yarn cluster和yarn client模式区别——yarn-cluster适用于生产环境,结果存HDFS;而yarn-client适用于交互和调试,也就是希望快速地看到application的输出
Yarn-cluster VS Yarn-client
从广义上讲,yarn-cluster适用于生产环境;而yarn-client适用于交互和调试,也就是希望快速地看到application的输出。
从深层次的含义讲,yarn-cluster和yarn-client模式的区别其实就是Application Master进程的区别,yarn-cluster模式下,driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行。然而yarn-cluster模式不适合运行交互类型的作业。而yarn-client模式下,Application Master仅仅向YARN请求executor,client会和请求的container通信来调度他们工作,也就是说Client不能离开。
Yarn-cluster:
Spark Driver首先作为一个ApplicationMaster在YARN集群中启动,客户端提交给ResourceManager的每一个job都会在集群的worker节点上分配一个唯一的ApplicationMaster,由该ApplicationMaster管理全生命周期的应用。因为Driver程序在YARN中运行,所以事先不用启动Spark Master/Client,应用的运行结果不能在客户端显示(可以在history server中查看),所以最好将结果保存在HDFS而非stdout输出,客户端的终端显示的是作为YARN的job的简单运行状况。

步骤如下:
这期间包括四个步骤:
a). 连接到RM
b). 从RM ASM(ApplicationsManager )中获得metric、queue和resource等信息。
c). upload app jar and spark-assembly jar
d). 设置运行环境和container上下文(launch-container.sh等脚本)
3. NodeManager启动Spark App Master,并向ResourceManager AsM注册
4. Spark ApplicationMaster从HDFS中找到jar文件,启动DAGscheduler和YARN Cluster Scheduler
5. ResourceManager向ResourceManager AsM注册申请container资源(INFO YarnClientImpl: Submitted application)
6. ResourceManager通知NodeManager分配Container,这时可以收到来自ASM关于container的报告。(每个container的对应一个executor)
7. Spark ApplicationMaster直接和container(executor)进行交互,完成这个分布式任务。
需要注意的是:
a). Spark中的localdir会被yarn.nodemanager.local-dirs替换
b). 允许失败的节点数(spark.yarn.max.worker.failures)为executor数量的两倍数量,最小为3.
c). SPARK_YARN_USER_ENV传递给spark进程的环境变量
d). 传递给app的参数应该通过–args指定。
在yarn-client模式下,Driver运行在Client上,通过ApplicationMaster向RM获取资源。本地Driver负责与所有的executor container进行交互,并将最后的结果汇总。结束掉终端,相当于kill掉这个spark应用。一般来说,如果运行的结果仅仅返回到terminal上时需要配置这个。
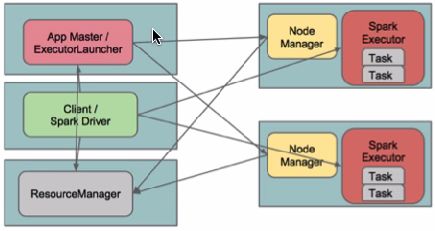

配置YARN-Client模式同样需要HADOOP_CONF_DIR/YARN_CONF_DIR和SPARK_JAR变量。
yarn cluster和yarn client模式区别——yarn-cluster适用于生产环境,结果存HDFS;而yarn-client适用于交互和调试,也就是希望快速地看到application的输出的更多相关文章
- spark on yarn,client模式时,执行spark-submit命令后命令行日志和YARN AM日志
[root@linux-node1 bin]# ./spark-submit \> --class com.kou.List2Hive \> --master yarn \> --d ...
- Spark On Yarn Cluster生产环境下JVM的OOM和Stack Overflow问题
1.Spark on Yarn下JVM的OOM问题及解决方式 2.Spark中Driver的Stack Overflow的问题及解决方式 Spark on Yarn cluster mode: 此时有 ...
- Spark代码中设置appName在client模式和cluster模式中不一样问题
问题 Spark应用名在使用yarn-cluster模式提交时不生效,在使用yarn-client模式提交时生效,如图1所示,第一个应用是使用yarn-client模式提交的,正确显示我们代码里设置的 ...
