机器学习与Tensorflow(7)——tf.train.Saver()、inception-v3的应用
1. tf.train.Saver()
- tf.train.Saver()是一个类,提供了变量、模型(也称图Graph)的保存和恢复模型方法。
- TensorFlow是通过构造Graph的方式进行深度学习,任何操作(如卷积、池化等)都需要operator,保存和恢复操作也不例外。
- 在tf.train.Saver()类初始化时,用于保存和恢复的save和restore operator会被加入Graph。所以,下列类初始化操作应在搭建Graph时完成。
saver = tf.train.Saver()
TensorFlow的保存和恢复分为两种:
- 保存和恢复变量
- 保存和恢复模型
saver.save()保存模型
#举例:
保存一个训练好的手写数据集识别模型
保存在当前路径的net文件夹中
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = ''
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data #载入数据集
mnist = input_data.read_data_sets('MNIST_data', one_hot=True) #每个批次100张照片
batch_size = 100
#计算一个需要多少个批次
n_batch = mnist.train.num_examples // batch_size #定义两个placeholder
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10]) #创建一个简单的神经网络,输入层784个神经元,输出层10个神经元
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
prediction = tf.nn.softmax(tf.matmul(x, W) + b)
#代价函数
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
#使用梯度下降法
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss) #初始化变量
init = tf.global_variables_initializer() #结果存放在一个布尔型列表中
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) saver = tf.train.Saver() with tf.Session() as sess:
sess.run(init)
for epoch in range(11):
for batch in range(n_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step, feed_dict={x:batch_xs, y:batch_ys})
acc = sess.run(accuracy, feed_dict={x:mnist.test.images, y:mnist.test.labels})
print('Iter = ' + str(epoch) +', Testing Accuracy = ' + str(acc))
#保存模型
saver.save(sess, 'net/my_net.ckpt')
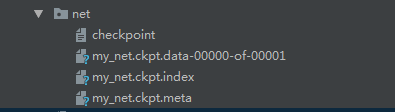
#保存路径中的文件为:
checkpoint:保存当前网络状态的文件
my_net.ckpt.data-00000-of-00001
my_net.ckpt.index
my_net.ckpt.meta:保存Graph结构的文件
#关于函数saver.save(),常用的参数就是前三个:
save(
sess, # 必需参数,Session对象
save_path, # 必需参数,存储路径
global_step=None, # 可以是Tensor, Tensor name, 整型数
latest_filename=None, # 协议缓冲文件名,默认为'checkpoint',不用管
meta_graph_suffix='meta', # 图文件的后缀,默认为'.meta',不用管
write_meta_graph=True, # 是否保存Graph
write_state=True, # 建议选择默认值True
strip_default_attrs=False # 是否跳过具有默认值的节点
saver.restore()加载已经训练好的模型
#举例:
通过加载刚才保存的训练好的手写数据集识别模型进行手写数据集的识别
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = ''
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
batch_size = 100
n_batch = mnist.train.num_examples // batch_size x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10]) W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
prediction = tf.nn.softmax(tf.matmul(x, W) + b) loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss) init = tf.global_variables_initializer() correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) saver = tf.train.Saver() with tf.Session() as sess:
sess.run(init)
print(sess.run(accuracy, feed_dict={x:mnist.test.images, y:mnist.test.labels}))
saver.restore(sess, 'net/my_net.ckpt')
print(sess.run(accuracy, feed_dict={x:mnist.test.images, y:mnist.test.labels}))
#执行结果: 0.098
0.9178 #直接得到的准确率相当低,通过加载训练好的模型,识别准确率大大提升。
2. 下载google图像识别网络inception-v3并查看结构
模型背景:
Inception(v3) 模型是Google 训练好的最新一个图像识别模型,我们可以利用它来对我们的图像进行识别。
下载地址:
https://storage.googleapis.com/download.tensorflow.org/models/inception_dec_2015.zip
文件描述:
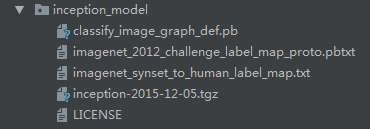
- classify_image_graph_def.pb 文件就是训练好的Inception-v3模型。
- imagenet_synset_to_human_label_map.txt是类别文件,包含人类标签和uid之间的映射的文件。
- imagenet_2012_challenge_label_map_proto.pbtxt是包含类号和uid之间的映射的文件。
代码实现
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = ''
import tensorflow as tf
import tarfile
import requests #inception模型下载地址
inception_pretrain_model_url = 'http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz' #inception模型存放地址
inception_pretrain_model_dir = 'inception_model'
if not os.path.exists(inception_pretrain_model_dir):
os.makedirs(inception_pretrain_model_dir)
#获取文件名,以及文件路径
filename = inception_pretrain_model_url.split('/')[-1]
filepath = os.path.join(inception_pretrain_model_dir, filename) #下载模型
if not os.path.exists(filepath):
print('download: ', filename)
r = requests.get(inception_pretrain_model_url, stream=True)
with open(filepath, 'wb') as f:
for chunk in r.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
print('finish: ', filename)
#解压文件
tarfile.open(filepath, 'r:gz').extractall(inception_pretrain_model_dir) #模型结构存放文件
log_dir = 'inception_log'
if not os.path.exists(log_dir):
os.makedirs(log_dir) #classify_image_graph_def.pb为google训练好的模型
