【Spark2.0源码学习】-8.SparkContext与Application介绍
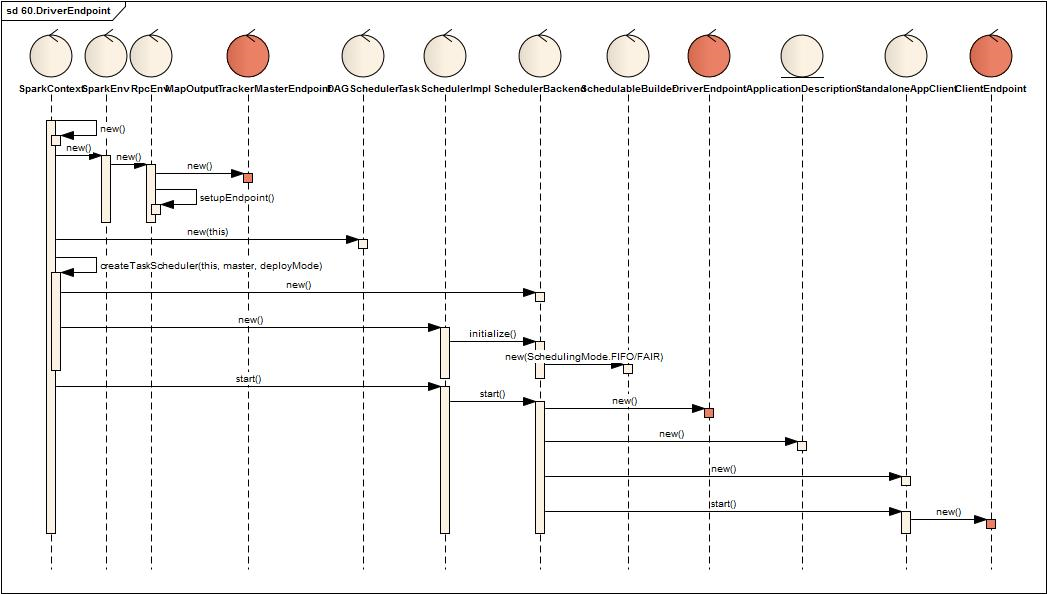

- 内部创建一个SparkEnv,SparkEnv内部创建一个RpcEnv
- RpcEnv内部创建并注册一个MapOutputTrackerMasterEndpoint(该Endpoint暂不介绍)
- 接着创建DAGScheduler,TaskSchedulerImpl,SchedulerBackend
- TaskSchedulerImpl创建时创建SchedulableBuilder,SchedulableBuilder根据类型分为FIFOSchedulableBuilder,FairSchedulableBuilder两类
- 最后启动TaskSchedulerImpl,TaskSchedulerImpl启动SchedulerBackend
- SchedulerBackend启动时创建ApplicationDescription,DriverEndpoint, StandloneAppClient
- StandloneAppClient内部包括一个ClientEndpoint
.png)
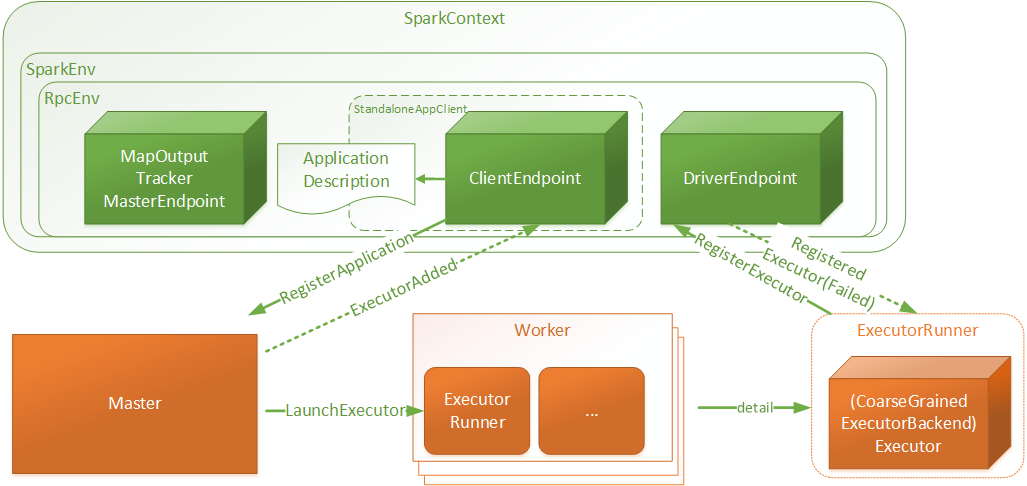
- SparkContext:是用户Spark执行任务的上下文,用户程序内部使用Spark提供的Api直接或间接创建一个SparkContext
- SparkEnv:用户执行的环境信息,包括通信相关的端点
- RpcEnv:SparkContext中远程通信环境
- ApplicationDescription:应用程序描述信息,主要包含appName, maxCores, memoryPerExecutorMB, coresPerExecutor, Command(
CoarseGrainedExecutorBackend), appUiUrl等 - ClientEndpoint:客户端端点,启动后向Master发起注册RegisterApplication请求
- Master:接受RegisterApplication请求后,进行Worker资源分配,并向分配的资源发起LaunchExecutor指令
- Worker:接受LaunchExecutor指令后,运行ExecutorRunner
- ExecutorRunner:运行applicationDescription的Command命令,最终Executor,同时向DriverEndpoint注册Executor信息
.png)

- 如果waitingApp配置了app.desc.coresPerExecutor:
- 轮询所有有效可分配的worker,每次分配一个executor,executor的核数为minCoresPerExecutor(app.desc.coresPerExecutor),直到不存在有效可分配资源或者app依赖的资源已全部被分配
- 如果waitingApp没有配置app.desc.coresPerExecutor:
