【dataX】阿里开源ETL工具——dataX简单上手
一、概述
1.是什么?
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
开源地址:https://github.com/alibaba/DataX
二、简介
1.设计架构
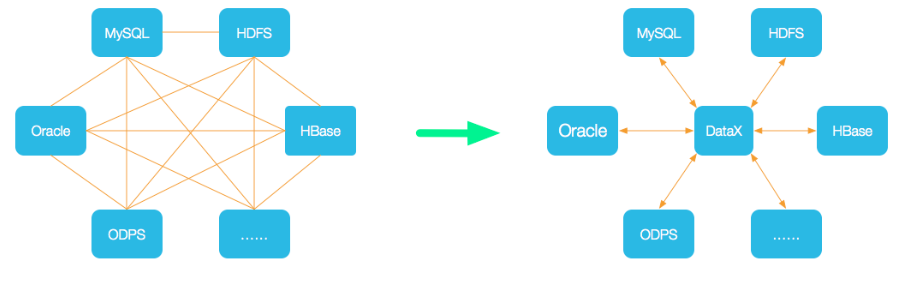
数据交换通过DataX进行中转,任何数据源只要和DataX连接上即可以和已实现的任意数据源同步
2.框架结构

核心组件:
Reader:数据采集模块,负责从源采集数据
Writer:数据写入模块,负责写入目标库
Framework:数据传输通道,负责处理数据缓冲等
以上只需要重写Reader与Writer插件,即可实现新数据源支持
支持主流数据源,详见:https://github.com/alibaba/DataX/blob/master/introduction.md
从一个JOB来理解datax的核心模块组件:
datax完成单个数据同步的作业,称为Job,job会负责数据清理、任务切分等工作;
任务启动后,Job会根据不同源的切分策略,切分成多个Task并发执行,Task就是执行作业的最小单元
切分完成后,根据Scheduler模块,将Task组合成TaskGroup,每个group负责一定的并发和分配Task
三、入门
1.安装
参考官方文档
提取为安装随笔:https://www.cnblogs.com/jiangbei/p/10901201.html
2.使用
核心就是编写配置文件(当前版本使用JSON)
在datax服务器上运行:
python bin/datax.py -r mysqlreader -w hdfswriter
即可获取配置模板
【配置文件】:
先看一个示例:
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "",
"password": "",
"connection": [{
"querySql": [
"SELECT Id,CopId,BrandId,PayType,TradeNo,OutTradeNo,TotalFee,PayTotalFee,PayCashFee,PayCouponFee,RefundFee,ShopId,VipOldCode,VipId,UserCode,PayStatus,IsReverse,CreateDate,UNIX_TIMESTAMP(LastModifiedDate) as LastModifiedDate FROM mall_out_sales_order_pay where brandid=63 order by createDate asc;"
],
"jdbcUrl": [
"jdbc:mysql://192.168.12.41:3306/ezp-pay"
]
}]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "",
"password": "",
"dateFormat": "YYYY-MM-dd hh:mm:ss",
"column": [
"Id",
"CopId",
"BrandId",
"PayType",
"TradeNo",
"OutTradeNo",
"TotalFee",
"PayTotalFee",
"PayCashFee",
"PayCouponFee",
"RefundFee",
"ShopId",
"VipOldCode",
"VipId",
"UserCode",
"PayStatus",
"IsReverse",
"CreateDate",
"LastModifiedDate"
],
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [
"delete from pay_order where brandid=63"
],
"connection": [{
"jdbcUrl": "jdbc:mysql://127.0.0.1:3306/ezp-pay",
"table": [
"pay_order"
]
}]
}
}
}]
}
}
JSON配置文件
整个配置文件是一个Job配置文件,以Job为起手根元素,Job下面两个子元素配置项:setting和content,
其中,setting描述任务本身的信息,content描述源(reader)和目的端(writer)的信息:

其中,content下又分为reader和writer两块,分别对应源端和目的端:

