【慕课网实战】Spark Streaming实时流处理项目实战笔记十五之铭文升级版
铭文一级:[木有笔记]
铭文二级:
第12章 Spark Streaming项目实战
行为日志分析:
1.访问量的统计
2.网站黏性
3.推荐
Python实时产生数据
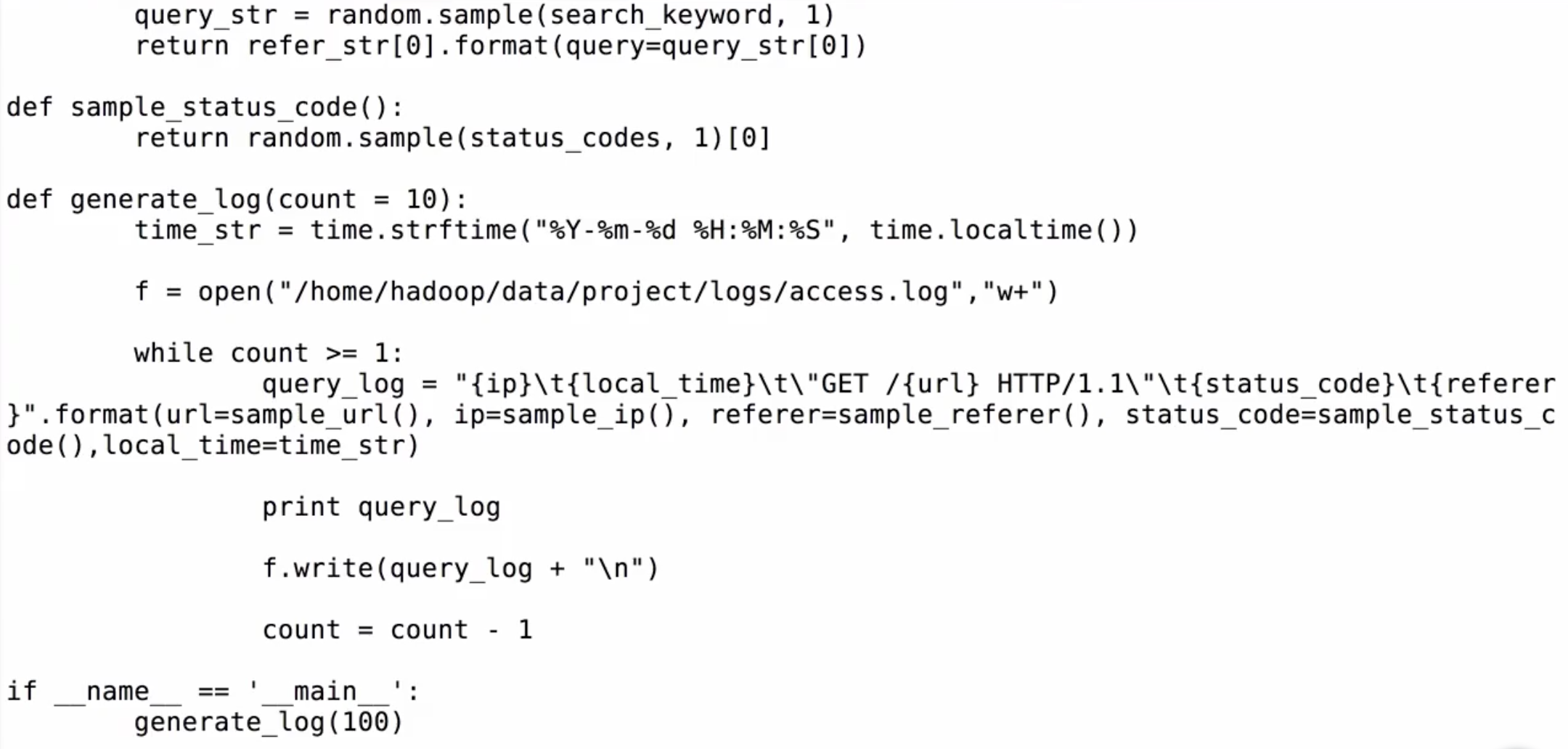
访问URL->IP信息->referer和状态码->日志访问时间->写入到文件中
本地与虚拟机都要装了python才能运行
重要代码:
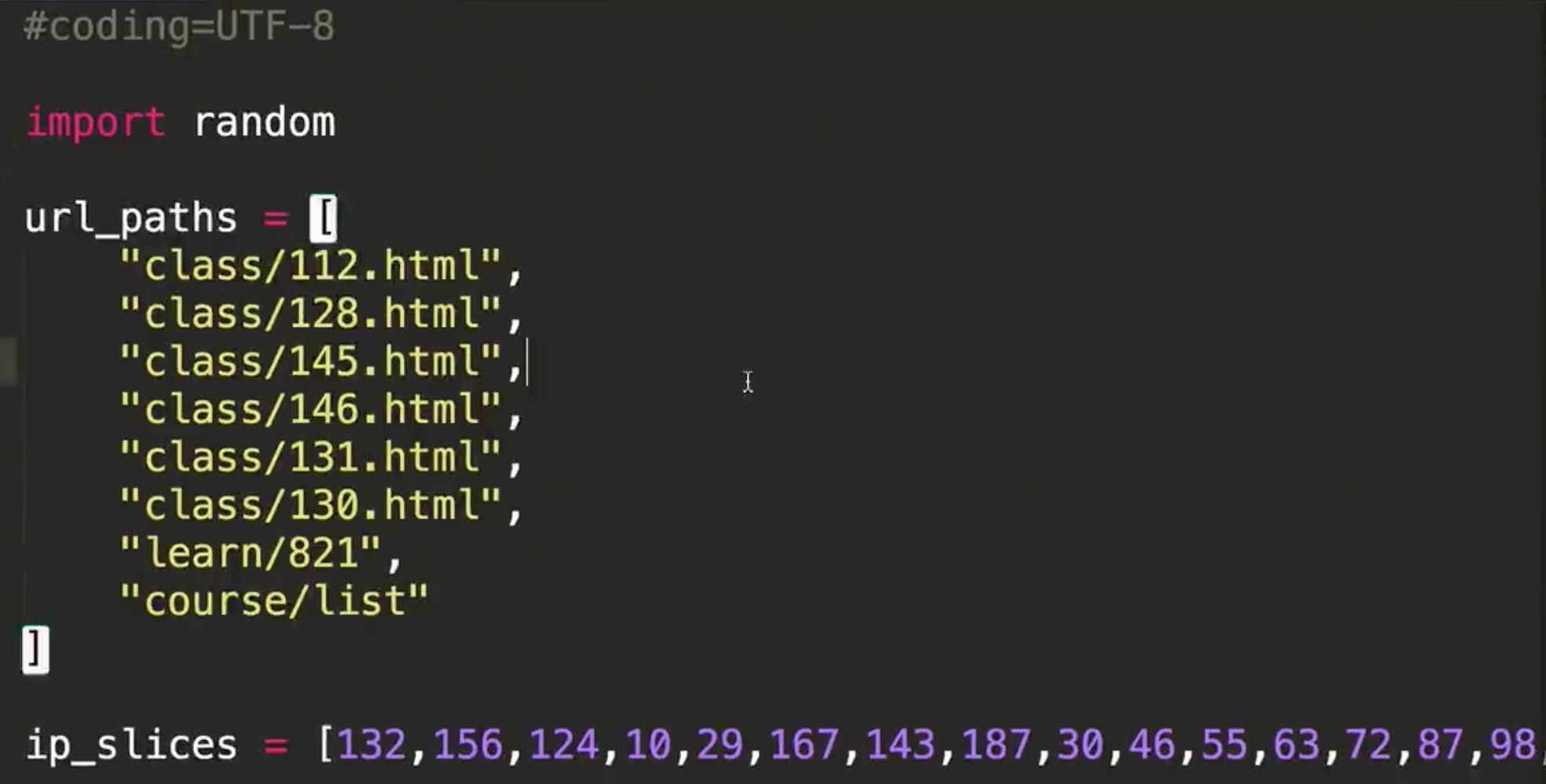
#coding=UTF-8
#数组最后一个没有“,”
url_paths = [
"class/128.html",
"class/112.html",
"class/143.html",
"class/141.html",
"learn/821",
"course/list"
]#增强for循环
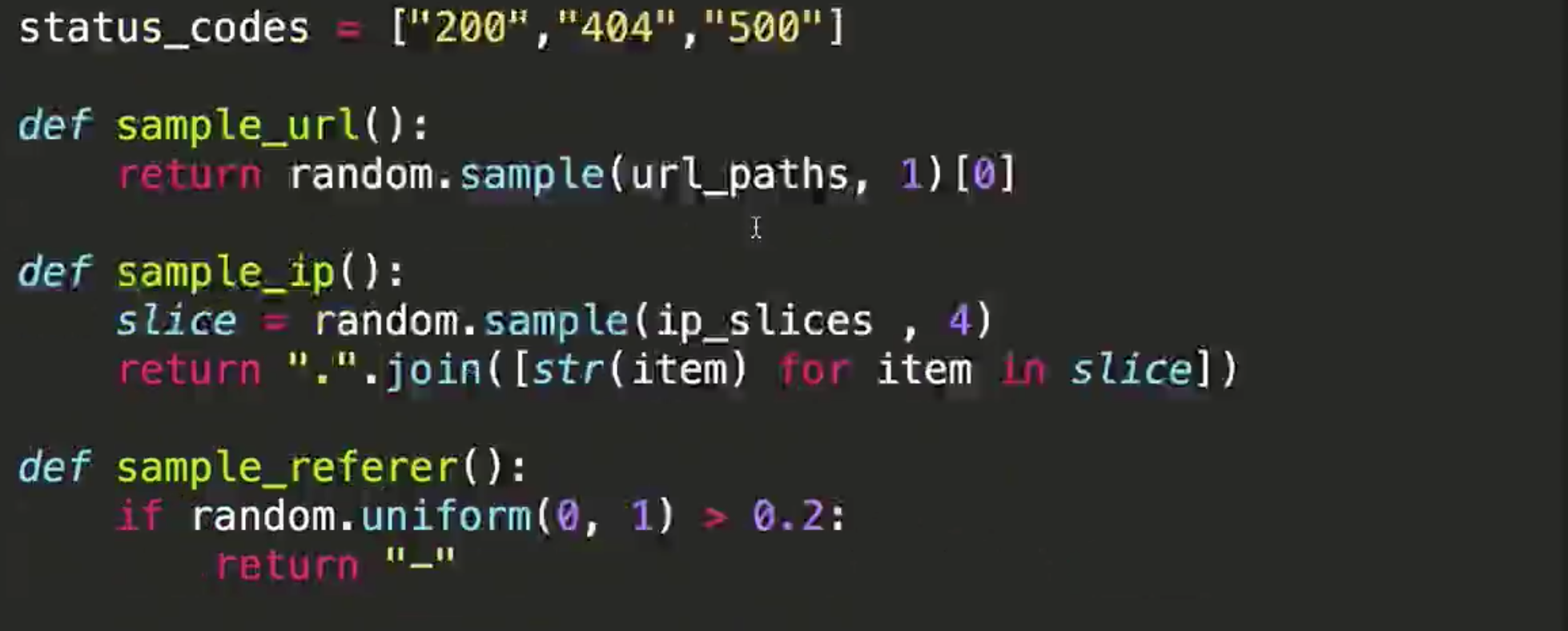
#sample(seq, n) 从序列seq中选择n个随机且独立的元素;
return ".".join([str(item) for item in slice])
def sample_url()
return random.sample(url_paths,1)[0]
query_log = "{url}".format(url=sample_url())
if __name__ == '__main__':
main()
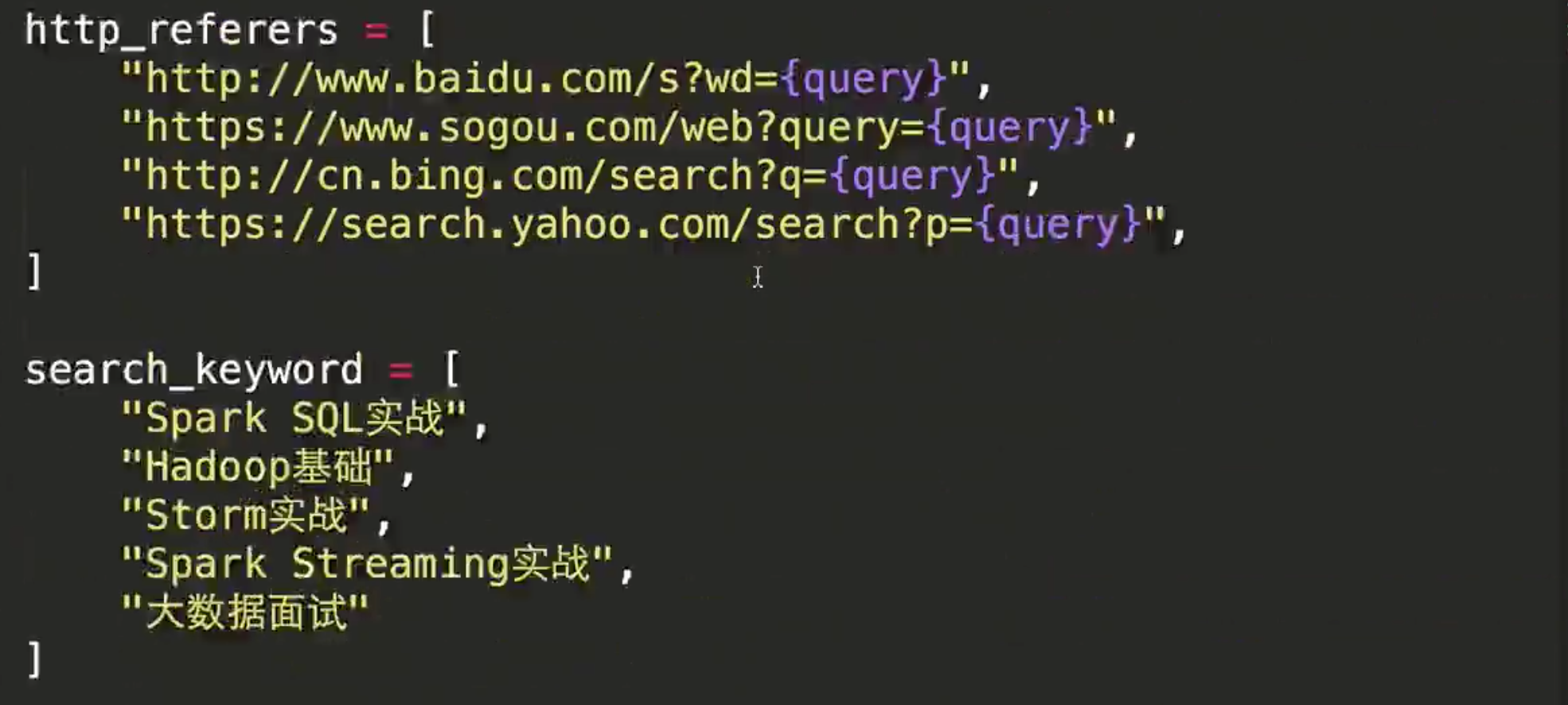
http_referers =[
"http://www.baidu.com/s?wd={query}",
