洗礼灵魂,修炼python(60)--爬虫篇—httplib2模块
这里先要补充一下,Python3自带两个用于和HTTP web 服务交互的标准库(内置模块):
- http.client 是HTTP协议的底层库
- urllib.request 建立在http.client之上一个抽象层,它为访问HTTP和FTP服务器提供一个标准的API,可以自动跟随HTTP重定向并处理一些常见形式的HTTP 认证
httplib2
1.简介
httplib2是一个第三方的开源库。它比python3中的http.client更完整的实现了HTTP协议,同时比urllib.request提供了更好的抽象。
前面说的httplib,功能已经够全够实用了对吧,为什么还要用httplib2或者说为什么还要有httplib2?这个问题,我想你会立即联想到urllib和urllib2模块的关系。
答案也和urllib和urllib2一样,功能有补充,有提升。
httplib2是第三方模块,所以需要先安装再使用
有哪些很显著的特点呢?
1).支持HTTP 1.1的 Keep-Alive特性,能够在同一个socket连接里使用并发的httprequest
2).支持的认证方式
- Basic(基础)
- Digest(摘要)
- WSSE(WS-Security,Web服务安全)
- HMAC Digest(Hash-based message authentication code,利用哈希算法,以一个密钥和一个消息为输入,生成一个消息摘要作为输出)
- Google Account Authentication(谷歌式账户认证)
当然一般Basic和Digest就够用了。
如果觉得保密性不够,那最好用HTTPS,这个防火墙也无法根据内容过滤
3).支持Cache(缓存)
是的,缓存是很多机制都必有的功能,如果http的库没有包含http本身支持的缓存就太可惜了。
如下就能创建一个带有缓存的HTTP对象test,缓存则存储在当前环境的“.cache"目录下:
注意httplib2.Http,Http,首字母大写
import httplib2
test = httplib2.Http(".cache")
4).支持所有HTTP请求方法:即在GET和POST基础上,还支持DELETE和CONNECT
5).自动通过”GET“方法,重定向状态码为3XX的返回值
6).支持deflate和gzip的压缩格式
很多网页其实都用的gzip的压缩格式压缩网页源代码,减少浏览器加载时间,这样可以更加快速的打开网页,相对来说,deflate倒是很少见
7).支持最后修改时间检查
8).支持ETag(实体标签)
9).支持永久重定向。不仅会告诉你永久重定向,还会在本地记录,并且在发送请求前自动重写为重定向后的URL
2.方法/属性

其实你有没有发现,httplib2和httplib模块等的都会带有其他标准库,比如上面截图里的urllib,time,copy等,还带有模块httplib,所以它的功能才那么多,可以简单的测试一下:

发现urllib的路径正好就是默认的urllib标准库,还有sys,time等的显示的都属于built-in,这个单词不用多说,我想你应该知道这就是内置模块的意思。
