SequenceFile文件
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)。目前,也有不少人在该文件的基础之上提出了一些HDFS中小文件存储的解决方案,他们的基本思路就是将小文件进行合并成一个大文件,同时对这些小文件的位置信息构建索引。不过,这类解决方案还涉及到Hadoop的另一种文件格式——MapFile文件。SequenceFile文件并不保证其存储的key-value数据是按照key的某个顺序存储的,同时不支持append操作。
在SequenceFile文件中,每一个key-value被看做是一条记录(Record),因此基于Record的压缩策略,SequenceFile文件可支持三种压缩类型(SequenceFile.CompressionType):
NONE: 对records不进行压缩;
RECORD: 仅压缩每一个record中的value值;
BLOCK: 将一个block中的所有records压缩在一起;
那么,基于这三种压缩类型,Hadoop提供了对应的三种类型的Writer:
SequenceFile.Writer 写入时不压缩任何的key-value对(Record);
- public static class Writer implements java.io.Closeable {
- ...
- //初始化Writer
- void init(Path name, Configuration conf, FSDataOutputStream out, Class keyClass, Class valClass, boolean compress, CompressionCodec codec, Metadata metadata) throws IOException {
- this.conf = conf;
- this.out = out;
- this.keyClass = keyClass;
- this.valClass = valClass;
- this.compress = compress;
- this.codec = codec;
- this.metadata = metadata;
- //创建非压缩的对象序列化器
- SerializationFactory serializationFactory = new SerializationFactory(conf);
- this.keySerializer = serializationFactory.getSerializer(keyClass);
- this.keySerializer.open(buffer);
- this.uncompressedValSerializer = serializationFactory.getSerializer(valClass);
- this.uncompressedValSerializer.open(buffer);
- //创建可压缩的对象序列化器
- if (this.codec != null) {
- ReflectionUtils.setConf(this.codec, this.conf);
- this.compressor = CodecPool.getCompressor(this.codec);
- this.deflateFilter = this.codec.createOutputStream(buffer, compressor);
- this.deflateOut = new DataOutputStream(new BufferedOutputStream(deflateFilter));
- this.compressedValSerializer = serializationFactory.getSerializer(valClass);
- this.compressedValSerializer.open(deflateOut);
- }
- }
- //添加一条记录(key-value,对象值需要序列化)
- public synchronized void append(Object key, Object val) throws IOException {
- if (key.getClass() != keyClass)
- throw new IOException("wrong key class: "+key.getClass().getName() +" is not "+keyClass);
- if (val.getClass() != valClass)
- throw new IOException("wrong value class: "+val.getClass().getName() +" is not "+valClass);
- buffer.reset();
- //序列化key(将key转化为二进制数组),并写入缓存buffer中
- keySerializer.serialize(key);
- int keyLength = buffer.getLength();
- if (keyLength < 0)
- throw new IOException("negative length keys not allowed: " + key);
- //compress在初始化是被置为false
- if (compress) {
- deflateFilter.resetState();
- compressedValSerializer.serialize(val);
- deflateOut.flush();
- deflateFilter.finish();
- } else {
- //序列化value值(不压缩),并将其写入缓存buffer中
- uncompressedValSerializer.serialize(val);
- }
- //将这条记录写入文件流
- checkAndWriteSync(); // sync
- out.writeInt(buffer.getLength()); // total record length
- out.writeInt(keyLength); // key portion length
- out.write(buffer.getData(), 0, buffer.getLength()); // data
- }
- //添加一条记录(key-value,二进制值)
- public synchronized void appendRaw(byte[] keyData, int keyOffset, int keyLength, ValueBytes val) throws IOException {
- if (keyLength < 0)
- throw new IOException("negative length keys not allowed: " + keyLength);
- int valLength = val.getSize();
- checkAndWriteSync();
- //直接将key-value写入文件流
- out.writeInt(keyLength+valLength); // total record length
- out.writeInt(keyLength); // key portion length
- out.write(keyData, keyOffset, keyLength); // key
- val.writeUncompressedBytes(out); // value
- }
- ...
- }
SequenceFile.RecordCompressWriter写入时只压缩key-value对(Record)中的value;
- static class RecordCompressWriter extends Writer {
- ...