- 轮询所有有效可分配的worker,每个worker分配一个executor,executor的核数为从minCoresPerExecutor(为固定值1)开始递增,直到不存在有效可分配资源或者app依赖的资源已全部被分配
- 其中有效可分配worker定义为满足一次资源分配的worker:
- cores满足:usableWorkers(pos).coresFree - assignedCores(pos) >= minCoresPerExecutor,
- memory满足(如果是新的Executor):usableWorkers(pos).memoryFree - assignedExecutors(pos) * memoryPerExecutor >= memoryPerExecutor
- 注意:Master针对于applicationInfo进行资源分配时,只有存在有效可用的资源就直接分配,而分配剩余的app.coresLeft则等下一次再进行分配


- 在Worker的tempDir下面创建application以及executor的目录,并chmod700操作权限
- 创建并启动ExecutorRunner进行Executor的创建
- 向master发送Executor的状态情况
- 新线程【ExecutorRunner for [executorId]】读取ApplicationDescription将其中Command转化为本地的Command命令
- 调用Command并将日志输出至executor目录下的stdout,stderr日志文件中,Command对应的java类为CoarseGrainedExecutorBackend
- 创建一个SparkEnv,创建ExecutorEndpoint(CoarseGrainedExecutorBackend),以及WorkerWatcher
- ExecutorEndpoint创建并启动后,向DriverEndpoint发送RegisterExecutor请求并等待返回
- DriverEndpoint处理RegisterExecutor请求,返回ExecutorEndpointRegister的结果
- 如果注册成功,ExecutorEndpoint内部再创建Executor的处理对象
【Spark2.0源码学习】-8.SparkContext与Application介绍的更多相关文章
- 【Spark2.0源码学习】-3.Endpoint模型介绍
Spark作为分布式计算框架,多个节点的设计与相互通信模式是其重要的组成部分. 一.组件概览 对源码分析,对于设计思路理解如下: RpcEndpoint: ...
- 【Spark2.0源码学习】-1.概述
Spark作为当前主流的分布式计算框架,其高效性.通用性.易用性使其得到广泛的关注,本系列博客不会介绍其原理.安装与使用相关知识,将会从源码角度进行深度分析,理解其背后的设计精髓,以便后续 ...
- spark2.0源码学习
[Spark2.0源码学习]-1.概述 [Spark2.0源码学习]-2.一切从脚本说起 [Spark2.0源码学习]-3.Endpoint模型介绍 [Spark2.0源码学习]-4.Master启动 ...