"http://www.sogou.com/web?query={query}",
"http://cn.bing.com/search?q={query}",
"http://search.yahoo.com/search?p={query}"
]
time_str = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
前面要:
import time
import random
将文件输出到一个文件:
f = open("/home/hadoop/data/project/logs/access.log","w+")
f.write(query_log + "\n")
上部分参考代码:
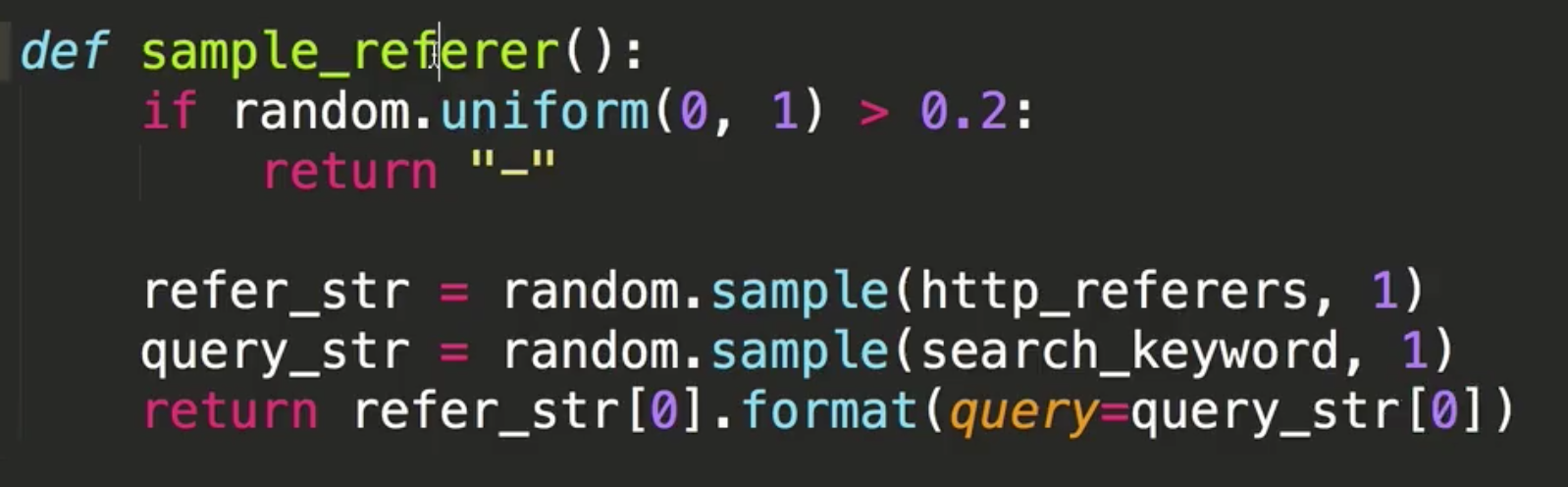
 貌似多了个逗号!!!
貌似多了个逗号!!!
下部分参考代码:
refer_str = random.sample(http_referers, 1)
代码编辑完后,需要先创建一个logs文件夹
然后执行py文件,到logs文件夹可查看到产生的数据
查看多少条信息指令:wc -l access.log
动态添加:tail -200f access.log //然后再执行一次
铭文三级:
一张图让你学会Python基础语法(看不清可另存为):
http://blog.csdn.net/qq_30845505/article/details/51588423
python编程中的if __name__ == 'main': 的作用和原理
http://www.dengfeilong.com/post/60.html
str() 函数将对象转化为适于人阅读的形式
>>>s = 'RUNOOB'
>>> str(s)
'RUNOOB'
