Machine Learning in Action -- AdaBoost
初始的想法就是,结合不同的分类算法来给出综合的结果,会比较准确一些
称为ensemble methods or meta-algorithms,集成方法或元算法
集成方法有很多种,可以是不同算法之间的,也可以是同一个算法但不同参数设置之间的,也可以是将数据集分成多分给不同的分类器之间的
总的来说,有3个维度可以进行集成,算法,算法参数和数据集
下面简单介绍两种比较流行的元算法思路,
1. Building classifiers from randomly resampled data: bagging
bagging又称为bootstrap aggregating
想法比较简单,对大小为n的训练集做n次放回随机抽样,形成新的大小仍然为n的训练集
因为是放回随机抽样,新的训练集中可能有重复,某些训练集中的样本中新的训练集中也会没有
用这个方法,产生s个新的训练集,对同一个分类算法可以产生s个不同参数的分类器
使用时,让s个分类器,多数投票表决来决定最终的分类结果
比较典型的bagging算法,如随机森林(random forest)
首先采用bootstrap取样,用产生新的训练集生成决策树,并且用在新训练集中没有抽样到样本作为测试集
如果有S个新的训练集,就会产生S个决策树,所以称为森林
所谓随机,首先新训练集是随机抽样产生的
再者,在训练决策树的时候,每个树节点会随机选择m个特征(m<<M总特征数)
参考,http://zh.wikipedia.org/wiki/%E9%9A%8F%E6%9C%BA%E6%A3%AE%E6%9E%97
2. Boosting
下面主要介绍Boosting中最流行的AdaBoost算法,这里主要介绍实现,理论参考前一篇
我们使用单层决策树,即decision stump 决策树桩作为弱分类器
所谓decision stump,就是只对一个特征做一次划分的单节点的决策树
这个弱分类器足够简单,但是如果直接使用,基本没用,
比如对于底下这个很简单的训练集,用一个decision stump都无法完全正确分类,试着在x轴或y轴上做一次划分
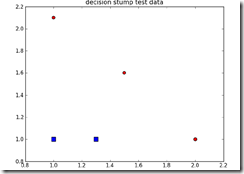
虽然无法完全正确分类,但是我们需要找到误差最小的那个decision stump
方法很简单,在x和y的取值范围内,以一定的步长,遍历比较误差
先实现stump分类,
dataMatrix,一行表示一个训练样本,每列表示一个特征
dimen,表示哪个特征
threshVal,阀值
threshIneq,对于decision stump,只存在less than或greater than
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
retArray = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt': #lt,less than
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 #boolean indexing
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
所以给定上面的参数,就是可以判断每个样本的分类是1或-1
下面给出求解最优stump分类器的算法,
参数中有个D向量,表示样本weight
因为这里是要找到加权样本误差最小的stump分类器
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1)))
minError = inf #inf,python中表示无穷大
for i in range(n): #遍历每个特征
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max(); #计算该特征上的取值范围
stepSize = (rangeMax-rangeMin)/numSteps #计算遍历步长
for j in range(-1,int(numSteps)+1): #以步长遍历该特征
for inequal in ['lt', 'gt']: #尝试划分的方向,less than或greater than
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal) #进行stump分类
errArr = mat(ones((m,1))) #初始化误差为1
errArr[predictedVals == labelMat] = 0 #计算误差,将分对的误差设为0
weightedError = D.T*errArr #计算加权误差
if weightedError < minError: #如果小于minError,说明我们找到更优的stump分类器
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
好,现在可以给出AdaBoost算法的源码,
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0] #样本数
D = mat(ones((m,1))/m) #初始化样本weight,所有样本权值相等为1/m
aggClassEst = mat(zeros((m,1))) #累积分类结果
for i in range(numIt): #生成多少个弱分类器
bestStump,error,classEst = buildStump(dataArr,classLabels,D) #计算最优的stump分类器
print "D:",D.T
alpha = float(0.5*log((1.0-error)/max(error,1e-16))) #1.计算该分类器的权值
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
print "classEst: ",classEst.T
expon = multiply(-1*alpha*mat(classLabels).T,classEst)
D = multiply(D,exp(expon)) #2.更新样本权值
D = D/D.sum()
aggClassEst += alpha*classEst #3.更新累积分类结果
print "aggClassEst: ",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != #计算累积分类误差
mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print "total error: ",errorRate,"\n"
if errorRate == 0.0: break #4.误差为0,算法结束
return weakClassArr
其中,
1. 计算分类器权值的公式为,
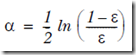
max(error,1e-16),这个是为了防止error为0
2. 更新样本权值的公式为,

即判断正确时,减小权值,而错误时,增大权值
expon = multiply(-1*alpha*mat(classLabels).T,classEst)
-alpha×classLabel×classEst,即如果分类正确,classLable=classEst,仍然得到-alpha,否则得到alpha
3. aggClassEst
因为我们最终在分类时,是用多个弱分类器的综合结果
所以这里每生成一个弱分类器,我们就把它的分类结果加到aggClassEst上,aggClassEst += alpha*classEst
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
用于aggClassEst是float类型,所以先使用sign转换成1,-1,0
然后!= mat(classLabels).T,会产生一个boolean的向量
小技巧,这里为何要乘上一个全1的向量,因为需要把boolean类型转换为int
可以在python试下,
>>> (1 == 1) *1
1
4.最终当所有弱分类器综合误差为0时,就不需要继续迭代了
下面看看,如何用AdaBoost算法进行分类
def adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha']*classEst
print aggClassEst
return sign(aggClassEst)
Machine Learning in Action -- AdaBoost的更多相关文章
- 【机器学习实战】Machine Learning in Action 代码 视频 项目案例
MachineLearning 欢迎任何人参与和完善:一个人可以走的很快,但是一群人却可以走的更远 Machine Learning in Action (机器学习实战) | ApacheCN(apa ...
