『Python CoolBook:heapq』数据结构和算法_heapq堆队列算法&容器排序
一、heapq堆队列算法模块
本模块实现了堆队列算法,也叫作优先级队列算法。堆队列是一棵二叉树,并且拥有这样特点,它的父节点的值小于等于任何它的子节点的值。
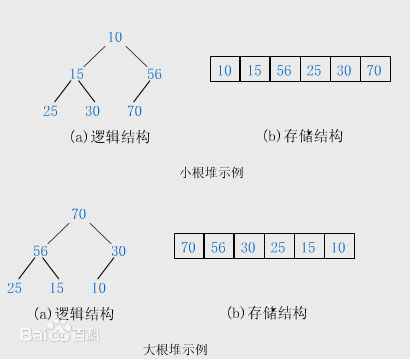
本模块实际上实现了一系列操作容器的方法,使之表现的如堆一般。
1、基本使用
heapq.heappush(heap, item)
把一项值压入list(用于表示堆heap),同时维持堆的排序要求,其特性是直接比较入列元素大小(包括入列元素为容器的情况),将大的放在后面。
import heapq queue = []
heapq.heappush(queue, 5)
heapq.heappush(queue, 2)
heapq.heappush(queue, 1)
heapq.heappush(queue, 2)
queue
[1, 2, 2, 5]
heapq.heappop(heap)
弹出并返回堆里最小值的项,调整堆排序。如果堆为空,抛出异常IndexError。
heapq.heappop(queue)
1
heapq.heapify(x)
就地转换一个列表为堆排序,时间为线性。
nums = [1, 8, 2, 23, 7, -4, 18, 23, 42, 37, 2]
heapq.heapify(nums)
nums
[-4, 2, 1, 23, 7, 2, 18, 23, 42, 37, 8]
初始化后仅仅保证前三个元素最小的顺序(最前端的树分支),在后面headpop会依次维护队列的输出最小:
for i in range(11):
print(heapq.heappop(nums))
-4 1 2 2 7 8 18 23 23 37 42
nums = [1, 8, 2, 23, 7, -4, 18, 23, 42, 37, 2] for i in range(11):
print(heapq.heappop(nums))
1 2 -4 2 8 7 18 23 23 37 42
可见不初始化直接heapq.heappop前三个元素依然是最小的三个,但是不会被排序。
2、堆排序应用
问题
怎样从一个集合中获得最大或者最小的N个元素列表?
解决方案
heapq模块有两个函数:nlargest() 和 nsmallest() 可以完美解决这个问题。
import heapq
nums = [1, 8, 2, 23, 7, -4, 18, 23, 42, 37, 2]
print(heapq.nlargest(3, nums)) # Prints [42, 37, 23]
print(heapq.nsmallest(3, nums)) # Prints [-4, 1, 2]
和sorted类似,它们也接受关键字参数,
portfolio = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}
]
cheap = heapq.nsmallest(3, portfolio, key=lambda s: s['price'])
expensive = heapq.nlargest(3, portfolio, key=lambda s: s['price'])
总结
- 当要查找的元素个数相对比较小的时候,函数nlargest() 和 nsmallest()是很合适的。
- 如果你仅仅想查找唯一的最小或最大(N=1)的元素的话,那么使用min()和max()函数会更快些。
- 类似的,如果N的大小和集合大小接近的时候,通常先排序这个集合然后再使用切片操作会更快点(sorted(items)[:N] 或者是 sorted(items)[-N:])。
- 需要在正确场合使用函数nlargest() 和 nsmallest()才能发挥它们的优势(如果N快接近集合大小了,那么使用排序操作会更好些)。
- 由于push和pop操作时间复杂度为O(N),其中N是堆的大小,因此就算是N很大的时候它们运行速度也依旧很快。
二、容器排序
python中两个容器比较大小,会从第0个元素开始比较,相等则下一位比较,不相等则返回,也就是说即使后面元素数目不一致或者不能比较大小也能够比较容器出大小。
class Item:
def __init__(self, name):
self.name = name
def __repr__(self):
return 'Item({!r})'.format(self.name) a = Item('foo')
b = Item('bar')
a < b # ---------------------------------------------------------------------------
# TypeError Traceback (most recent call last)
# <ipython-input-34-3bf0061fd9c0> in <module>()
# 1 a = Item('foo')
# 2 b = Item('bar')
# ----> 3 a < b
#
# TypeError: '<' not supported between instances of 'Item' and 'Item' a = (1, Item('foo'))
b = (5, Item('bar'))
a < b # True
甚至,
(1,2,3,4)>(0,1) # True
三、优先级队列实践
import heapq class PriorityQueue:
def __init__(self):
self._queue = []
self._index = 0 def push(self, item, priority):
heapq.heappush(self._queue, (-priority, self._index, item))
self._index += 1 def pop(self):
return heapq.heappop(self._queue) class Item:
def __init__(self, name):
self.name = name
def __repr__(self):
return 'Item({!r})'.format(self.name)
>>> q = PriorityQueue()
>>> q.push(Item('foo'), 1)
>>> q.push(Item('bar'), 5)
>>> q.push(Item('spam'), 4)
>>> q.push(Item('grok'), 1)
>>> q.pop()
Item('bar')
>>> q.pop()
Item('spam')
>>> q.pop()
Item('foo')
>>> q.pop()
Item('grok')
>>>
在上面代码中,队列包含了一个 (-priority, index, item) 的元组。优先级为负数的目的是使得元素按照优先级从高到低排序。这个跟普通的按优先级从低到高排序的堆排序恰巧相反。
index变量的作用是保证同等优先级元素的正确排序。通过保存一个不断增加的index下标变量,可以确保元素安装它们插入的顺序排序。而且,index变量也在相同优先级元素比较的时候起到重要作用。
『Python CoolBook:heapq』数据结构和算法_heapq堆队列算法&容器排序的更多相关文章
- 『Python CoolBook』Cython
github地址 使用Cython导入库的话,需要一下几个文件: .c:C函数源码 .h:C函数头 .pxd:Cython函数头 .pyx:包装函数 setup.py:python 本节示例.c和.h ...