- 【Spark2.0源码学习】-2.一切从脚本说起
从脚本说起 在看源码之前,我们一般会看相关脚本了解其初始化信息以及Bootstrap类,Spark也不例外,而Spark我们启动三端使用的脚本如下: %SPARK_HOME%/sbin/st ...
- 【Spark2.0源码学习】-6.Client启动
Client作为Endpoint的具体实例,下面我们介绍一下Client启动以及OnStart指令后的额外工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/bin/jav ...
- 【Spark2.0源码学习】-4.Master启动
Master作为Endpoint的具体实例,下面我们介绍一下Master启动以及OnStart指令后的相关工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/ ...
- 【Spark2.0源码学习】-5.Worker启动
Worker作为Endpoint的具体实例,下面我们介绍一下Worker启动以及OnStart指令后的额外工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/ ...
- 【Spark2.0源码学习】-9.Job提交与Task的拆分
在前面的章节Client的加载中,Spark的DriverRunner已开始执行用户任务类(比如:org.apache.spark.examples.SparkPi),下面我们开始针对于用 ...
- 【Spark2.0源码学习】-10.Task执行与回馈
通过上一节内容,DriverEndpoint最终生成多个可执行的TaskDescription对象,并向各个ExecutorEndpoint发送LaunchTask指令,本节内容将关注Exe ...
随机推荐
- C语言数组指针
C语言中的数组指针与指针数组: ·数组指针一.区分 首先我们需要了解什么是数组指针以及什么是指针数组,如下: int *p[5];int (*p)[5];数组指针的意思即为通过指针引用数组,p先和*结 ...
- Spring生态研习【二】:SpEL(Spring Expression Language)
1. SpEL功能简介 它是spring生态里面的一个功能强大的描述语言,支在在运行期间对象图里面的数据查询和数据操作.语法和标准的EL一样,但是支持一些额外的功能特性,最显著的就是方法调用以及基本字 ...
- 用a标签实现submit提交按钮的效果
今天做了一个小项目练手,要求点击a标签后实现post提交的效果,看到这个的时候心理还是有一丝丝懵逼的,不过在朕的十秒钟思考之后有了头绪... 首先表单 <form action="te ...
- Java继承(下)
Object类 在www.oracle中找到java 中的java.lang在中找到object类中找到可以看到在java语言中的定义 如何修改object中的equals类及测试 在object中类 ...
- 《Java程序设计》 第二周学习总结
20175334 <Java程序设计>第二周学习总结 教材学习内容总结 了解Java编程风格 认识Java基本数据类型与数组 掌握Java运算符.表达式和语句 教材学习中的问题和解决过程 ...
- Django中media的配置
Django中media的配置 Django中media文件夹是我们文件(比如头像.文件.视频等)数据十分重要的存放处,这里以用户头像的上传以及media文件的访问为例为大家详细讲解下media的相关 ...
- python使用xlrd读取excel数据时,整数变小数的解决办法
python使用xlrd读取excel数据时,整数变小数: 解决方法: 1.有个比较简单的就是在数字和日期的单元格内容前加上一个英文的逗号即可.如果数据比较多,也可以批量加英文逗号的前缀(网上都有方法 ...
- LINUX 中实现逻辑卷、自动挂载
实验项目: 准备3块10G的空闲分区,将类型ID修改为8e(LVM) 使用其中2块分区组建名为myvg的卷组,查看此卷组信息 先检查有哪些物理卷 讲两块空闲分区转换成物理卷 再检查有哪些物理卷,查看其 ...
- mac无密登陆到linux
最近弄了台linux云服务器,然而每次登陆linux都好麻烦,所以倒腾了下ssh无密登陆. linux:centos 6.5,自带ssh mac:yosemite,自带ssh 步骤: 1. 创建key ...
- Creating adaptive web recommendation system based on user behavior(设计基于用户行为数据的适应性网络推荐系统)
文章介绍了一个基于用户行为数据的推荐系统的实现步骤和方法.系统的核心是专家系统,它会根据一定的策略计算所有物品的相关度,并且将相关度最高的物品序列推送给用户.计算相关度的策略分为两部分,第一部分是针对 ...