inception_graph_def_file = os.path.join(inception_pretrain_model_dir, 'classify_image_graph_def.pb')
with tf.Session() as sess:
#创建一个图来存放google训练好的模型
with tf.gfile.FastGFile(inception_graph_def_file, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name='')
#保存图的结构
writer = tf.summary.FileWriter(log_dir, sess.graph)
writer.close()
#在下载过程中,下的特别慢,不知道是网络原因还是什么
#程序总卡着不动
#所以我就手动下载压缩包并进行解压
下载结果
3. 使用inception-v3做各种图像的识别
#代码实现:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = ''
import tensorflow as tf
import numpy as np
import re
from PIL import Image
import matplotlib.pyplot as plt #这部分是对标签号和类别号文件进行一个预处理 class NodeLookup(object):
def __init__(self):
label_lookup_path = 'inception_model/imagenet_2012_challenge_label_map_proto.pbtxt'
uid_lookup_path = 'inception_model/imagenet_synset_to_human_label_map.txt'
self.node_lookup = self.load(label_lookup_path, uid_lookup_path)
def load(self, label_lookup_path, uid_lookup_path):
#加载分类字符串n********对应分类名称的文件
proto_as_ascii_lines = tf.gfile.GFile(uid_lookup_path).readlines()
uid_to_human={}
#一行一行读取数据
for line in proto_as_ascii_lines:
#去掉换行符
line = line.strip('\n')
#按照‘\t’进行分割
parsed_items = line.split('\t')
#获取分类编号
uid = parsed_items[0]
#获取分类名称
human_string = parsed_items[1]
#保存编号字符串n********与分类名称的映射关系
uid_to_human[uid] = human_string #加载分类字符串n********对应分类编号1-1000的文件
proto_as_ascii = tf.gfile.GFile(label_lookup_path).readlines()
node_id_to_uid = {}
for line in proto_as_ascii:
if line.startswith(' target_class:'):
#获取分类编号1-1000
target_class = int(line.split(': ')[1])
if line.startswith(' target_class_string:'):
#获取编号字符串nn********
target_class_string = line.split(': ')[1]
# 保存分类编号1-1000与编号字符串n********映射关系
node_id_to_uid[target_class] = target_class_string[1:-2]
# 建立分类编号1-1000对应分类名称的映射关系
node_id_to_name = {}
for key, val in node_id_to_uid.items():
#获取分类名称
name = uid_to_human[val]
# 建立分类编号1-1000到分类名称的映射关系
node_id_to_name[key] = name
return node_id_to_name
# 传入分类编号1-1000返回分类名称
def id_to_string(self, node_id):
if node_id not in self.node_lookup:
return ''
return self.node_lookup[node_id] #创建一个图来存放google训练好的模型 with tf.gfile.FastGFile('inception_model/classify_image_graph_def.pb', 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name='') with tf.Session() as sess:
softmax_tensor = sess.graph.get_tensor_by_name('softmax:0')
#遍历目录
for root, dirs, files in os.walk('images/'):
for file in files:
#载入图片
image_data = tf.gfile.FastGFile(os.path.join(root, file), 'rb').read()
predictions = sess.run(softmax_tensor, {'DecodeJpeg/contents:0': image_data})#图片格式是jpg格式
predictions = np.squeeze(predictions)#把结果转为1维数据 #打印图片路径及名称
image_path = os.path.join(root, file)
print(image_path) # 显示图片
img = Image.open(image_path)
plt.imshow(img)
plt.axis('off')
plt.show() #排序
top_k = predictions.argsort()[-5:][::-1]
node_lookup = NodeLookup()
for node_id in top_k:
# 获取分类名称
human_string = node_lookup.id_to_string(node_id)
# 获取该分类的置信度
score = predictions[node_id]
print('%s(score = %.5f)' % (human_string, score))
print()
#执行结果:
images/1.jpg
giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca(score = 0.87265)
badger(score = 0.00260)
lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens(score = 0.00205)
brown bear, bruin, Ursus arctos(score = 0.00102)
ice bear, polar bear, Ursus Maritimus, Thalarctos maritimus(score = 0.00099) images/2.jpg
French bulldog(score = 0.94474)
bull mastiff(score = 0.00559)
pug, pug-dog(score = 0.00352)
Staffordshire bullterrier, Staffordshire bull terrier(score = 0.00165)
boxer(score = 0.00116) images/3.jpg
zebra(score = 0.94011)
tiger, Panthera tigris(score = 0.00080)
pencil box, pencil case(score = 0.00066)
hartebeest(score = 0.00059)
tiger cat(score = 0.00042) images/4.jpg
hare(score = 0.87019)
wood rabbit, cottontail, cottontail rabbit(score = 0.04802)
Angora, Angora rabbit(score = 0.00612)
wallaby, brush kangaroo(score = 0.00181)
fox squirrel, eastern fox squirrel, Sciurus niger(score = 0.00056) images/5.jpg
fox squirrel, eastern fox squirrel, Sciurus niger(score = 0.95047)
marmot(score = 0.00265)
mongoose(score = 0.00217)
weasel(score = 0.00201)
mink(score = 0.00199)

机器学习与Tensorflow(7)——tf.train.Saver()、inception-v3的应用的更多相关文章
- TensorFlow:tf.train.Saver()模型保存与恢复
1.保存 将训练好的模型参数保存起来,以便以后进行验证或测试.tf里面提供模型保存的是tf.train.Saver()模块. 模型保存,先要创建一个Saver对象:如 saver=tf.train.S ...