- 学习笔记之机器学习实战 (Machine Learning in Action)
机器学习实战 (豆瓣) https://book.douban.com/subject/24703171/ 机器学习是人工智能研究领域中一个极其重要的研究方向,在现今的大数据时代背景下,捕获数据并从中 ...
- K近邻 Python实现 机器学习实战(Machine Learning in Action)
算法原理 K近邻是机器学习中常见的分类方法之间,也是相对最简单的一种分类方法,属于监督学习范畴.其实K近邻并没有显式的学习过程,它的学习过程就是测试过程.K近邻思想很简单:先给你一个训练数据集D,包括 ...
- 机器学习实战(Machine Learning in Action)学习笔记————10.奇异值分解(SVD)原理、基于协同过滤的推荐引擎、数据降维
关键字:SVD.奇异值分解.降维.基于协同过滤的推荐引擎作者:米仓山下时间:2018-11-3机器学习实战(Machine Learning in Action,@author: Peter Harr ...
- 机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据
机器学习实战(Machine Learning in Action)学习笔记————09.利用PCA简化数据 关键字:PCA.主成分分析.降维作者:米仓山下时间:2018-11-15机器学习实战(Ma ...
- 机器学习实战(Machine Learning in Action)学习笔记————08.使用FPgrowth算法来高效发现频繁项集
机器学习实战(Machine Learning in Action)学习笔记————08.使用FPgrowth算法来高效发现频繁项集 关键字:FPgrowth.频繁项集.条件FP树.非监督学习作者:米 ...
- 机器学习实战(Machine Learning in Action)学习笔记————07.使用Apriori算法进行关联分析
机器学习实战(Machine Learning in Action)学习笔记————07.使用Apriori算法进行关联分析 关键字:Apriori.关联规则挖掘.频繁项集作者:米仓山下时间:2018 ...
- 机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记
机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记 关键字:k-均值.kMeans.聚类.非监督学习作者:米仓山下时间: ...
- 机器学习实战(Machine Learning in Action)学习笔记————05.Logistic回归
机器学习实战(Machine Learning in Action)学习笔记————05.Logistic回归 关键字:Logistic回归.python.源码解析.测试作者:米仓山下时间:2018- ...
随机推荐
- hdu 1754 单点更新
题意:很多学校流行一种比较的习惯.老师们很喜欢询问,从某某到某某当中,分数最高的是多少.这让很多学生很反感.不管你喜不喜欢,现在需要你做的是,就是按照老师的要求,写一个程序,模拟老师的询问.当然,老师 ...
- kinect学习笔记(一)—— Openni平台的搭建~、
一.简述 Openni平台是开源的平台,也就是说所有的源代码都可以查询,可以有助于我们对于整个程序框架的学习和理解,相对于微软的SDK,我更倾向于这个平台,但是由于个各种原因,现在这个 ...
- WinForm下窗体标题栏上有“帮助”按钮
将FormBorderStyle设置为Sizable. 最大化和最小化设置为false helpbutton 设置为true
- Android 编程下短信监听在小米手机中失效的解决办法
相信很多人写的短信监听应用在小米手机上是拦截不到短信的,这是因为小米对短信的处置权优先分给了系统.我们可以在短信的[设置]→[高级设置]→[系统短信优先]中发现短信的优先处理权默认是分给系统的,只要关 ...
- HTTP基础01--web与互联网基础
WWW构建技术: 把SGML(标准通用标记语言)作为页面文本标记的HTML(超文本标记语言): 作为文档传递协议的HTTP(超文本传输协议): //严谨应该称为“超文本转移协议”: 指定文档所在地址 ...
- DataTable转换成List<T>
很多时候需要将DataTable转换成一组model,直接对model执行操作会更加方便直观. 代码如下: public static class DataTableToModel { public ...
- ZOJ3228 Searching the String(AC自动机)
题目大概是给一个主串,询问若干个模式串出现次数,其中有些模式串要求不能重叠. 对于可以重叠的就是一个直白的多模式匹配问题:而不可重叠,在匹配过程中贪心地记录当前匹配的主串位置,然后每当出现一个新匹配根 ...
- POJ2762 Going from u to v or from v to u?(判定单连通图:强连通分量+缩点+拓扑排序)
这道题要判断一张有向图是否是单连通图,即图中是否任意两点u和v都存在u到v或v到u的路径. 方法是,找出图中所有强连通分量,强连通分量上的点肯定也是满足单连通性的,然后对强连通分量进行缩点,缩点后就变 ...
- Linux Mint 没有 language support 语言支持解决方案
打开新立得软件管理器在右边找到有关语言的安装后,language support就会出现
- TYVJ P1013 找啊找啊找GF Label:动态规划
做题记录:2016-08-15 22:19:04 背景 MM七夕模拟赛 描述 "找啊找啊找GF,找到一个好GF,吃顿饭啊拉拉手,你是我的好GF.再见.""诶,别再见啊.. ...