【Spark2.0源码学习】-8.SparkContext与Application介绍
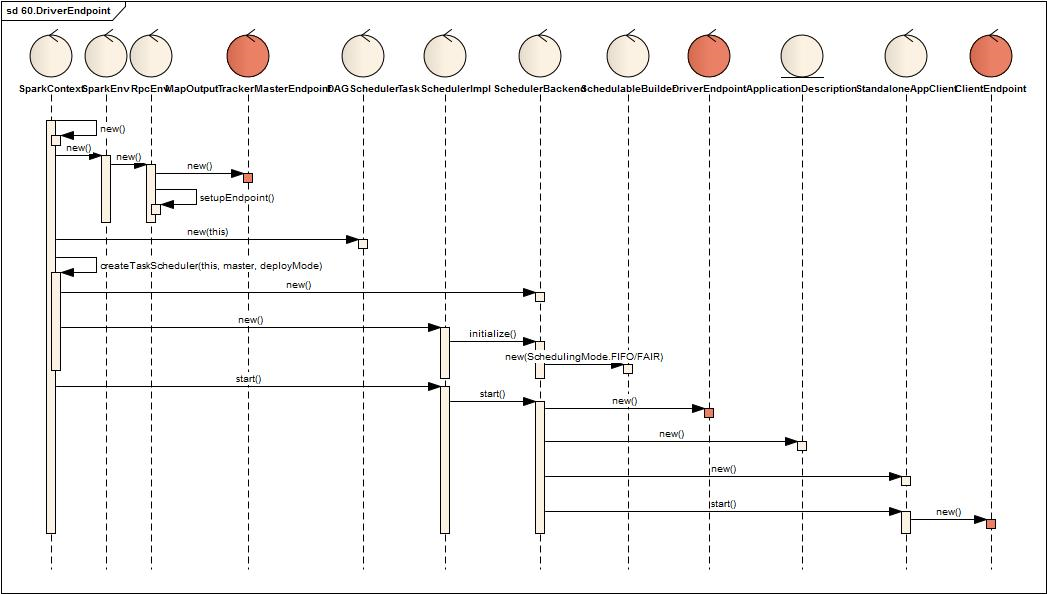

- 内部创建一个SparkEnv,SparkEnv内部创建一个RpcEnv
- RpcEnv内部创建并注册一个MapOutputTrackerMasterEndpoint(该Endpoint暂不介绍)
- 接着创建DAGScheduler,TaskSchedulerImpl,SchedulerBackend
- TaskSchedulerImpl创建时创建SchedulableBuilder,SchedulableBuilder根据类型分为FIFOSchedulableBuilder,FairSchedulableBuilder两类
- 最后启动TaskSchedulerImpl,TaskSchedulerImpl启动SchedulerBackend
- SchedulerBackend启动时创建ApplicationDescription,DriverEndpoint, StandloneAppClient
- StandloneAppClient内部包括一个ClientEndpoint
.png)
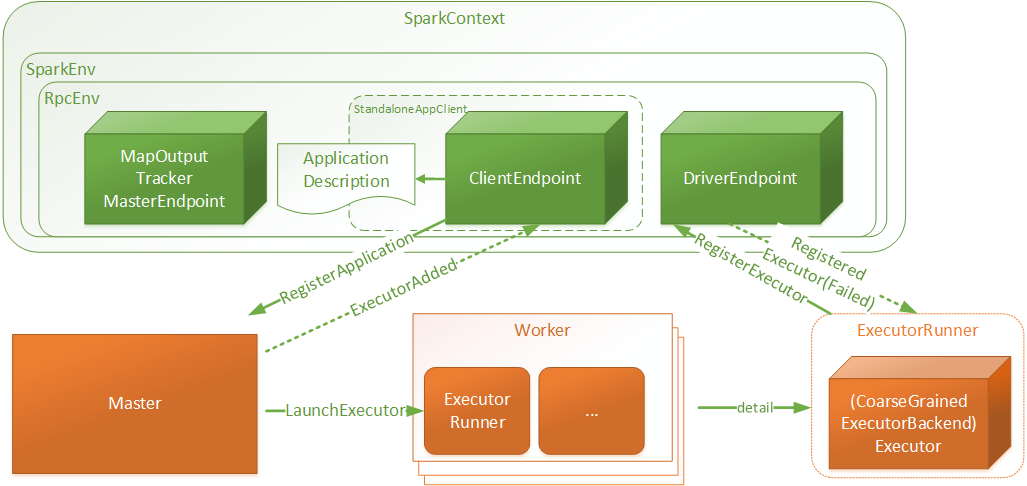
- SparkContext:是用户Spark执行任务的上下文,用户程序内部使用Spark提供的Api直接或间接创建一个SparkContext
- SparkEnv:用户执行的环境信息,包括通信相关的端点
- RpcEnv:SparkContext中远程通信环境
- ApplicationDescription:应用程序描述信息,主要包含appName, maxCores, memoryPerExecutorMB, coresPerExecutor, Command(
CoarseGrainedExecutorBackend), appUiUrl等 - ClientEndpoint:客户端端点,启动后向Master发起注册RegisterApplication请求
- Master:接受RegisterApplication请求后,进行Worker资源分配,并向分配的资源发起LaunchExecutor指令
- Worker:接受LaunchExecutor指令后,运行ExecutorRunner
- ExecutorRunner:运行applicationDescription的Command命令,最终Executor,同时向DriverEndpoint注册Executor信息
.png)

- 如果waitingApp配置了app.desc.coresPerExecutor:
- 轮询所有有效可分配的worker,每次分配一个executor,executor的核数为minCoresPerExecutor(app.desc.coresPerExecutor),直到不存在有效可分配资源或者app依赖的资源已全部被分配
