JSOUP 爬虫
作者QQ:1095737364 QQ群:123300273 欢迎加入!
1.mavne 依赖:
<!--html 解析 : jsoup HTML parser library @ http://jsoup.org/-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
2.JSONPUtils工具:
package com.hiione.common.util;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; import java.io.IOException;
import java.util.Iterator; public class JsoupUtils { public static String jsoupElement(String content){
Document doc = Jsoup.parse(content);
Element body = doc.body();
Elements aHref=body.select("a");
Elements jsScript = body.select("script");
Elements form = body.select("form");
Elements link = body.select("link");
Elements ifrom = body.select("iframe ");
Elements http = body.select("http");
if(jsScript.size()!=0 ||aHref.size()!=0||form.size()!=0||link.size()!=0||ifrom.size()!=0||http.size()!=0){
return "0";
}
return "";
}
public static String jsoupElementByURL(String content){
String url = "http://as.meituan.com/meishi/all";
Document doc = null;
try {
doc = Jsoup.connect(url).get();
} catch (IOException e1) {
e1.printStackTrace();
}
Element body = doc.body();
Elements aHref=body.select("a");
Elements es=body.select("a");
for (Iterator it = es.iterator(); it.hasNext();) {
Element e = (Element) it.next();
System.out.println(e.text()+" "+e.attr("href"));
}
Elements jsScript = body.select("script");
Elements form = body.select("form");
Elements link = body.select("link");
Elements ifrom = body.select("iframe ");
Elements http = body.select("http");
if(jsScript.size()!=0 ||aHref.size()!=0||form.size()!=0||link.size()!=0||ifrom.size()!=0||http.size()!=0){
return "0";
}
return "";
}
}
3.jsoup 简介

4.文档输入
// 直接从字符串中输入 HTML 文档
String html = "<html><head><title>JSONP</title></head>" +
"<body><p>这里是 jsoup 项目的相关文章</p></body></html>";
Document doc = Jsoup.parse(html);
// 从URL直接加载 HTML 文档
Document doc = Jsoup.connect("http://www.baidu.net/").get();
String title = doc.title();
Document doc = Jsoup.connect("http://www.baidu.net/")
.data("query", "Java") //请求参数
.userAgent("I’m jsoup") //设置User-Agent
.cookie("auth", "token") //设置cookie
.timeout(3000) //设置连接超时时间
.post(); //使用POST方法访问URL
// 从文件中加载 HTML 文档
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.oschina.net/");
5.解析并提取 HTML 元素
File input = new File("D:/test.html");
Document doc = Jsoup.parse(input, "UTF-8", "http://www.baidu.net/");
Element content = doc.getElementById("content");
Elements links = content.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text();
}
File input = new File("D:\test.html");
Document doc = Jsoup.parse(input,"UTF-8","http://www.baidu.net/");
Elements links = doc.select("a[href]"); // 具有 href 属性的链接
Elements pngs = doc.select("img[src$=.png]");//所有引用png图片的元素
Element masthead = doc.select("div.masthead").first();
// 找出定义了 class="masthead" 的元素
Elements resultLinks = doc.select("h3.r > a"); // direct a after h3
6.修改数据
doc.select("div.comments a").attr("rel", "nofollow");
//为所有链接增加 rel=nofollow 属性
doc.select("div.comments a").addClass("mylinkclass");
//为所有链接增加 class="mylinkclass" 属性
doc.select("img").removeAttr("onclick"); //删除所有图片的onclick属性
doc.select("input[type=text]").val(""); //清空所有文本输入框中的文本
7.HTML 文档清理
String unsafe = "<p><a href='http://www.oschina.net/' onclick='stealCookies()'>JSONP</a></p>";
String safe = Jsoup.clean(unsafe, Whitelist.basic());
// 输出:
// <p><a href="http://www.baidu.net/" rel="nofollow">JSONP</a></p>
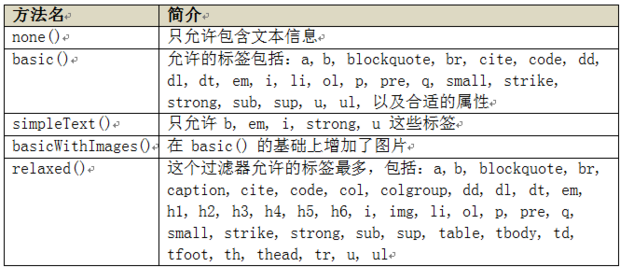
8.jsoup 的过人之处——选择器
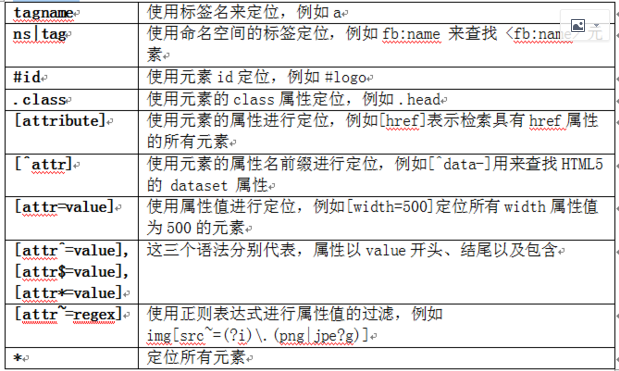
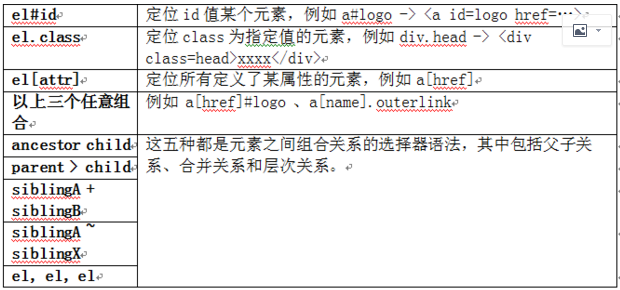
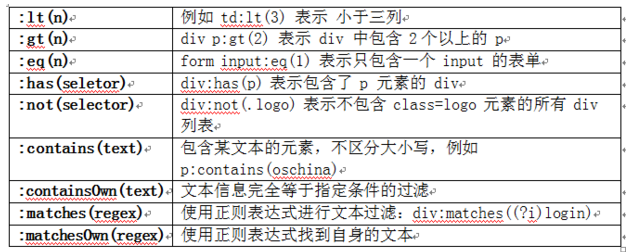
JSOUP 爬虫的更多相关文章
- jsoup爬虫简书首页数据做个小Demo
代码地址如下:http://www.demodashi.com/demo/11643.html 昨天LZ去面试,遇到一个大牛,被血虐一番,发现自己基础还是很薄弱,对java一些原理掌握的还是不够稳固, ...