- 『Python基础-10』字典
# 『Python基础-10』字典 目录: 1.字典基本概念 2.字典键(key)的特性 3.字典的创建 4-7.字典的增删改查 8.遍历字典 1. 字典的基本概念 字典一种key - value 的 ...
- 『Python基础-1 』 编程语言Python的基础背景知识
#『Python基础-1 』 编程语言Python的基础背景知识 目录: 1.编程语言 1.1 什么是编程语言 1.2 编程语言的种类 1.3 常见的编程语言 1.4 编译型语言和解释型语言的对比 2 ...
- 『Python基础-12』各种推导式(列表推导式、字典推导式、集合推导式)
# 『Python基础-12』各种推导式(列表推导式.字典推导式.集合推导式) 推导式comprehensions(又称解析式),是Python的一种独有特性.推导式是可以从一个数据序列构建另一个新的 ...
- 『Python基础-11』集合 (set)
# 『Python基础-11』集合 (set) 目录: 集合的基本知识 集合的创建 访问集合里的值 向集合set增加元素 移除集合中的元素 集合set的运算 1. 集合的基本知识 集合(set)是一个 ...
- 『Python基础-9』元祖 (tuple)
『Python基础-9』元祖 (tuple) 目录: 元祖的基本概念 创建元祖 将列表转化为元组 查询元组 更新元组 删除元组 1. 元祖的基本概念 元祖可以理解为,不可变的列表 元祖使用小括号括起所 ...
- 『Python基础-8』列表
『Python基础-8』列表 1. 列表的基本概念 列表让你能够在一个地方存储成组的信息,其中可以只包含几个 元素,也可以包含数百万个元素. 列表由一系列按特定顺序排列的元素组成.你可以创建包含字母表 ...
- 『Python基础-7』for循环 & while循环
『Python基础-7』for循环 & while循环 目录: 循环语句 for循环 while循环 循环的控制语句: break,continue,pass for...else 和 whi ...
- 『Python基础-6』if语句, if-else语句
# 『Python基础-6』if语句, if-else语句 目录: 条件测试 if语句 if-else语句 1. 条件测试 每条if语句的核心都是一个值为True或False的表达式,这种表达式被称为 ...
随机推荐
- 关于STM32时钟系统
初学STM32,感觉最蛋疼的是它的时钟系统,每次看到它的那个时钟树就有点晕,虽然看了很多这方面的资料,甚至也已经写过很多STM32的模块代码,做过一些小项目,但一直还是对这一块模模糊糊,似懂非懂,所以 ...
- css3 伸缩百分比的调整
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 关于什么是SpringMVC,和SpringMVC基于xml配置、注解配置、纯注解配置
首先我们先要了解一下,什么是SpringMVC? SpringMVC是Spring框架内置的MVC的实现.SpringMVC就是一个Spring内置的MVC子框架,也就是说SpringMVC的相关包都 ...
- 自动化安装-【kickstart】
批量自动安装软件介绍 kickstart 是一种无人值守的安装方式,工作原理是在安装过程中记录人工干预填写的各种参数,并生成以个名为ks.cfg(自动应答文件)的文件,如果在自动安装过程中出现要填写参 ...
- [py]js前端求和与flask后端求和
index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- 【LeetCode每天一题】Word Search(搜索单词)
Given a 2D board and a word, find if the word exists in the grid.The word can be constructed from le ...
- vue2Leaflet使用 Vue2Leaflet-master 的demo
首先下载该demo 地址:https://github.com/KoRiGaN/Vue2Leaflet 下载后可以运行里面的例子,在examples文件夹内,该文件夹本身就是一个完整的项目 然后cmd ...
- VC++运行库 集32位/64位整合版
运行程序时,win7/win10(x86和x64)常会遇到缺少什么缺少msvc***.dll问题 安装下面链接提供的程序,安装后,便可解决. [2016-10-10]Microsoft Visual ...
- 爬虫出现Forbidden by robots.txt(转载 https://blog.csdn.net/zzk1995/article/details/51628205)
先说结论,关闭scrapy自带的ROBOTSTXT_OBEY功能,在setting找到这个变量,设置为False即可解决. 使用scrapy爬取淘宝页面的时候,在提交http请求时出现debug信息F ...
- java项目打包成可运行的jar,main方法带参数
转载 原文地址:http://www.cnblogs.com/neillee/p/6063808.html#commentform 将 java 项目打包成可运行的 jar 包(main 函数带参数) ...