- 如果waitingApp没有配置app.desc.coresPerExecutor:
- 轮询所有有效可分配的worker,每个worker分配一个executor,executor的核数为从minCoresPerExecutor(为固定值1)开始递增,直到不存在有效可分配资源或者app依赖的资源已全部被分配
- 其中有效可分配worker定义为满足一次资源分配的worker:
- cores满足:usableWorkers(pos).coresFree - assignedCores(pos) >= minCoresPerExecutor,
- memory满足(如果是新的Executor):usableWorkers(pos).memoryFree - assignedExecutors(pos) * memoryPerExecutor >= memoryPerExecutor
- 注意:Master针对于applicationInfo进行资源分配时,只有存在有效可用的资源就直接分配,而分配剩余的app.coresLeft则等下一次再进行分配


- 在Worker的tempDir下面创建application以及executor的目录,并chmod700操作权限
- 创建并启动ExecutorRunner进行Executor的创建
- 向master发送Executor的状态情况
- 新线程【ExecutorRunner for [executorId]】读取ApplicationDescription将其中Command转化为本地的Command命令
- 调用Command并将日志输出至executor目录下的stdout,stderr日志文件中,Command对应的java类为CoarseGrainedExecutorBackend
- 创建一个SparkEnv,创建ExecutorEndpoint(CoarseGrainedExecutorBackend),以及WorkerWatcher
- ExecutorEndpoint创建并启动后,向DriverEndpoint发送RegisterExecutor请求并等待返回
- DriverEndpoint处理RegisterExecutor请求,返回ExecutorEndpointRegister的结果
- 如果注册成功,ExecutorEndpoint内部再创建Executor的处理对象
【Spark2.0源码学习】-8.SparkContext与Application介绍的更多相关文章
- 【Spark2.0源码学习】-3.Endpoint模型介绍
Spark作为分布式计算框架,多个节点的设计与相互通信模式是其重要的组成部分. 一.组件概览 对源码分析,对于设计思路理解如下: RpcEndpoint: ...
- 【Spark2.0源码学习】-1.概述
Spark作为当前主流的分布式计算框架,其高效性.通用性.易用性使其得到广泛的关注,本系列博客不会介绍其原理.安装与使用相关知识,将会从源码角度进行深度分析,理解其背后的设计精髓,以便后续 ...
