57、Spark Streaming: window滑动窗口以及热点搜索词滑动统计案例
一、window滑动窗口
1、概述
Spark Streaming提供了滑动窗口操作的支持,从而让我们可以对一个滑动窗口内的数据执行计算操作。每次掉落在窗口内的RDD的数据,
会被聚合起来执行计算操作,然后生成的RDD,会作为window DStream的一个RDD。比如下图中,就是对每三秒钟的数据执行一次滑动窗口计算,
这3秒内的3个RDD会被聚合起来进行处理,然后过了两秒钟,又会对最近三秒内的数据执行滑动窗口计算。所以每个滑动窗口操作,都必须指定
两个参数,窗口长度以及滑动间隔,而且这两个参数值都必须是batch间隔的整数倍。(Spark Streaming对滑动窗口的支持,是比Storm更加完善和强大的)
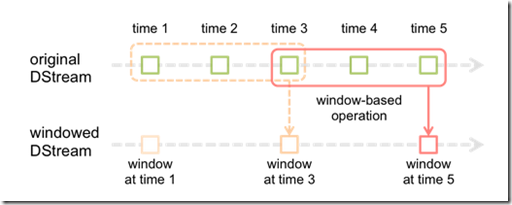
2、window滑动窗口操作

案例:热点搜索词滑动统计,每隔10秒钟,统计最近60秒钟的搜索词的搜索频次,并打印出排名最靠前的3个搜索词以及出现次数
2、java案例
package cn.spark.study.streaming; import java.util.List; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext; import scala.Tuple2; /**
* 基于滑动窗口的热点搜索词实时统计
* @author Administrator
*
*/
public class WindowHotWord { public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setMaster("local[2]")
.setAppName("WindowHotWord");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1)); // 说明一下,这里的搜索日志的格式
// leo hello
// tom world
JavaReceiverInputDStream<String> searchLogsDStream = jssc.socketTextStream("spark1", 9999); // 将搜索日志给转换成,只有一个搜索词,即可
JavaDStream<String> searchWordsDStream = searchLogsDStream.map(new Function<String, String>() { private static final long serialVersionUID = 1L; @Override
public String call(String searchLog) throws Exception {
return searchLog.split(" ")[1];
} }); // 将搜索词映射为(searchWord, 1)的tuple格式
JavaPairDStream<String, Integer> searchWordPairDStream = searchWordsDStream.mapToPair( new PairFunction<String, String, Integer>() { private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(String searchWord)
throws Exception {
return new Tuple2<String, Integer>(searchWord, 1);
} }); // 针对(searchWord, 1)的tuple格式的DStream,执行reduceByKeyAndWindow,滑动窗口操作
// 第二个参数,是窗口长度,这里是60秒
// 第三个参数,是滑动间隔,这里是10秒
// 也就是说,每隔10秒钟,将最近60秒的数据,作为一个窗口,进行内部的RDD的聚合,然后统一对一个RDD进行后续
// 计算
// 所以说,这里的意思,就是,之前的searchWordPairDStream为止,其实,都是不会立即进行计算的
// 而是只是放在那里
// 然后,等待我们的滑动间隔到了以后,10秒钟到了,会将之前60秒的RDD,因为一个batch间隔是,5秒,所以之前
// 60秒,就有12个RDD,给聚合起来,然后,统一执行redcueByKey操作
// 所以这里的reduceByKeyAndWindow,是针对每个窗口执行计算的,而不是针对某个DStream中的RDD
JavaPairDStream<String, Integer> searchWordCountsDStream =
//Function2<T1, T2, R>:一个双参数函数,它接受类型为T1和T2的参数并返回一个R
searchWordPairDStream.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>() { private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
} }, Durations.seconds(60), Durations.seconds(10)); // 到这里为止,就已经可以做到,每隔10秒钟,出来,之前60秒的收集到的单词的统计次数
// 执行transform操作,因为,一个窗口,就是一个60秒钟的数据,会变成一个RDD,然后,对这一个RDD
// 根据每个搜索词出现的频率进行排序,然后获取排名前3的热点搜索词
JavaPairDStream<String, Integer> finalDStream = searchWordCountsDStream.transformToPair( new Function<JavaPairRDD<String,Integer>, JavaPairRDD<String,Integer>>() { private static final long serialVersionUID = 1L; @Override
public JavaPairRDD<String, Integer> call(
JavaPairRDD<String, Integer> searchWordCountsRDD) throws Exception {
// 执行搜索词和出现频率的反转
JavaPairRDD<Integer, String> countSearchWordsRDD = searchWordCountsRDD