所以像这种第三方库,因为代码已经设置好了可以直接用标准库的方法,所以功能才那么强大,完全可以替代标准库
3.常用方法/属性解析
httplib2模块和urllib3的地位一样尴尬,虽然它也是第三方库,但是用的其实也不多,网上的资料也少,而其方法和属性,上面的截取你应该看到了,基本链接的python自己的标准库。
httplib2.Http()会创建一个类对象,同前面的一样,自己去联想了。
httplib2.Http()
1.httplib2.Http()的常用实例:
1)首先httplib2.Http()最常用例:
# -*- coding:gb2312 -*-
import httplib2
html=httplib2.Http()
print html.request('http://www.baidu.com')
结果是报文头部信息+百度首页源代码组合成的元组,所以你也可以把上面的第四行改为【headers,content = html.request('http://www.baidu.com/') 】分别把头部和百度首页源代码取出来。
2):带cache的访问:
# -*- coding:gb2312 -*-
import httplib2
html=httplib2.Http('.cache') #默认在当前主py目录下创建名为.cache的文件夹
print html.request('http://www.baidu.com')
结果,我电脑里当前目录下多了个.cache目录
打开目录: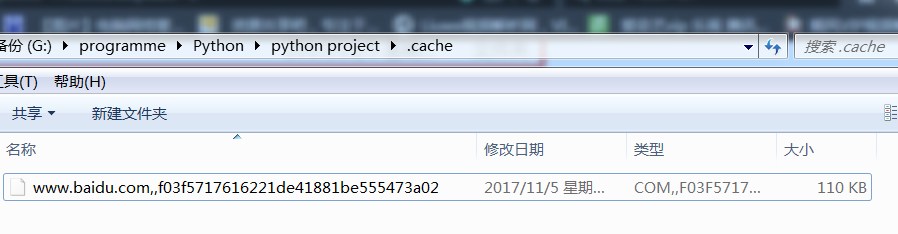
发现这就是刚才访问百度网页得到的缓存,用记事本打开:
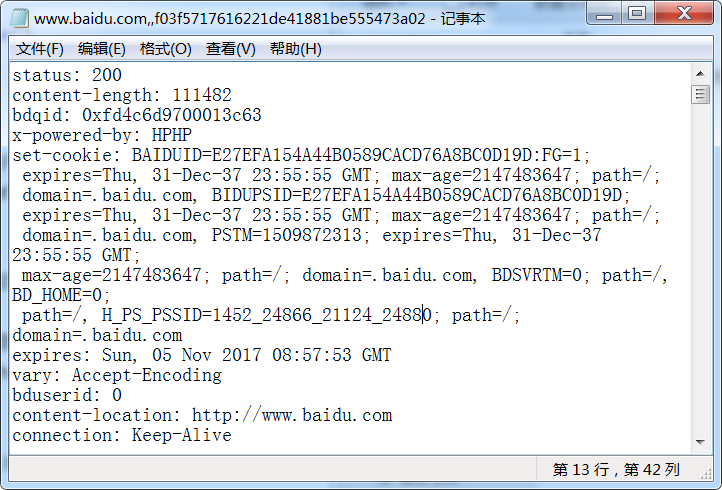
发现里面的内容就同前面的一样,是http头部信息和百度首页的源代码。
2.httplib2.Http()的常用方法
1).Http.add_credentials:
- 增加授权用户名和密码,httplib2自动会通过解析repond:Http.add_credentials(name, password[, domain=None])
- 增加ssl的证书信息
2).Http.request(url[, method="GET", body=None, headers=None, redirections=DEFAULT_MAX_REDIRECTS, connection_type=None])
- method:默认是"GET"
- redirections:指定其他header和最大自动重定向次数(默认是5),并不能无限重定向
- connection_type:连接类型
- (其他参数相信你通过前面的学习都很清楚了,不用再说了)
例1:测试httplib2是否能支持https
# -*- coding:gb2312 -*-
import httplib2
html=httplib2.Http('.cache')
html.add_credentials('name','password')
reponse,cont=html.request('https://www.baidu.com',
'GET',