- tensorflow的tf.train.Saver()模型保存与恢复
将训练好的模型参数保存起来,以便以后进行验证或测试.tf里面提供模型保存的是tf.train.Saver()模块. 模型保存,先要创建一个Saver对象:如 saver=tf.train.Saver( ...
- 图融合之加载子图:Tensorflow.contrib.slim与tf.train.Saver之坑
import tensorflow as tf import tensorflow.contrib.slim as slim import rawpy import numpy as np impor ...
- TensorFlow Saver 保存最佳模型 tf.train.Saver Save Best Model
TensorFlow Saver 保存最佳模型 tf.train.Saver Save Best Model Checkmate is designed to be a simple drop-i ...
- 跟我学算法- tensorflow模型的保存与读取 tf.train.Saver()
save = tf.train.Saver() 通过save. save() 实现数据的加载 通过save.restore() 实现数据的导出 第一步: 数据的载入 import tensorflo ...
- tf.train.Saver()
1. 实例化对象 saver = tf.train.Saver(max_to_keep=1) max_to_keep: 表明保存的最大checkpoint文件数.当一个新文件创建的时候,旧文件就会被删 ...
- tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数(转)
tensorflow数据读取机制 tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数 ...
- tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数
tensorflow数据读取机制 tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数 ...
- 【转载】 tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数
原文地址: https://blog.csdn.net/dcrmg/article/details/79776876 ----------------------------------------- ...
随机推荐
- 云笔记项目-Spring事务学习_测试准备
在做云笔记项目的过程中,顺便简单的学习了Spring的事务概念,业务以如果添加笔记,则增加用户星星数目作为例子,引入了事务的概念.类似注册送积分之类的,云笔记项目以增加笔记就送星星来说明事务.具体在添 ...
- 在ASP.NET MVC中使用UEditor无法提交的解决办法
很简单的一个ajax提交,却怎么都不成功 $.ajax({ type: "POST", url: "/mms/riskmanage/commitreply", ...
- Quartz使用
背景 很多时候,项目需要在不同时刻,执行一个或很多个不同的作业. Windows执行计划这时并不能很好的满足需求了,迫切需要一个更为强大,方便管理,集群部署的作业调度框架. 介绍 Quartz一个开源 ...
- Python设计模式 - UML - 包图(Package Diagram)
简介 包图是对各个包及包之间关系的描述,展现系统中模块与模块之间的依赖关系.一个包图可以由任何一种UML图组成,可容纳的元素有类.接口.组件.用例和其他包等.包是UML中非常常用的元素,主要作用是分类 ...
- TypeError: while_loop() got an unexpected keyword argument 'maximum_iterations'
错误: TypeError: while_loop() got an unexpected keyword argument 'maximum_iterations' 参照https://blog.c ...
- Lozad.js 简单使用
GayHub位置:https://github.com/ApoorvSaxena/lozad.js 导入: <script type="text/javascript" sr ...
- FortiGate上架前准备
1.收集信息 1.网络拓扑信息(了解网络拓扑信息有助于网络方案的规划) 2.环境信息(了解部署位置.部署模式.最大吞吐.最大用户数有助于对设备性能的评估) 3.客户需求,对FortiGate部署的功能 ...
- .net C# 利用Session防重复点击防重复提交
<body> <form id="form1" runat="server"> <div> < ...
- JS-基础动画心得
写在前面的话:这两种动画方式主要在于对其中算法的理解,理解其中的向上和向下取整很关键.还有一个我犯的毛病,写样式的时候忘记给轮播图ul定位,导致效果出不来,所以有bug时记得排除下css 常用的三种动 ...
- linux学习第十二天 (Linux就该这么学)找到一本不错的Linux电子书,附《Linux就该这么学》章节目录
本书是由全国多名红帽架构师(RHCA)基于最新Linux系统共同编写的高质量Linux技术自学教程,极其适合用于Linux技术入门教程或讲课辅助教材,目前是国内最值得去读的Linux教材,也是最有价值 ...