>>> dict = {'runoob': 'runoob.com', 'google': 'google.com'};
>>> str(dict)
"{'google': 'google.com', 'runoob': 'runoob.com'}"
>>>
但此处 ([str(item) for item in slice])意思是将数字数组转为字符数组
uniform() 方法将随机生成下一个实数,它在 [x, y) 范围内。
format函数的使用
age = 25
name = 'Caroline'
print('{0} is {1} years old. '.format(name, age)) #输出参数
print('{0} is a girl. '.format(name))
print('{0:.3} is a decimal. '.format(1/3)) #小数点后三位
print('{0:_^11} is a 11 length. '.format(name)) #使用_补齐空位
print('{first} is as {second}. '.format(first=name, second='Wendy')) #别名替换
print('My name is {0.name}'.format(open('out.txt', 'w'))) #调用方法
print('My name is {0:8}.'.format('Fred')) #指定宽度
输出:
【慕课网实战】Spark Streaming实时流处理项目实战笔记十五之铭文升级版的更多相关文章
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十之铭文升级版
铭文一级: 第八章:Spark Streaming进阶与案例实战 updateStateByKey算子需求:统计到目前为止累积出现的单词的个数(需要保持住以前的状态) java.lang.Illega ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十四之铭文升级版
铭文一级: 第11章 Spark Streaming整合Flume&Kafka打造通用流处理基础 streaming.conf agent1.sources=avro-sourceagent1 ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记二之铭文升级版
铭文一级: 第二章:初识实时流处理 需求:统计主站每个(指定)课程访问的客户端.地域信息分布 地域:ip转换 Spark SQL项目实战 客户端:useragent获取 Hadoop基础课程 ==&g ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十六之铭文升级版
铭文一级: linux crontab 网站:http://tool.lu/crontab 每一分钟执行一次的crontab表达式: */1 * * * * crontab -e */1 * * * ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十二之铭文升级版
铭文一级: ======Pull方式整合 Flume Agent的编写: flume_pull_streaming.conf simple-agent.sources = netcat-sources ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十一之铭文升级版