- public synchronized void append(Object key, Object val) throws IOException {
- if (key.getClass() != keyClass)
- throw new IOException("wrong key class: "+key.getClass().getName() +" is not "+keyClass);
- if (val.getClass() != valClass)
- throw new IOException("wrong value class: "+val.getClass().getName() +" is not "+valClass);
- buffer.reset();
- //序列化key(将key转化为二进制数组),并写入缓存buffer中
- keySerializer.serialize(key);
- int keyLength = buffer.getLength();
- if (keyLength < 0)
- throw new IOException("negative length keys not allowed: " + key);
- //序列化value值(不压缩),并将其写入缓存buffer中
- deflateFilter.resetState();
- compressedValSerializer.serialize(val);
- deflateOut.flush();
- deflateFilter.finish();
- //将这条记录写入文件流
- checkAndWriteSync(); // sync
- out.writeInt(buffer.getLength()); // total record length
- out.writeInt(keyLength); // key portion length
- out.write(buffer.getData(), 0, buffer.getLength()); // data
- }
- /** 添加一条记录(key-value,二进制值,value已压缩) */
- public synchronized void appendRaw(byte[] keyData, int keyOffset,
- int keyLength, ValueBytes val) throws IOException {
- if (keyLength < 0)
- throw new IOException("negative length keys not allowed: " + keyLength);
- int valLength = val.getSize();
- checkAndWriteSync(); // sync
- out.writeInt(keyLength+valLength); // total record length
- out.writeInt(keyLength); // key portion length
- out.write(keyData, keyOffset, keyLength); // 'key' data
- val.writeCompressedBytes(out); // 'value' data
- }
- } // RecordCompressionWriter
- ...
- }
SequenceFile.BlockCompressWriter 写入时将一批key-value对(Record)压缩成一个Block;
- static class BlockCompressWriter extends Writer {
- ...
- void init(int compressionBlockSize) throws IOException {
- this.compressionBlockSize = compressionBlockSize;
- keySerializer.close();
- keySerializer.open(keyBuffer);
- uncompressedValSerializer.close();
- uncompressedValSerializer.open(valBuffer);
- }
- /** Workhorse to check and write out compressed data/lengths */
- private synchronized void writeBuffer(DataOutputBuffer uncompressedDataBuffer) throws IOException {
- deflateFilter.resetState();
- buffer.reset();
- deflateOut.write(uncompressedDataBuffer.getData(), 0, uncompressedDataBuffer.getLength());
- deflateOut.flush();
- deflateFilter.finish();
- WritableUtils.writeVInt(out, buffer.getLength());
- out.write(buffer.getData(), 0, buffer.getLength());
- }
- /** Compress and flush contents to dfs */
- public synchronized void sync() throws IOException {
- if (noBufferedRecords > 0) {
- super.sync();
- // No. of records
- WritableUtils.writeVInt(out, noBufferedRecords);
- // Write 'keys' and lengths
- writeBuffer(keyLenBuffer);
- writeBuffer(keyBuffer);
- // Write 'values' and lengths
- writeBuffer(valLenBuffer);
- writeBuffer(valBuffer);
- // Flush the file-stream
- out.flush();
- // Reset internal states
- keyLenBuffer.reset();
- keyBuffer.reset();
- valLenBuffer.reset();
- valBuffer.reset();
- noBufferedRecords = 0;
- }
- }
- //添加一条记录(key-value,对象值需要序列化)
- public synchronized void append(Object key, Object val) throws IOException {
- if (key.getClass() != keyClass)
- throw new IOException("wrong key class: "+key+" is not "+keyClass);
- if (val.getClass() != valClass)
- throw new IOException("wrong value class: "+val+" is not "+valClass);
- //序列化key(将key转化为二进制数组)(未压缩),并写入缓存keyBuffer中
- int oldKeyLength = keyBuffer.getLength();
- keySerializer.serialize(key);
- int keyLength = keyBuffer.getLength() - oldKeyLength;
- if (keyLength < 0)
- throw new IOException("negative length keys not allowed: " + key);
- WritableUtils.writeVInt(keyLenBuffer, keyLength);
- //序列化value(将value转化为二进制数组)(未压缩),并写入缓存valBuffer中
- int oldValLength = valBuffer.getLength();
- uncompressedValSerializer.serialize(val);
- int valLength = valBuffer.getLength() - oldValLength;
- WritableUtils.writeVInt(valLenBuffer, valLength);
- // Added another key/value pair
- ++noBufferedRecords;
- // Compress and flush?