.mapToPair(new PairFunction<Tuple2<String,Integer>, Integer, String>() { private static final long serialVersionUID = 1L; @Override
public Tuple2<Integer, String> call(
Tuple2<String, Integer> tuple)
throws Exception {
return new Tuple2<Integer, String>(tuple._2, tuple._1);
}
}); // 然后执行降序排序
JavaPairRDD<Integer, String> sortedCountSearchWordsRDD = countSearchWordsRDD
.sortByKey(false); // 然后再次执行反转,变成(searchWord, count)的这种格式
JavaPairRDD<String, Integer> sortedSearchWordCountsRDD = sortedCountSearchWordsRDD
.mapToPair(new PairFunction<Tuple2<Integer,String>, String, Integer>() { private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(
Tuple2<Integer, String> tuple)
throws Exception {
return new Tuple2<String, Integer>(tuple._2, tuple._1);
} }); // 然后用take(),获取排名前3的热点搜索词
List<Tuple2<String, Integer>> hogSearchWordCounts =
sortedSearchWordCountsRDD.take(3);
for(Tuple2<String, Integer> wordCount : hogSearchWordCounts) {
System.out.println(wordCount._1 + ": " + wordCount._2);
} return searchWordCountsRDD;
} }); // 这个无关紧要,只是为了触发job的执行,所以必须有output操作
finalDStream.print(); jssc.start();
jssc.awaitTermination();
jssc.close();
} } ##在eclipse中启动程序 ##服务器上启动nc,并输入内容
[root@spark1 ~]# nc -lk 9999
leo hello
tom word
leo hello
jack you
leo you ##统计结果
(hello,2)
(word,1)
(you,2)
3、scala案例
package cn.spark.study.streaming import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds /**
* @author Administrator
*/
object WindowHotWord { def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local[2]")
.setAppName("WindowHotWord")
val ssc = new StreamingContext(conf, Seconds(1)) val searchLogsDStream = ssc.socketTextStream("spark1", 9999)
val searchWordsDStream = searchLogsDStream.map { _.split(" ")(1) }
val searchWordPairsDStream = searchWordsDStream.map { searchWord => (searchWord, 1) }
val searchWordCountsDSteram = searchWordPairsDStream.reduceByKeyAndWindow(
(v1: Int, v2: Int) => v1 + v2,
Seconds(60),
Seconds(10)) val finalDStream = searchWordCountsDSteram.transform(searchWordCountsRDD => {
val countSearchWordsRDD = searchWordCountsRDD.map(tuple => (tuple._2, tuple._1))
val sortedCountSearchWordsRDD = countSearchWordsRDD.sortByKey(false)
val sortedSearchWordCountsRDD = sortedCountSearchWordsRDD.map(tuple => (tuple._1, tuple._2)) val top3SearchWordCounts = sortedSearchWordCountsRDD.take(3)
for(tuple <- top3SearchWordCounts) {
println(tuple)
} searchWordCountsRDD
}) finalDStream.print() ssc.start()
ssc.awaitTermination()
} } ##在eclipse中启动程序 ##服务器上启动nc,并输入内容
[root@spark1 ~]# nc -lk 9999
leo hello
leo hello
leo hello
leo word
leo word
leo word
leo hello
leo you
leo you ##统计结果
(hello,4)
(word,3)
(you,2)
57、Spark Streaming: window滑动窗口以及热点搜索词滑动统计案例的更多相关文章
- 48、Spark SQL之与Spark Core整合之每日top3热点搜索词统计案例实战
一.概述 1.需求分析 数据格式: 日期 用户 搜索词 城市 平台 版本 需求: 1.筛选出符合查询条件(城市.平台.版本)的数据 2.统计出每天搜索uv排名前3的搜索词 3.按照每天的top3搜索词 ...