铭文一级: 第8章 Spark Streaming进阶与案例实战 黑名单过滤 访问日志 ==> DStream20180808,zs20180808,ls20180808,ww ==> ( ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记九之铭文升级版
铭文一级: 核心概念:StreamingContext def this(sparkContext: SparkContext, batchDuration: Duration) = { this(s ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记八之铭文升级版
铭文一级: Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记七之铭文升级版
铭文一级: 第五章:实战环境搭建 Spark源码编译命令:./dev/make-distribution.sh \--name 2.6.0-cdh5.7.0 \--tgz \-Pyarn -Phado ...
随机推荐
- Flask与WSGI
刚开始接触到python及Flask框架时,总是会听到 wsgi等等相关的名词,以及 项目部署时会用到nginx+gunicorn等等,但是对于一个请求从 nignx到gunicorn再到falsk框 ...
- JS stringObject.Match()
JavaScript match() 方法 JavaScript String 对象 定义和用法 match() 方法可在字符串内检索指定的值,或找到一个或多个正则表达式的匹配. 该方法类似 inde ...
- shell数组的使用
定义: array=(1 2 3) echo ${array[0]} echo ${array[1]} echo ${array[2]} echo ${array[*]} 所有元素 echo $ ...
- springboot2系列目录
参考:https://blog.csdn.net/cowbin2012/article/details/85254990 带源码
- Django 部署(Nginx+uwsgi)
使用 uwsgi 来部署 安装 uwsgi sudo pip install uwsgi --upgrade 使用 uwsgi 运行项目 uwsgi --http :8001 --chdir /pat ...
- win10 KMS命令激活步骤<转>
三.win10 KMS命令激活步骤如下: 1.右键点击开始图标,弹出这个菜单,选择[windows powershell(管理员)],或者命令提示符管理员: 2.打开命令窗口,复制这个命令slmgr ...
- JS StartMove源码-简单运动框架
这几天学习js运动应用课程时,开始接触一个小例子:“仿Flash的图片轮换播放器”,其中使用的StartMove简单运动框架我觉得挺好用的.这个源码也简单,理解其原理,自己敲即便也就熟悉了. 用的时候 ...
- 1、detail页面 /items/detail/:id
<template> <div class="item_detail"> <van-swipe :autoplay="3000" ...
- python入门 -- 学习笔记2
习题11:提问 -- 接受键盘的输入 raw_input input() 和 raw_input() 有何不同? input() 函数会把你输入的东西当做 Python 代码进行处理,这么做会有安 ...
- svg旋转动画
<!doctype html><html><head> <title>test</title> <meta charset=" ...