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0',
'content-type':'text/plain',
'Accept': 'text/plain'})
print reponse
print '---------------------------------------------------'
print cont
结果是,程序还是正常的的运行并爬取到百度首页的代码以及报文头部信息。
例2:域名重定向
注意:这里说个题外话,也是必须要说的。下面这个网站是我好不容易找到的,是一个私人网站,没有百度企业网站服务器那么经搞,大家尽量不要去测试,看我给的测试和结果就好了,毕竟是一个私人网站,如果你把别人网站服务器搞崩了就不太好了(我测试的前后这网站可是可以正常登录的,并没有给人搞崩),你知道httplib2模块可以实现域名重定向就可以了。还有我们现在写的爬虫都算一般的,别以为你用代理ip或者隐藏头部信息就真的匿名了,真要找你是找得到的。
# -*- coding:gb2312 -*-
import httplib2
html=httplib2.Http('.cache')
html.add_credentials('name','password')
reponse,cont=html.request('http://www.freedom1024.com',
'GET',
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0',
'content-type':'text/plain',
'Accept': 'text/plain'})
print reponse
print '---------------------------------------------------'
print cont
结果:
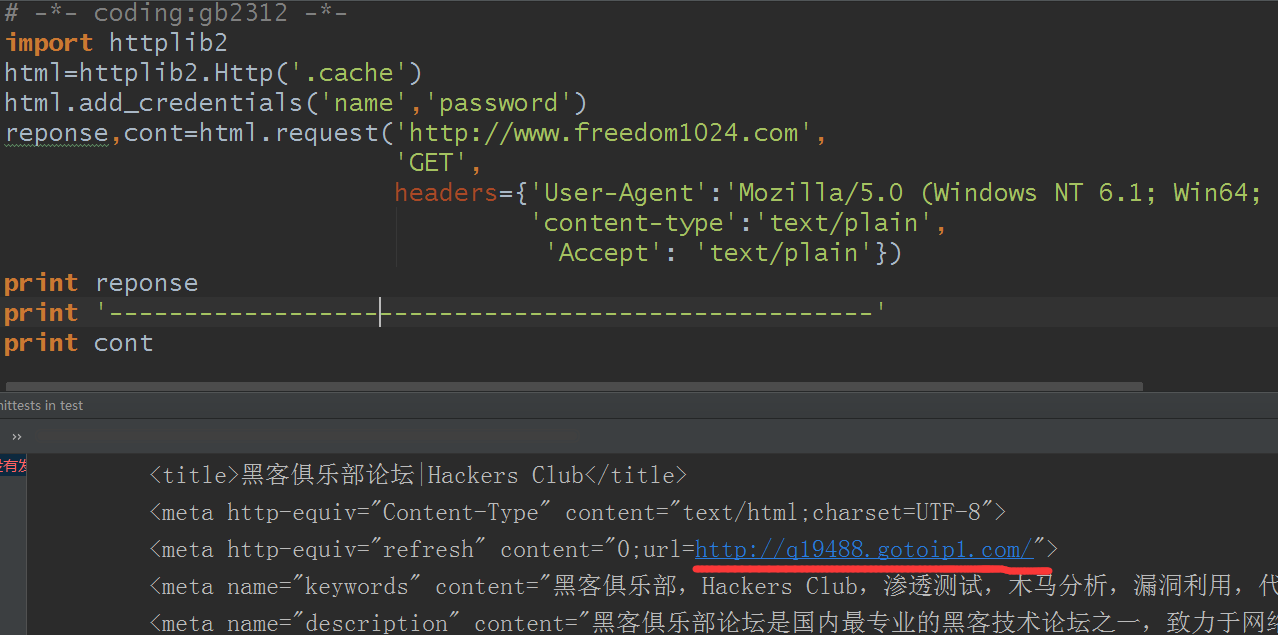
用浏览器打开测试看看:
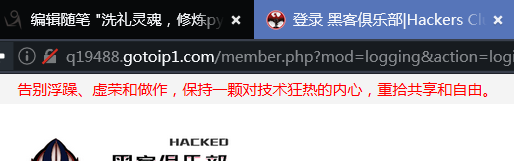
确实是这个链接,完美(/斜眼笑)
更多的相关功能就你自己去发现吧,我看到还有人用httplib2登录网页版的QQ等的。自己下去研究了。
免责声明
本博文只是为了分享技术和共同学习为目的,并不出于商业目的和用途,也不希望用于商业用途,特此声明。如果内容中测试的贵站的站长有异议,请联系我立即删除
洗礼灵魂,修炼python(60)--爬虫篇—httplib2模块的更多相关文章
- 洗礼灵魂,修炼python(63)--爬虫篇—re模块/正则表达式(1)
爬虫篇前面的某一章了,我们要爬取网站页面源代码的数据,要从中获取到我们想要的数据,是不是感觉很费力,确实费力对吧?那么有没有什么有利的工具来解决这个问题呢?那就是这一篇博文的主题—— 正则表达式简介 ...
- 洗礼灵魂,修炼python(54)--爬虫篇—urllib2模块
urllib2 1.简介 urllib2模块定义的函数和类用来获取URL(主要是HTTP的),他提供一些复杂的接口用于处理: 基本认证,重定向,Cookies等.urllib2和urllib差不多,不 ...
