21天打造分布式爬虫-urllib库(一)
1.1.urlopen函数的用法
#encoding:utf-8
from urllib import request
res = request.urlopen("https://www.cnblogs.com/")
print(res.readlines())
#urlopen的参数
#def urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT,
# *, cafile=None, capath=None, cadefault=False, context=None):
1.2.urlretrieve函数
将网页上的文件保存到本地
#coding:utf-8
from urllib import request
res = request.urlretrieve("https://www.cnblogs.com/",'cnblog.html')
#urlretrieve参数
#def urlretrieve(url, filename=None, reporthook=None, data=None):
1.3.参数编码和解码函数
urlencode函数用于编码中文和特殊字符
#urlencode函数 # 简单用法
#from urllib import parse
# data = {'name':'德瑞克','age':100}
# qs = parse.urlencode(data)
# print(qs) #name=%E5%BE%B7%E7%91%9E%E5%85%8B&age=100 #实际用例
from urllib import request,parse
url = "http://www.baidu.com/s"
params = {"wd":"博客园"}
qs = parse.urlencode(params)
url = url + "?" + qs
res = request.urlopen(url)
print(res.read())
parse_qs函数用于将经过编码后的url参数进行解码。
from urllib import parse qs = "name=%E5%BE%B7%E7%91%9E%E5%85%8B&age=100"
print(parse.parse_qs(qs)) #{'name': ['德瑞克'], 'age': ['100']}
1.4.urlparse和urlsplit函数用法
urlparse和urlsplit都是用来对url的各个组成部分进行分割的,唯一不同的是urlsplit没有"params"这个属性.
from urllib import request,parse url = "https://www.baidu.com/s?wd=cnblog#2"
result = parse.urlparse(url)
print(result)
#ParseResult(scheme='https', netloc='www.baidu.com', path='/s', params='', query='wd=cnblog', fragment='2') print('scheme:',result.scheme) #协议
print('netloc:',result.netloc) #域名
print('path:',result.path) #路径
print('query:',result.query) #查询参数 #结果
#scheme: https
# netloc: www.baidu.com
# path: /s
# query: wd=cnblog
1.5.Request爬去拉勾网职位信息
Request类的参数
class Request:
def __init__(self, url, data=None, headers={},
origin_req_host=None, unverifiable=False,
method=None):
爬去拉钩网职位信息
拉勾网的职位信息是在Ajax.json里面
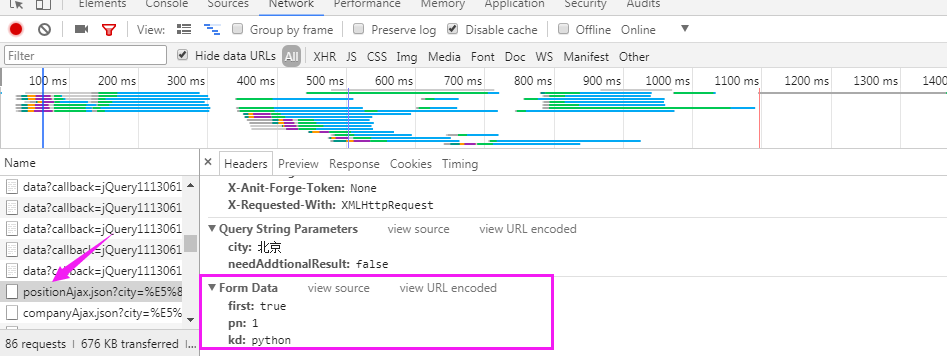
代码:
#利用Request类爬去拉勾网职位信息 from urllib import request,parse url = "https://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false" #请求头
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36",
"Referer":"https://www.lagou.com/jobs/list_python?city=%E5%8C%97%E4%BA%AC&cl=false&fromSearch=true&labelWords=&suginput="
}
#post请求需要提交的数据
data = {
'first':'true',
'pn':1,
'kd':'python'
}
#post请求的data数据必须是编码后的字节类型
req = request.Request(url,headers=headers,data=parse.urlencode(data).encode('utf-8'),method='POST') #建立一个请求对象
res = request.urlopen(req)
#获取的信息是字节类型,需要解码
print(res.read().decode('utf-8'))
1.6.ProxyHandler代理
代理原理:在请求目的网站之前,先请求代理服务器,然后让代理服务器去请求目的网站,获取到数据后,再返回给我们。
#代理的使用
from urllib import request url = "https://www.baidu.com/s?wd=cnblog" #1.使用ProxyHandler传入代理构建一个handler
# handler = request.ProxyHandler({'http':'115.210.31.236.55:9000'})
handler = request.ProxyHandler({'http':'115.210.31.236.55:9000'})
#2.使用创建的handler构建一个opener
opener = request.build_opener(handler)
#3.使用opener去发送一个请求
res = opener.open(url)
print(res.read())
21天打造分布式爬虫-urllib库(一)的更多相关文章
- 21天打造分布式爬虫-requests库(二)
2.1.get请求 简单使用 import requests response = requests.get("https://www.baidu.com/") #text返回的是 ...