- Spark Streaming实战
1.Storm 和 SparkStreaming区别 Storm 纯实时的流式处理,来一条数据就立即进行处理 SparkStreaming 微批处理,每次处理 ...
- Spark Streaming之五:Window窗体相关操作
SparkStreaming之window滑动窗口应用,Spark Streaming提供了滑动窗口操作的支持,从而让我们可以对一个滑动窗口内的数据执行计算操作.每次掉落在窗口内的RDD的数据,会被聚 ...
- Spark-Streaming之window滑动窗口应用
Spark-Streaming之window滑动窗口应用,Spark Streaming提供了滑动窗口操作的支持,从而让我们可以对一个滑动窗口内的数据执行计算操作.每次掉落在窗口内的RDD的数据,会被 ...
- spark streaming (二)
一.基础核心概念 1.StreamingContext详解 (一) 有两种创建StreamingContext的方式: val conf = new SparkConf().s ...
- Spark Streaming初探
1. 介绍 Spark Streaming是Spark生态系统中一个重要的框架,建立在Spark Core之上,与Spark SQL.GraphX.MLib相并列. Spark Streaming是 ...
- Spark 学习笔记之 Streaming Window
Streaming Window: 上图意思:每隔2秒统计前3秒的数据 slideDuration: 2 windowDuration: 3 例子: import org.apache.kafka.c ...
- Spark Streaming流式处理
Spark Streaming介绍 Spark Streaming概述 Spark Streaming makes it easy to build scalable fault-tolerant s ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十二)Spark Streaming接收流数据及使用窗口函数
官网文档:<http://spark.apache.org/docs/latest/streaming-programming-guide.html#a-quick-example> Sp ...
随机推荐
- elasticsearch配置文件中http.cors.x字段有哪些用途和用法
http.cors.enabled 是否支持跨域,默认为false http.cors.allow-origin 当设置允许跨域,默认为*,表示支持所有域名,如果我们只是允许某些网站能访问,那么可以使 ...
- 使用canvas实现360水球波动
代码如下: <!DOCTYPE html> <html lang="en"> <head> <meta charset=" ...
- WPF 程序的编译过程
原文:WPF 程序的编译过程 基于 Sdk 的项目进行编译的时候,会使用 Sdk 中附带的 props 文件和 targets 文件对项目进行编译.Microsoft.NET.Sdk.WindowsD ...
- left join 左边有数据,右边无数据
参考了链接: https://blog.csdn.net/chenjianandiyi/article/details/52402011 主要是and和where的区别: 原Sql: Con ...
- C# vb .net实现玻璃桌子效果滤镜
在.net中,如何简单快捷地实现Photoshop滤镜组中的玻璃桌子效果呢?答案是调用SharpImage!专业图像特效滤镜和合成类库.下面开始演示关键代码,您也可以在文末下载全部源码: 设置授权 第 ...
- 实战Go内存泄露【转】
最近解决了我们项目中的一个内存泄露问题,事实再次证明pprof是一个好工具,但掌握好工具的正确用法,才能发挥好工具的威力,不然就算你手里有屠龙刀,也成不了天下第一,本文就是带你用pprof定位内存泄露 ...
- Python进阶(一)----函数
Python进阶(一)----函数初识 一丶函数的初识 什么函数: 函数是以功能为导向.一个函数封装一个功能 函数的优点: 1.减少代码的重复性, 2.增强了代码的可读性 二丶函数的结构 ...
- unittest使用
unittest:单元测试框架主要包含四部分: 1.测试固件(test fixture): 定义:包含执行测试前的准备setUP().测试执行完后的清扫工作tearDown() 注意: setUp() ...
- centos7 ipython安装
##下载yum源(Centos 7 为例)[root@localhost ~]# wget http://mirror.centos.org/centos/7/extras/x86_64/Packag ...
- 原生ajax解析&封装原生ajax函数
前沿:对于此篇随笔,完是简要写了几个重要的地方,具体实现细节完在提供的源码做了笔记 <一>ajax基本要点介绍--更好的介绍ajax 1. ajax对象中new XMLHttpReques ...