Hive-1.2.1_06_累计报表查询
1. 数据准备
# 本地数据准备
[yun@mini01 hive]$ pwd
/app/software/hive
[yun@mini01 hive]$ ll /app/software/hive/t_access_times.dat
-rw-rw-r-- yun yun Jul : /app/software/hive/t_access_times.dat
[yun@mini01 hive]$ cat /app/software/hive/t_access_times.dat
A,--,
A,--,
B,--,
A,--,
B,--,
A,--,
A,--,
A,--,
B,--,
B,--,
A,--,
B,--,
A,--,
B,--,
A,--,
B,--,
A,--,
B,--,
A,--,
# hive 建表
hive (test_db)> create table t_access_times(username string,month string,salary int)
> row format delimited fields terminated by ',';
OK
Time taken: 0.16 seconds # 数据上传 从desc formatted t_access_times; 可获取Location信息
: jdbc:hive2://mini01:10000> load data local inpath '/app/software/hive/t_access_times.dat' [overwrite] into table t_access_times; # 上传
INFO : Loading data to table test_db.t_access_times from file:/app/software/hive/t_access_times.dat
INFO : Table test_db.t_access_times stats: [numFiles=, totalSize=]
No rows affected (0.764 seconds)
: jdbc:hive2://mini01:10000> select * from t_access_times; # 查询数据
+--------------------------+-----------------------+------------------------+--+
| t_access_times.username | t_access_times.month | t_access_times.salary |
+--------------------------+-----------------------+------------------------+--+
| A | -- | |
| A | -- | |
| B | -- | |
| A | -- | |
| B | -- | |
| A | -- | |
| A | -- | |
| A | -- | |
| B | -- | |
| B | -- | |
| A | -- | |
| B | -- | |
| A | -- | |
| B | -- | |
| A | -- | |
| B | -- | |
| A | -- | |
| B | -- | |
| A | -- | |
+--------------------------+-----------------------+------------------------+--+
rows selected (0.102 seconds)
# 根据月份查询 去掉月份字段中的天信息
: jdbc:hive2://mini01:10000> select a.username, substr(a.month,1,7) month, a.salary from t_access_times a;
+-------------+----------+-----------+--+
| a.username | month | a.salary |
+-------------+----------+-----------+--+
| A | - | |
| A | - | |
| B | - | |
| A | - | |
| B | - | |
| A | - | |
| A | - | |
| A | - | |
| B | - | |
| B | - | |
| A | - | |
| B | - | |
| A | - | |
| B | - | |
| A | - | |
| B | - | |
| A | - | |
| B | - | |
| A | - | |
+-------------+----------+-----------+--+
rows selected (0.078 seconds)
2. 用户一个月总金额
# 或者使用 select x.username, x.month, sum(x.salary) from (select a.username, substr(a.month,,) month, a.salary from t_access_times a) x group by x.username, x.month;
: jdbc:hive2://mini01:10000> select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7);
INFO : Number of reduce tasks not specified. Estimated from input data size:
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:
INFO : Submitting tokens for job: job_1531893043061_0002
INFO : The url to track the job: http://mini02:8088/proxy/application_1531893043061_0002/
INFO : Starting Job = job_1531893043061_0002, Tracking URL = http://mini02:8088/proxy/application_1531893043061_0002/
INFO : Kill Command = /app/hadoop/bin/hadoop job -kill job_1531893043061_0002
INFO : Hadoop job information for Stage-: number of mappers: ; number of reducers:
INFO : -- ::, Stage- map = %, reduce = %
INFO : -- ::, Stage- map = %, reduce = %, Cumulative CPU 3.08 sec
INFO : -- ::, Stage- map = %, reduce = %, Cumulative CPU 5.53 sec
INFO : MapReduce Total cumulative CPU time: seconds msec
INFO : Ended Job = job_1531893043061_0002
+-------------+----------+------+--+
| a.username | month | _c2 |
+-------------+----------+------+--+
| A | - | |
| A | - | |
| A | - | |
| B | - | |
| B | - | |
| B | - | |
+-------------+----------+------+--+
rows selected (18.755 seconds)
3. 将月总金额表 自己连接 自己连接
: jdbc:hive2://mini01:10000> select * from
: jdbc:hive2://mini01:10000> (select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) A
: jdbc:hive2://mini01:10000> inner join
: jdbc:hive2://mini01:10000> (select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) B
: jdbc:hive2://mini01:10000> on A.username = B.username
: jdbc:hive2://mini01:10000> ORDER BY A.username, A.`month`, B.`month`;
