n个bolt,1个acker:
1.spout###
spout发送tuple到下游的bolts:
;; id_1是发送到bolt_1的tuple-id,依此类推
spout :
->bolt_1 : id_1
->bolt_2 : id_2
..
->bolt_n : id_n
2.bolt###
bolt收到tuple,在execute方法中进行必要的处理,然后调用emit方法,最后调用ack方法:
;; bolt_1调用emit方法,追踪消息的这样一个值:让id_1和bid_1按位进行异或.
;; bid_1和id_1类似,是个long型的64位随机整数,在emit这一步生成
bolt_1 emit : id_1 ^ bid_1
;; bolt_1调用ack方法,并将值表达为如下方式的异或链的结果
bolt_1 ack : 0 ^ bid_1 ^ id_1 ^ bid_1 = 0 ^ id_1
以上,可以看出bolt进行了emit-ack组合后,其自身在异或链中的作用消失了,也就是说tuple在此bolt得到了处理。
(当然,此时的ack还没有得到acker的确认,假设acker确认了,那么上面所说的tuple在bolt得到了处理就成立了。)
来看看acker的确认。
3.acker###
acker收到来自spout的tuple:
;; spout发消息给acker,tuple的MessageId包含下面的异或链的结果
spout -> acker : 0 ^ id_1 ^ id_2 ^ .. ^ id_n
;; acker收到来spout的消息,对tuple的ackVal进行处理,如下所示:
acker : 0 ^ (0 ^ id_1 ^ id_2 ^ .. ^ id_n) = 0 ^ id_1 ^ id_2 ^ .. ^ id_n
acker收到来自bolt的tuple:
;; bolt_1发消息给acker:
bolt_1 -> acker : 0 ^ id_1
;; acker维护的对应此tuple的源spout的ackVal :
ackVal : 0 ^ id_1 ^ id_2 ^ .. ^ id_n
;; acker进行确认,也就是拿上面的两个值进行异或:
acker : (0 ^ id_1) ^ (0 ^ id_1 ^ id_2 ^ .. ^ id_n) = 0 ^ id_2 ^ .. ^ id_n
可以看出,bolt_1向acker请求ack,acker收到请求ack,异或之后,id_1的作用消失。也就是说,bolt_1已处理完毕这个tuple。
所以,在acker看来,如果某个bolt的处理完成,则此bolt在异或链中的作用就消失了。
如果所有的bolt 都得到处理,那么acker将会观察到ackVal值变成了0:
ackVal = 0
= (0 ^ id_1) ^ (0 ^ id_1 ^ .. ^ id_n) ^ .. ^ (0 ^ id_n)
= (0 ^ 0) ^ (id_1 ^ id_1) ^ (id_2 ^ id_2) ^ .. ^ (id_n ^ id_n)
如果出现了ackVal = 0,说明两个可能:
- spout发送的tuple都处理完成,tuple-tree或者DAG已完成。
- 概率性出错,也就是说在极小的概率下,即使不按上面的确认流程来走,异或链的结果也可能出现0.但这个概率极小,小到什么程度呢?
用官方的话说就是,如果每秒发送1万个ack消息,50,000,000年时才可能发生这种情况。
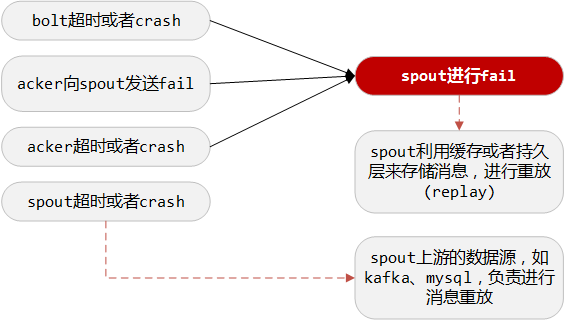
如果ackVal不为0,说明tuple-tree或DAG没有完成。如果长时间不为0,通过超时,可以触发一个超时回调,在这个回调中调用spout的fail方法,来进行重放。
如此,就保证了消息处理不会漏掉,但可能会重复。
结语##
以上,就是storm保证消息至少处理一次的语义的机制 。
storm如何保证at least once语义?的更多相关文章
- Storm如何保证可靠的消息处理
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 本文主要翻译自Storm官方文档Guaranteeing messag ...