- int currentBlockSize = keyBuffer.getLength() + valBuffer.getLength();
- //block已满,可将整个block进行压缩并写入文件流
- if (currentBlockSize >= compressionBlockSize) {
- sync();
- }
- }
- /**添加一条记录(key-value,二进制值,value已压缩). */
- public synchronized void appendRaw(byte[] keyData, int keyOffset, int keyLength, ValueBytes val) throws IOException {
- if (keyLength < 0)
- throw new IOException("negative length keys not allowed");
- int valLength = val.getSize();
- // Save key/value data in relevant buffers
- WritableUtils.writeVInt(keyLenBuffer, keyLength);
- keyBuffer.write(keyData, keyOffset, keyLength);
- WritableUtils.writeVInt(valLenBuffer, valLength);
- val.writeUncompressedBytes(valBuffer);
- // Added another key/value pair
- ++noBufferedRecords;
- // Compress and flush?
- int currentBlockSize = keyBuffer.getLength() + valBuffer.getLength();
- if (currentBlockSize >= compressionBlockSize) {
- sync();
- }
- }
- } // RecordCompressionWriter
- ...
- }
源码中,block的大小compressionBlockSize默认值为1000000,也可通过配置参数io.seqfile.compress.blocksize来指定。
根据三种压缩算法,共有三种类型的SequenceFile文件格式:
1). Uncompressed SequenceFile
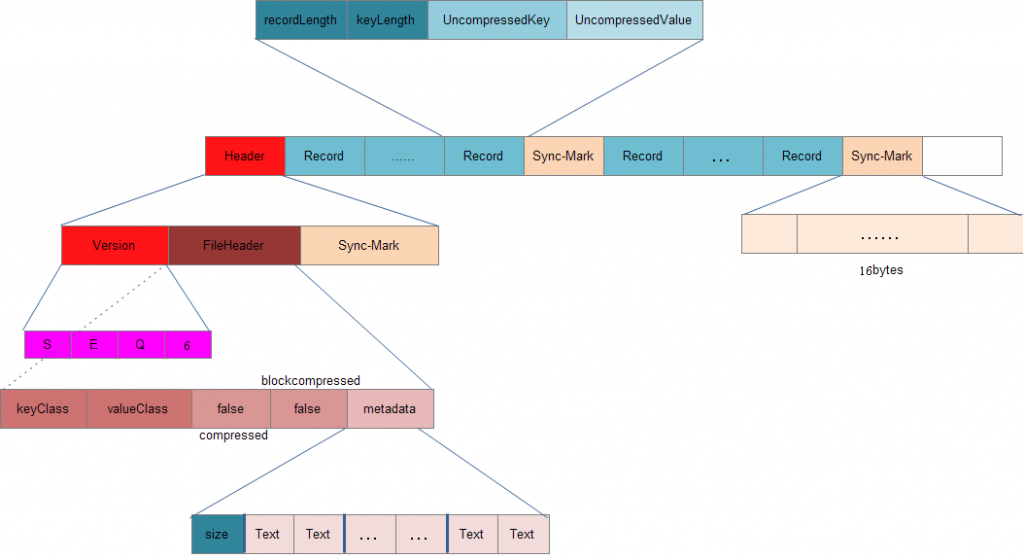
2). Record-Compressed SequenceFile

3). Block-Compressed SequenceFile

SequenceFile文件的更多相关文章
- Hadoop 写SequenceFile文件 源代码
package com.tdxx.hadoop.sequencefile; import java.io.IOException; import org.apache.hadoop.conf.Conf ...