INFO : Number of reduce tasks not specified. Estimated from input data size:
…………………………
INFO : Ended Job = job_1531893043061_0029
+-------------+----------+-----------+-------------+----------+-----------+--+
| a.username | a.month | a.salary | b.username | b.month | b.salary |
+-------------+----------+-----------+-------------+----------+-----------+--+
| A | - | | A | - | |
| A | - | | A | - | |
| A | - | | A | - | |
| A | - | | A | - | |
| A | - | | A | - | |
| A | - | | A | - | |
| A | - | | A | - | |
| A | - | | A | - | |
| A | - | | A | - | |
| B | - | | B | - | |
| B | - | | B | - | |
| B | - | | B | - | |
| B | - | | B | - | |
| B | - | | B | - | |
| B | - | | B | - | |
| B | - | | B | - | |
| B | - | | B | - | |
| B | - | | B | - | |
+-------------+----------+-----------+-------------+----------+-----------+--+
rows selected (85.593 seconds)
######################################################
# 查询后排序
: jdbc:hive2://mini01:10000> select * from
: jdbc:hive2://mini01:10000> (select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) A
: jdbc:hive2://mini01:10000> inner join
: jdbc:hive2://mini01:10000> (select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) B
: jdbc:hive2://mini01:10000> on A.username = B.username
: jdbc:hive2://mini01:10000> where A.month >= B.month
: jdbc:hive2://mini01:10000> ORDER BY A.username, A.month, B.month;
INFO : Number of reduce tasks not specified. Estimated from input data size:
…………………………
INFO : Ended Job = job_1531893043061_0016
+-------------+----------+--------+-------------+----------+--------+--+
| a.username | a.month | a._c2 | b.username | b.month | b._c2 |
+-------------+----------+--------+-------------+----------+--------+--+
| A | - | | A | - | |
| A | - | | A | - | |
| A | - | | A | - | |
| A | - | | A | - | |
| A | - | | A | - | |
| A | - | | A | - | |
| B | - | | B | - | |
| B | - | | B | - | |
| B | - | | B | - | |
| B | - | | B | - | |
| B | - | | B | - | |
| B | - | | B | - | |
+-------------+----------+--------+-------------+----------+--------+--+
rows selected (83.385 seconds)
4. 累计报表
4.1. 类似数据在MySQL数据库查询
# 使用这个SQL语句就可了,但是在HIVE中运行不了
select A.username, A.month, A.salary , sum(B.salary) countSala from
(select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) A
inner join
(select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) B
on A.username = B.username
where A.month >= B.month
group by A.username, A.month
ORDER BY A.username, A.month, B.month;
4.2. Hive中运行
# 上面的SQL不能运行 所以查询列表改为了max(A.salary) salary ; order by 中去掉了 B.month 。
0: jdbc:hive2://mini01:10000> select A.username, A.month, max(A.salary) salary, sum(B.salary) countSala from
0: jdbc:hive2://mini01:10000> (select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) A
0: jdbc:hive2://mini01:10000> inner join
0: jdbc:hive2://mini01:10000> (select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) B
0: jdbc:hive2://mini01:10000> on A.username = B.username
0: jdbc:hive2://mini01:10000> where A.month >= B.month
0: jdbc:hive2://mini01:10000> group by A.username, A.month
0: jdbc:hive2://mini01:10000> ORDER BY A.username, A.month;
INFO : Number of reduce tasks not specified. Estimated from input data size: 1
………………
INFO : Ended Job = job_1531893043061_0052
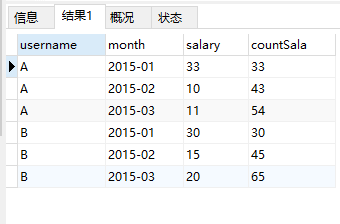
+-------------+----------+---------+------------+--+
| a.username | a.month | salary | countsala |
+-------------+----------+---------+------------+--+
| A | 2015-01 | 33 | 33 |
| A | 2015-02 | 10 | 43 |
| A | 2015-03 | 11 | 54 |
| B | 2015-01 | 30 | 30 |
| B | 2015-02 | 15 | 45 |
| B | 2015-03 | 20 | 65 |
+-------------+----------+---------+------------+--+
6 rows selected (106.718 seconds)
Hive-1.2.1_06_累计报表查询的更多相关文章
- 12_Hive实战案例_累计报表_级联求和
注:Hive面试题:累积报表 数据文件: 有如下访客访问次数统计表 t_access_times 需要输出报表:t_access_times_accumulate 实现步骤: 创建表,并将数据加载到表 ...