- 21天打造分布式爬虫-Spider类爬取糗事百科(七)
7.1.糗事百科 安装 pip install pypiwin32 pip install Twisted-18.7.0-cp36-cp36m-win_amd64.whl pip install sc ...
- 21天打造分布式爬虫-Crawl类爬取小程序社区(八)
8.1.Crawl的用法实战 新建项目 scrapy startproject wxapp scrapy genspider -t crawl wxapp_spider "wxapp-uni ...
- 21天打造分布式爬虫-Selenium爬取拉钩职位信息(六)
6.1.爬取第一页的职位信息 第一页职位信息 from selenium import webdriver from lxml import etree import re import time c ...
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python爬虫Urllib库的基本使用
Python爬虫Urllib库的基本使用 深入理解urllib.urllib2及requests 请访问: http://www.mamicode.com/info-detail-1224080.h ...
- python爬虫 - Urllib库及cookie的使用
http://blog.csdn.net/pipisorry/article/details/47905781 lz提示一点,python3中urllib包括了py2中的urllib+urllib2. ...
- 对于python爬虫urllib库的一些理解(抽空更新)
urllib库是Python中一个最基本的网络请求库.可以模拟浏览器的行为,向指定的服务器发送一个请求,并可以保存服务器返回的数据. urlopen函数: 在Python3的urllib库中,所有和网 ...
- 一起学爬虫——urllib库常用方法用法总结
1.读取cookies import http.cookiejar as cj,urllib.request as request cookie = cj.CookieJar() handler = ...
随机推荐
- Linux Ipv6地址配置
Step1:启用IPV6网络配置 [root@node-1 ~]# vi /etc/sysconfig/network NETWORKING_IPV6=yes //全局启用ipv6初始化IPV6_ ...
- Newtonsoft.Json反序列化(Deserialize)出错:Bad JSON escape sequence
使用Newtonsoft.Json反序列化收到的字串为JObject或其它支持的数据模型,有时错误,提示如下: Bad JSON escape sequence: \c. Path , positio ...
- 516. Longest Palindromic Subsequence最长的不连续回文串的长度
[抄题]: Given a string s, find the longest palindromic subsequence's length in s. You may assume that ...
- 将Promise融会贯通之路
前端初学者经常会问,我如何在ajax1结束之后才启动ajax2呢?我怎么做才能在所有的ajax结束之后触发某程序呢?亦或是哎真是烦,5个ajax套在一起,原来的逻辑是什么呀! 一个稍微有点经验的前端程 ...
- 拜托!面试请不要再问我Spring Cloud底层原理[z]
[z]https://juejin.im/post/5be13b83f265da6116393fc7 拜托!面试请不要再问我Spring Cloud底层原理 欢迎关注微信公众号:石杉的架构笔记(id: ...
- mysql 数据库设计
数据库设计 需求分析 *1.用户模块 用于记录记录注册用户信息 包括属性:用户名,密码,电话,邮箱,身份证号,地址,姓名,昵称... 可选唯一标志属性:用户名,电话,身份证号 存储特点:随系统上线时间 ...
- ubuntu,day1基础命令,shutdown,man,touch,rm,mv,cp,stat,locale,apt,date,tzselect,cal,快捷方式,echo,查看文件
基本设置命令 1,shutdown 命令, shutdown -r now # 现在立即重启 shutdown -r + # 三分钟后重启 shutdown -r : #在12:12时将重启计算机 s ...
- ssh 配置免密失败
多数情况下,可以登录成功.但是也会出现配置不正确,导致失败的时候. 1.检查authorized_keys文件权限,并设置为700 chmod 700 authorized_keys 2.检查/etc ...
- Codeforces Round #536 (Div. 2) E dp + set
https://codeforces.com/contest/1106/problem/E 题意 一共有k个红包,每个红包在\([s_i,t_i]\)时间可以领取,假如领取了第i个红包,那么在\(d_ ...
- s11 Docker+DevOps实战--过程和工具
开发人员本地提交代码,本地使用容器模拟生产环境测试,测试通过提交到git master 分支,就会触发pipeline执行集成构建.集成工具: gitlab-vi,travis,或Jenkins.自动 ...