各reader与writer插件的文档直接点击对应的文件夹进入doc即可!
3.示例
编写一个Mysql到本地打印的Job:
根据Mysqlreader插件编写配置文件:
{
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"column": [
"id",
"age",
"name"
],
"connection": [
{
"table": [
"girl"
],
"jdbcUrl": [
"jdbc:mysql://192.168.19.129:3306/mysql"
]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print":true
}
}
}
]
}
}
根据自检脚本(文件颜色浅绿色),可以知道需要是可执行文件,添加权限:
chmod +x mysqltest.json
使用运行命令,运行即可:(进入bin目录运行命令如下)
python datax.py ../job/mysqltest.json
有时是希望灵活一点的自定义的配置,则可参考如下json配置:
{
"job": {
"setting": {
"speed": {
"channel":1
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "root",
"connection": [
{
"querySql": [
"select db_id,on_line_flag from db_info where db_id < 10;"
],
"jdbcUrl": [
"jdbc:mysql://bad_ip:3306/database",
"jdbc:mysql://127.0.0.1:bad_port/database",
"jdbc:mysql://127.0.0.1:3306/database"
]
}
]
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": false,
"encoding": "UTF-8"
}
}
}
]
}
}
四、拓展
1.调度
任务很少,情景简单的情况下,使用Linux自带的corntab即可,当然,正常的时候推荐使用调度平台
这里推荐airflow(其他相关的azkaban、oozie等调度不展开)
【dataX】阿里开源ETL工具——dataX简单上手的更多相关文章
- 【转】阿里出品的ETL工具dataX初体验
原文链接:https://www.imooc.com/article/15640 来源:慕课网 我的毕设选择了大数据方向的题目.大数据的第一步就是要拿到足够的数据源.现实情况中我们需要的数据源分布在不 ...
- 开源ETL工具kettle系列之常见问题
开源ETL工具kettle系列之常见问题 摘要:本文主要介绍使用kettle设计一些ETL任务时一些常见问题,这些问题大部分都不在官方FAQ上,你可以在kettle的论坛上找到一些问题的答案 1. J ...
- ETL工具Datax、sqoop、kettle 的区别
一.Sqoop主要特点: 1.可以将关系型数据库中的数据导入到hdfs,hive,hbase等hadoop组件中,也可以将hadoop组件中的数据导入到关系型数据库中: 2.sqoop在导入导出数据时 ...
- 开源ETL工具之Kettle介绍
What 起源 Kettle是一个Java编写的ETL工具,主作者是Matt Casters,2003年就开始了这个项目,最新稳定版为7.1. 2005年12月,Kettle从2.1版本开始进入了开源 ...
- 开源ETL工具kettle--数据迁移
背景 因为项目的需求,须要将数据从Oracle迁移到MSSQL,不是简单的数据复制,而是表结构和字段名都不一样.甚至须要处理编码规范不一致的情况,例如以下图所看到的 watermark/2/text/ ...
- 初识阿里开源诊断工具Arthas
上个月,阿里开源了一个名为Arthas的监控工具.恰逢近期自己在写多线程处理业务,由此想到了一个问题. 如果在本机开发调试,IDE可以看到当前的活动线程,例如IntelliJ IDEA,线程是运行还是 ...
- 阿里ETL工具datax学习(一)
阿里云开源离线同步工具DataX3.0介绍 一. DataX3.0概览 DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).HDFS.Hive.Ma ...
- 开源作业调度工具实现开源的Datax、Sqoop、Kettle等ETL工具的作业批量自动化调度
1.阿里开源软件:DataX DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).HDFS.Hive.ODPS.HBase.FTP等各种异构数据源之间稳 ...
- ETL工具框架开源软件
http://www.oschina.net/project/tag/453/etl 开源ETL工具 Kettle Talend KETL CloverETL Apatar Scriptella ET ...
随机推荐
- The ADB instructions
adb kill-server 杀死adb服务. adb start-server 开启adb服务. adb install xxx.apk 安装应用. adb uninstall 应用的包名.卸载应 ...
- wap2app(三)-- 添加引导页
1.在client_index.html文件中添加如下代码: <script type="text/javascript"> if(window.plus){ plus ...
- mv,rm等命令出现unrecognized option提示的解决方法
出现这个提示,一般是由于命令操作的文件名最前面有"--"字符, 让命令误以为是--开头的长选项 解决: 命令后加上"--", shell把 -- 之后的参数当做 ...
- springboot中使用mybatis显示执行sql
springboot 中使用mybatis显示执行sql的配置,在properties中添加如下 logging.你的包名=debug 2018-11-27 16:35:43.044 [DubboSe ...
- The Tomcat connector configured to listen on port 8080 failed to start. The port may already be in use or the connector may be misconfigured
springboot 8080端口被占用报错:The Tomcat connector configured to listen on port 8080 failed to start. The p ...
- C#检测U盘是否插入
public partial class Form1 : Form { #region u盘属性 public const int WM_DEVICECHANGE = 0x219;//U盘插入后,OS ...
- php二维数组去重
php二维数组去重 前言:php一维数组去重很简单,直接array_unique($arr)即可,但是二维数组去重就得自己去写了 二维数组去重方法: /* * 二维数组去重 * 注意:二维数组中的元素 ...
- web开发中遇到的乱码问题
相信大家在web开发中会遇到乱码问题,有页面乱码,请求乱码,数据库乱码等等,下面我这边列举一下针对不同情况的乱码的解决方案: 1.相应数据乱码: //只需要在后台接口方法里面的开头写上这样一句话指定响 ...
- VRS的GPS/BDS双系统网元固定存在的问题
问题如下:部分网元固定卫星数少于2个. 另外:北方xinkong的网元组网也存在问题
- Java实现对zip和rar文件的解压缩
通过java实现对zip和rar文件的解压缩