- 【转】Twitter Storm如何保证消息不丢失
Twitter Storm如何保证消息不丢失 发表于 2011 年 09 月 30 日 由 xumingming 作者: xumingming | 可以转载, 但必须以超链接形式标明文章原始出处和作者 ...
- Strom 消息处理机制 中英对照翻译 (Storm如何保证消息被完全处理)
官方链接: http://storm.incubator.apache.org/documentation/Guaranteeing-message-processing.html What does ...
- storm是怎样保证at least once语义的
背景 本篇看看storm是通过什么机制来保证消息至少处理一次的语义的. storm中的一些原语 要说明上面的问题,得先了解storm中的一些原语,比方: tuple和message 在storm中,消 ...
- storm是如何保证at least once语义的?
storm中的一些原语: 要说明上面的问题,得先了解storm中的一些原语,比如: tuple和messagetuple:在storm中,消息是通过tuple来抽象表示的,每个tuple知道它从哪里来 ...
- Twitter Storm如何保证消息不丢失
storm保证从spout发出的每个tuple都会被完全处理.这篇文章介绍storm是怎么做到这个保证的,以及我们使用者怎么做才能充分利用storm的可靠性特点. 一个tuple被”完全处理”是什么意 ...
- Storm入门(五)Twitter Storm如何保证消息不丢失
转自:http://xumingming.sinaapp.com/127/twitter-storm如何保证消息不丢失/ storm保证从spout发出的每个tuple都会被完全处理.这篇文章介绍st ...
- Storm如何保证消息不丢失
storm保证从spout发出的每个tuple都会被完全处理.这篇文章介绍storm是怎么做到这个保证的,以及我们使用者怎么做才能充分利用storm的可靠性特点. 一个tuple被"完全处理 ...
- storm基础框架分析
背景 前期收到的问题: 1.在Topology中我们可以指定spout.bolt的并行度,在提交Topology时Storm如何将spout.bolt自动发布到每个服务器并且控制服务的CPU.磁盘等资 ...
随机推荐
- 第一章 Mysql 简介及安装和配置
Mysql是最流行的关系型数据库管理系统,在WEB应用方面MySQL是最好的RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一. ...
- hdu 4635 Strongly connected 强连通缩点
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4635 题意:给你一个n个点m条边的图,问在图不是强连通图的情况下,最多可以向图中添多少条边,若图为原来 ...
- Go
一.简介 https://zh.wikipedia.org/wiki/Go 二.安装 1)低版本 http://blog.sina.com.cn/s/blog_59cc90640102xm8r.htm ...
- nginx命令详解
nginx的configure命令支持以下参数: --prefix=path 定义一个目录,存放服务器上的文件 ,也就是nginx的安装目录.默认使用 /usr/local/nginx. --s ...
- 迅为iTOP-4412核心板调整电压
本文转自:http://www.topeetboard.com iTOP-4412核心板使用的电源管理芯片是三星专门针对4412研发的S5M8767,8767提供9路BUCK和28路LDO输出,每路电 ...
- [转]Oracle如何实现创建数据库、备份数据库及数据导出导入的一条龙操作
本文转自:http://www.cnblogs.com/wuhuacong/archive/2012/03/09/2387680.html Oracle中对数据对象和数据的管理,无疑都是使用PL/SQ ...
- NOIP2008提高组(前三题) -SilverN
此处为前三题,第四题将单独发布 火柴棒等式 题目描述 给你n根火柴棍,你可以拼出多少个形如“A+B=C”的等式?等式中的A.B.C是用火柴棍拼出的整数(若该数非零,则最高位不能是0).用火柴棍拼数字0 ...
- 有限状态机HDL模板
逻辑设计, 顾名思义, 只要理清了逻辑和时序, 剩下的设计只是做填空题而已. 下面给出了有限状态机的标准设计,分别为 VHDL 和 Verilog 代码 1 有限状态机 2 VHDL模板之一 li ...
- UVA 11766 Racing Car Computer --DP
题意:电脑记录了某一时刻每个赛车的前面和后面个有多少辆车(多个车并排时在别的车那只算一辆),问最少有多少个不合理的数据. 分析:看到n<=1000时,就尽量往DP上想吧. 每输入一组数据a,b, ...
- Android Sdk 和ADT Eclipse安装配置步骤
由于我们之前下载的jdk版本是1.6的,所以后面的andriod sdk等版本需要相对应.安装文件我都放在云盘里面,需要的可以下载 一:如果单独安装每一个软件,先期需要下载的软件包如下: 1.JDK ...