- spark跑YARN模式或Client模式提交任务不成功(application state: ACCEPTED)
不多说,直接上干货! 问题详情 电脑8G,目前搭建3节点的spark集群,采用YARN模式. master分配2G,slave1分配1G,slave2分配1G.(在安装虚拟机时) export SPA ...
- spark on yarn,cluster模式时,执行spark-submit命令后命令行日志和YARN AM日志
[root@linux-node1 bin]# ./spark-submit \> --class com.kou.List2Hive \> --master yarn \> --d ...
- Spark On Yarn搭建及各运行模式说明
之前记录Yarn:Hadoop2.0之YARN组件,这次使用Docker搭建Spark On Yarn 一.各运行模式 1.单机模式 该模式被称为Local[N]模式,是用单机的多个线程来模拟Spa ...
- Spark on YARN的两种运行模式
Spark on YARN有两种运行模式,如下 1.yarn-cluster:适合于生产环境. Spark的Driver运行在ApplicationMaster中,它负责向YARN Re ...
- spark基于yarn的两种提交模式
一.spark的三种提交模式 1.第一种,Spark内核架构,即standalone模式,基于Spark自己的Master-Worker集群. 2.第二种,基于YARN的yarn-cluster模式. ...
- Spark剖析-宽依赖与窄依赖、基于yarn的两种提交模式、sparkcontext原理剖析
Spark剖析-宽依赖与窄依赖.基于yarn的两种提交模式.sparkcontext原理剖析 一.宽依赖与窄依赖 二.基于yarn的两种提交模式深度剖析 2.1 Standalne-client 2. ...
随机推荐
- 【视频开发】ffmpeg实现dxva2硬件加速
这几天在做dxva2硬件加速,找不到什么资料,翻译了一下微软的两篇相关文档.这是第二篇,记录用ffmpeg实现dxva2. 第一篇翻译的Direct3D device manager,链接:http: ...
- 腾讯明眸极速高清升级2.0,助力韩国赛事超高清5G直播
近期,由腾讯云联合韩国CUDO通信研究所及intel推出的tile方式的viewport流服务编码,已正式通过测试.届时韩国最新5G网络将基于腾讯明眸-极速高清2.0和腾讯云直播产品能力,在韩国国内率 ...
- 【转帖】处理器史话 | 服务器CPU市场的战役, AMD、Intel和ARM的厮杀
处理器史话 | 服务器CPU市场的战役, AMD.Intel和ARM的厮杀 https://www.eefocus.com/mcu-dsp/377300 说完了个性鲜明的消费类电子,接下来聊一聊通 ...
- flask 表单填充数据报错!AttributeError: 'dict' object has no attribute 'getlist'
报错信息: AttributeError: 'dict' object has no attribute 'getlist' 解决: 虽然是小毛病,不得不说还是自己太粗心大意了.
- Ubuntu修改文件权限以及更换文件所有者
参数 -R 用来递归实现更改所有子文件和子目录的权限. 1.利用chmod修改权限: 对Document/目录下的所有子文件与子目录执行相同的权限变更: chmod -R 700 文件名 700是变更 ...
- D03-R语言基础学习
R语言基础学习——D03 20190423内容纲要: 1.导入数据 (1)从键盘输入 (2)从文本文件导入 (3)从excel文件导入 2.用户自定义函数 3.R访问MySQL数据库 (1)安装R ...
- IP核——PLL
一.Quartus II创建PLL 1.打开Quartus ii,点击Tools---MegaWizard Plug-In Manager 2.弹出创建页面,选择Creat a new custom ...
- Python字符串格式化方式之format
format方式是在Python3引入了一个新的字符串格式化的方法,并且随后支持了Python2.7.这个新的字符串格式化方法摆脱了%操作符并且使得字符串格式化的语法更规范了.现在时候通过调用字符串对 ...
- vue3 template refs dom的引用、组件的引用、获取子组件的值
介绍 通过 ref() 还可以引用页面上的元素或组件. DOM 的引用 <template> <div> <h3 ref="h3Ref">Tem ...
- Springboot 整合ApachShiro完成登录验证和权限管理
1.前言 做一个系统最大的问题就是安全问题以及权限的问题,如何正确的选择一个安全框架对自己的系统进行保护,这方面常用的框架有SpringSecurity,但考虑到它的庞大和复杂,大多数公司还是会选择 ...