- spark2.0源码学习
[Spark2.0源码学习]-1.概述 [Spark2.0源码学习]-2.一切从脚本说起 [Spark2.0源码学习]-3.Endpoint模型介绍 [Spark2.0源码学习]-4.Master启动 ...
- 【Spark2.0源码学习】-2.一切从脚本说起
从脚本说起 在看源码之前,我们一般会看相关脚本了解其初始化信息以及Bootstrap类,Spark也不例外,而Spark我们启动三端使用的脚本如下: %SPARK_HOME%/sbin/st ...
- 【Spark2.0源码学习】-6.Client启动
Client作为Endpoint的具体实例,下面我们介绍一下Client启动以及OnStart指令后的额外工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/bin/jav ...
- 【Spark2.0源码学习】-4.Master启动
Master作为Endpoint的具体实例,下面我们介绍一下Master启动以及OnStart指令后的相关工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/ ...
- 【Spark2.0源码学习】-5.Worker启动
Worker作为Endpoint的具体实例,下面我们介绍一下Worker启动以及OnStart指令后的额外工作 一.脚本概览 下面是一个举例: /opt/jdk1..0_79/ ...
- 【Spark2.0源码学习】-9.Job提交与Task的拆分
在前面的章节Client的加载中,Spark的DriverRunner已开始执行用户任务类(比如:org.apache.spark.examples.SparkPi),下面我们开始针对于用 ...
- 【Spark2.0源码学习】-10.Task执行与回馈
通过上一节内容,DriverEndpoint最终生成多个可执行的TaskDescription对象,并向各个ExecutorEndpoint发送LaunchTask指令,本节内容将关注Exe ...
随机推荐
- 在内存中加载DLL
有个需求是把一个DLL作为数据打包到EXE中,运行的时候动态加载.但要求不是释放出来生成DLL文件加载. 花了一天时间做出来.效果还可以. 不过由于是直接分配内存加载DLL的.有一些小缺陷.例如遍历进 ...
- 第一天Python
一.开发语言 高级语言:Python Java.PHP 高级语言--字节码(PHP适用于写网页) 低级语言:C.汇编--机器码(底层开发,根本,效率低) 二.Python种类 三.安装
- 2013-7-30 802.1X企业级加密
今天做了U9510的企业级加密标杆测试,写了企业级加密标杆设备的操作指南.最后做到server 2003却出了问题,peap能关联,但是TLS怎么都关联不上.用adb shell查看logcat日志, ...
- Lock和synchronized的区别和使用
Java并发编程:Lock 今天看了并发实践这本书的ReentantLock这章,感觉对ReentantLock还是不够熟悉,有许多疑问,所有在网上找了很多文章看了一下,总体说的不够详细,重点和焦点问 ...
- PAT 甲级 1054 The Dominant Color (20 分)
1054 The Dominant Color (20 分) Behind the scenes in the computer's memory, color is always talked ab ...
- Spring Boot之执行器端点(Actuator Endpoint)实现剖析
整体实现思路是将端点(Endpoint)适配委托给MVC层策略端点(MvcEndpoint),再通过端点MVC适配器(EndpointMvcAdapter)将端点暴露为HTTP请求方式的MVC端点,最 ...
- [UE4]CheckBox
一.CheckBox默认情况下是比较小的 二.要让CheckBox变大,最简单的方法就是直接设置Transform.Scale,但如此一来CheckBox就变得模糊了. 三.CheckBox控件是在C ...
- GraphicsMagick命令
[ convert | identify | mogrify | composite | montage | compare | display | animate | import | conjur ...
- springmvc的简单使用以及ssm框架的整合
Spring web mvc是基于servlet的一个表现层框架 首先创建一个简单的web工程了解它的使用 web.xml的配置 <?xml version="1.0" en ...
- pyton unittest
在说unittest之前,先说几个概念: TestCase 也就是测试用例 TestSuite 多个测试用例集合在一起,就是TestSuite TestLoader是用来加载TestCase到Test ...