- (java)Jsoup爬虫学习--获取智联招聘(老网站)的全国java职位信息,爬取10页
Jsoup爬虫学习--获取智联招聘(老网站)的全国java职位信息,爬取10页,输出 职位名称*****公司名称*****职位月薪*****工作地点*****发布日期 import java.io.I ...
- (java)Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息
Jsoup爬虫学习--获取网页所有的图片,链接和其他信息,并检查url和文本信息 此例将页面图片和url全部输出,重点不太明确,可根据自己的需要输出和截取: import org.jsoup.Jsou ...
- 【Java】Jsoup爬虫,一个简单获取京东商品信息的小Demo
简单记录 - Jsoup爬虫入门实战 数据问题?数据库获取,消息队列中获取中,都可以成为数据源,爬虫! 爬取数据:(获取请求返回的页面信息,筛选出我们想要的数据就可以了!) 我们经常需要分析HTML网 ...
- JSOUP爬虫示例
利用JSOUP做爬虫,爬取我博客中的所有标题加链接,代码示例如下: package com.test.jsoup; import java.io.IOException; import org.jso ...
- HttpClient&Jsoup爬虫的简单应用
详细的介绍已经有很多前辈总结,引用一下该篇文章:https://blog.csdn.net/zhuwukai/article/details/78644484 下面是一个代码的示例: package ...
- Jsoup爬虫任务总结
这两周由于公司需要大量数据爬取进数据库给用户展示素材,在不停的做爬虫工作,现在总算基本完成就剩清理数据的工作: 公司有一个采集器管理后台的项目,可以直接把爬虫代码打包成jar导入进去设置定时参数即可: ...
- 利用jsoup爬虫工具,爬取数据,并利用excel导出
import java.io.BufferedInputStream; import java.io.BufferedReader; import java.io.FileInputStream; i ...
- Jsoup爬虫解析
需要下载jsoup-1.8.1.jar包 jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQue ...
- jsoup爬虫,项目实战,欢迎收看
import com.mongodb.BasicDBObject import com.mongodb.DBCollection import org.jsoup.Jsoup import org.j ...
随机推荐
- python - django (ORM常用字段)
# """ python manage.py makemigrations # 更新操作 python manage.py migrate # 转换sql语句到数据库 1 ...
- [React] Create an Animate Content Placeholder for Loading State in React
We will create animated Content Placeholder as React component just like Facebook has when you load ...
- 2019-2020-1 20199302《Linux内核原理与分析》第五周作业
一.用户态.内核态和中断 1.一般现代cpu都有几种不用的指令执行级别 2.在高执行级别下,代码可以执行特权指令,访问任意的物理地址,这种CPU执行级别就对应着内核态. 3.在相应的低级别执行状态下, ...
- ERROR: `elasticsearch` directory is missing in the plugin zip
该问题出现在为elasticsearch安装中文分词器插件时 问题发生在插件和es版本不匹配~ 解决: es版本与插件版本对应齐 命令行安装 C:\Users\SeeClanUkyo>F:\el ...
- CSS精灵图(王者荣耀案例)
首先,我们应该知道引入精灵图的原因: 具体是因为,网页上面的每张图片都要经历一次请求才能展示给用户,小的图标频繁的请求服务器,降低页面的加载速度,为了有效地减少服务器接收和发送请求的次数,提高页面的加 ...
- Centos 7 安装 dotnet 环境
Centos 7 安装 dotnet 环境 下载官方 rpm yum 源 直接 yum install 安装rpm -Uvh https://packages.microsoft.com/confi ...
- ROS里程计
gmapping导航建图包里建图需要里程计信息,且导航也需要. 整个移动机器人的控制结构如下图所示,其中base_controller节点将订阅的cmd_vel信息通过串口或其它通信接口发送给下位机( ...
- 44个Java性能优化
44个Java性能优化 首先,代码优化的目标是: 减小代码的体积 提高代码运行效率 代码优化细节 1 .尽量指定类.方法的final修饰符 带有final修饰符的类是不可派生的.在Java核心AP ...
- RNN梯度消失和爆炸的原因 以及 LSTM如何解决梯度消失问题
RNN梯度消失和爆炸的原因 经典的RNN结构如下图所示: 假设我们的时间序列只有三段, 为给定值,神经元没有激活函数,则RNN最简单的前向传播过程如下: 假设在t=3时刻,损失函数为 . 则对于一 ...
- zabbix监控线
echo mntr | nc 127.0.0.1 2181获取mntr的信息 换成conf将获得conf信息,从中找出需要监控项 conf: clientPort:客户端端口号 dataDir:数据文 ...