- 基于Hadoop Sequencefile的小文件解决方案
一.概述 小文件是指文件size小于HDFS上block大小的文件.这样的文件会给hadoop的扩展性和性能带来严重问题.首先,在HDFS中,任何block,文件或者目录在内存中均以对象的形式存储,每 ...
- hadoop 将HDFS上多个小文件合并到SequenceFile里
背景:hdfs上的文件最好和hdfs的块大小的N倍.如果文件太小,浪费namnode的元数据存储空间以及内存,如果文件分块不合理也会影响mapreduce中map的效率. 本例中将小文件的文件名作为k ...
- 5.4.1 sequenceFile读写文件、记录边界、同步点、压缩排序、格式
5.4.1 sequenceFile读写文件.记录边界.同步点.压缩排序.格式 HDFS和MapReduce是针对大文件优化的存储文本记录,不适合二进制类型的数据.SequenceFile作 ...
- Hadoop SequenceFile数据结构介绍及读写
在一些应用中,我们需要一种特殊的数据结构来存储数据,并进行读取,这里就分析下为什么用SequenceFile格式文件. Hadoop SequenceFile Hadoop提供的SequenceFil ...
- Hadoop基于文件的数据结构及实例
基于文件的数据结构 两种文件格式: 1.SequenceFile 2.MapFile SequenceFile 1.SequenceFile文件是Hadoop用来存储二进制形式的<key,val ...
- Hadoop之SequenceFile
Hadoop序列化文件SequenceFile能够用于解决大量小文件(所谓小文件:泛指小于black大小的文件)问题,SequenceFile是Hadoop API提供的一种二进制文件支持.这样的二进 ...
- 使用代码查看Nutch爬取的网站后生成的SequenceFile信息
必须针对data文件中的value类型来使用对应的类来查看(把这个data文件,放到了本地Windows的D盘根目录下). 代码: package cn.summerchill.nutch; impo ...
- SequenceFile实例操作
HDFS API提供了一种二进制文件支持,直接将<key,value>对序列化到文件中,该文件格式是不能直接查看的,可以通过hadoop dfs -text命令查看,后面跟上Sequen ...
随机推荐
- (网页)javaScript增删改查(转)
转自CSDN: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> ...
- 心迹 使用说明&功能展示
下载地址 心迹.apk 更新于2018.8.9 11:47 测试账号:用户名testing,密码testing 项目地址 GitHub 注册&登录 第一次使用心迹app时,必须进行注册,以便区 ...
- vue权威指南笔记01——样式的设置
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- CENTOS7 SYSTEMD SERVICE 将自己的程序放入自动启动的系统服务
1. 进入文件夹cd /usr/lib/systemd/system 2. 创建文件somed.service 3. 输入内容.如果是监控类程序,需要输入Type=forking[Unit]Descr ...
- 安装office2010提示要安装MSXML6.10.1129.0解决方法
系统win7 32位 安装office2010出现了错误,提示要安装MSXML6.10.1129.0解决方法 1.下载MSXML6.10.1129.0进行安装 2.若本机已安装过不管用: a.在运行里 ...
- Centos7使用Docker安装Gogs搭建git服务器
gihub地址:https://github.com/gogs/gogs gogs官网:https://gogs.io/ gihub官方docker安装gogs方法:https://github.co ...
- Class doesn't contain any JAX-RS annotated method
项目中使用了Jersey RESTful风格的注解 , 根据错误提示就知道了 , 在类中没有带注解的方法 ,所以只要在方法上添加 @path() 注解就行了,至少要有一个方法带有Jersey注解
- python基础 - 元组操作
元组 tuple 元组是不可变对象. 元组初始化 t = tuple() t = () t = tuple(range(1,7,2)) t = (1,2,3,4,5,1) t = (1,) t = ( ...
- 建立标准编码规则(二)-DiagnosticAnalyzer 增加诊断分析代码
1.使用语法树 当我们要编写一个规则,例如 检测正值表达式的时候,如何编写有效的规则呢 Regex.Match("my text", @"\pXXX"); 这里 ...
- indexOf() 使用方法(数组去重)
对于indexOf()的用法一直停留在查找第几个字符串,却不知道它能用到数组去重中,首先还是温顾下indexOf()的语法: <!DOCTYPE html> <html lang=& ...