- [原创]java WEB学习笔记90:Hibernate学习之路-- -HQL检索方式,分页查询,命名查询语句,投影查询,报表查询
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- 用excel打造报表查询系统
网络数据库以及ERP在中小型企业中日益风行,虽然ERP功能强大,但有的ERP报表系统中规范的报表较少,主要提供二次开发接口或通过如CRYSTALREPORT等其他报表工具进行管理,其实我们可以使用Ex ...
- SNF开发平台WinForm-EasyQuery统计分析-效果-非常牛逼的报表查询工具
无论是单轴曲线 .双轴曲线 .柱形图 .饼图 .雷达图 .仪表图.图表引擎全能为您轻松实现.您只需要 3 步操作(数据源准备,设计图表,挂接到您想要展示的位置)便可完成 BI 的设计. 无论是普通报表 ...
- Hive学习之Union和子查询
Union的语法格式如下: select_statement UNION ALL select_statement UNION ALL select_statement ... Union用于将多个S ...
- 【解决】hive与hbase表结合级联查询的问题
[Author]: kwu [解决]hive与hbase表结合级联查询的问题.hive两个表以上,关联查询时出现长时无法返回的情况. 同一时候也不出现,mr的进度百分比. 查询日志如图所看到的: 解决 ...
- [Hive - Tutorial] Querying and Inserting Data 查询和插入数据
Querying and Inserting Data Simple Query Partition Based Query Joins Aggregations Multi Table/File I ...
- Hive记录-加载文件进行查询操作
Hive可以运行保存在文件里面的一条或多条的语句,只要用-f参数,一般情况下, 保存这些Hive查询语句的文件通常用.q或者.hql后缀名,但是这不是必须的, 你也可以保存你想要的后缀名.假设test ...
- SAP+DB2 糟糕的报表查询『ZCOR0015』 优化全程记录
ZCOR0015的优化全过程记录文档 2015年3月,今天无意翻到这篇写于2010年7月的文档,回想那时的工作,毕业3年初出茅庐的我面对接触不多的SAP+DB2竟敢操刀动斧,自信满满. 虽然这过程一路 ...
随机推荐
- Jenkins之使用Pyinstaller构建Python应用程序
目录 1. 极简概述 2. Jenkins配置 2.1 安装JDK 2.2 安装Jenkins 3. 安装Docker 4. 使用PyInstaller构建Python应用程序 4.1 Fork 一个 ...
- Apktool的安装与使用
官网的安装方式如下图: 前提条件: Java 1.8版本已安装 通过在终端内输入"java -version"可以查看Java版本 因为我用的是MacBook,所以只介绍如何在Ma ...
- AcceptEx与完成端口(IOCP)结合实例
前言 在windows平台下实现高性能网络服务器,iocp(完成端口)是唯一选择.编写网络服务器面临的问题有:1 快速接收客户端的连接.2 快速收发数据.3 快速处理数据.本文主要解决第一个问题. A ...
- Golang 协程调度
一.线程模型 N:1模型,N个用户空间线程在1个内核空间线程上运行.优势是上下文切换非常快但是无法利用多核系统的优点. 1:1模型,1个内核空间线程运行一个用户空间线程.这种充分利用了多核系统的优势但 ...
- Golang GC原理
一.内存泄漏 内存泄露,是从操作系统的角度上来阐述的,形象的比喻就是“操作系统可提供给所有进程的存储空间(虚拟内存空间)正在被某个进程榨干”,导致的原因就是程序在运行的时候,会不断地动态开辟的存储空间 ...
- JAVA开发者的Golang快速指南
Golang作为Docker.Kubernetes和OpenShift等一些酷辣新技术的首选编程语言,越来越受欢迎.尤其它们都是开源的,很多情况下,开源是非常有价值的.深入学习阅Golang等源代码库 ...
- .Net Core中使用Quartz.Net
一.介绍 Quartz.Net是根据Java的Quartz用C#改写而来,最新的版本是3.0.6,源码在https://github.com/quartznet/quartznet.主要作用是做一些周 ...
- JavaWeb之Maven一
Maven和C#的nuget类似,可以通过设置就能引入框架等第三方,方便又省事.Java中使用Maven来管理第三方.今天尝试着配置了一下. 一.JDK的安装 关于JDK的安装可以查看百度经验,设置P ...
- SQL 行列转换数据转换为字符串
行列转换,将列数据转换为字符串输出 ) SET @center_JZHW = ( SELECT DISTINCT STUFF( ( SELECT ',' + ce_code FROM ap_cente ...
- 自定义滚动条mCustomScrollbar
mCustomScrollbar 是个基于 jQuery UI 的自定义滚动条插件,它可以让你灵活的通过 CSS 定义网页的滚动条,并且垂直和水平两个方向的滚动条都可以定义,它通过 Brandon A ...