- Python 学习 第九篇:模块
模块是把程序代码和数据封装的Python文件,也就是说,每一个以扩展名py结尾的Python源代码文件都是一个模块.每一个模块文件就是一个独立的命名空间,用于封装顶层变量名:在一个模块文件的顶层定义的 ...
- 洗礼灵魂,修炼python(53)--爬虫篇—urllib模块
urllib 1.简介: urllib 模块是python的最基础的爬虫模块,其核心功能就是模仿web浏览器等客户端,去请求相应的资源,并返回一个类文件对象.urllib 支持各种 web 协议,例如 ...
- 洗礼灵魂,修炼python(64)--爬虫篇—re模块/正则表达式(2)
前面学习了元家军以及其他的字符匹配方法,那得会用啊对吧?本篇博文就简单的解析怎么运用 正则表达式使用 前面说了正则表达式的知识点,本篇博文就是针对常用的正则表达式进行举例解析.相信你知道要用正则表达式 ...
- 洗礼灵魂,修炼python(59)--爬虫篇—httplib模块
httplib 1.简介 同样的,httplib默认存在于python2,python3不存在: httplib是python中http协议的客户端实现,可以用来与 HTTP 服务器进行交互,支持HT ...
- Python学习——爬虫篇
requests 使用requests进行爬取 下面是我编写的第一个爬虫的脚本 import requests # 导入reques ...
- Python学习—爬虫篇之破解ntml登陆问题
之前帮公司爬取过内部的一个问题单网站,要求将每个问题单的下的附件下载下来.一开始的时候我就遇到一个破解登陆验证的大坑...... (╬ ̄皿 ̄)=○ 由于在公司使用的都是内网,代码和网站的描述 ...
- 04.Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
随机推荐
- servlet(二)
http协议 (1)什么是http协议? 是一种网络应用层协议,规定了浏览器如何与web服务器之间进行通信以及相应的 数据包的结构. 浏览器与web服务器之间如何通信? step1.建立连接 step ...
- python 怎样获取toast?
toast是什么? 想要获取toast的小伙伴们,肯定知道这个是一个什么玩意,例行还是加一个图,加以解释,下图的就是传说中的toast,它有一个特点,出现时间特别短,很难通过定位元素去获取这个toas ...
- HDU 6044--Limited Permutation(搜索+组合数+逆元)
题目链接 Problem Description As to a permutation p1,p2,⋯,pn from 1 to n, it is uncomplicated for each 1≤ ...
- 从零开始学 Web 之 DOM(四)节点
大家好,这里是「 Daotin的梦呓 」从零开始学 Web 系列教程.此文首发于「 Daotin的梦呓 」公众号,欢迎大家订阅关注.在这里我会从 Web 前端零基础开始,一步步学习 Web 相关的知识 ...
- 音频标签化1:audioset与训练模型 | 音频特征样本
随着机器学习的发展,很多"历史遗留"问题有了新的解决方案.这些遗留问题中,有一个是音频标签化,即如何智能地给一段音频打上标签的问题,标签包括"吉他"." ...
- Mongodb 命令清单
一.数据库常用命令 # 切换/创建数据库 PRIMARY> use yourDB; #当创建一个集合(table)的时候会自动创建当前数据库# 查询所有数据库 PRIMARY> show ...
- go runtime.Gosched()的作用分析
untime.Gosched()用于让出CPU时间片.这就像跑接力赛,A跑了一会碰到代码runtime.Gosched()就把接力棒交给B了,A歇着了,B继续跑. 看代码: package main ...
- Maven教程4(私服-nexus)
仓库管理器也叫私服或代理仓库 仓库管理器有两个服务目的:首先它的角色是一个高度可配置的介于你的组织与公开Maven仓库之间的代理,其次它为你的组织提供了一个可部署你组织内部生成的构件的地方. 1Nex ...
- SPI 驱动框架
SPI 驱动框架 1. 枚举过程 drivers/spi/spi.c: spi_register_board_info /* 对于每一个spi_master,调用spi_match_master_to ...
- css布局------左边宽度不定,右边宽度自动填满剩余空间
HTML <div class="container"> <div class="left"></div> <div ...