Windows 上用IntelliJ Idea调试百度大数据分析框架Apache Doris FE
A. 环境准备
1. 安装jdk1.8+, Intelij IDEA
2. linux上编译好fe前端代码,主要目的是获取自动生成的代码,加入到前段工程里面去用于在idea中编译fe工程。具体编译请参照本人前期博文:CentOS 上使用vscode 调试百度大数据分析框架Apache DorisBE,编译好之后:
tar -cvf /home/workspace/palo0.8.1/genSrc/buid/java.tar /home/workspace/palo0.8.1/gen_cpp/buid/java #打包自动生成的java代码
sz /home/workspace/palo0.8.1/gen_cpp/buid/java.tar #下载自动生成代码到windows本地
自动生成的文件结构如图:
其中,
analysis文件夹下为sql语法扫描和解析的自动生成代码,是通过调用java-cup-0.11a.jar & jflex-1.4.3.jar 生成的语法分析代码和词法分析代码,对应的输入源为..../parser/sql_parser.y 和..../parser/sql_scanner.flex
buildins文件夹下为通过调用python2.7自动生成的palo内置类型和函数的代码,输入源为.../scripts/目录下的.py文件
common文件夹下为通过protocobuf生成的通信协议流代码,输入源为.../proto/目录下的.proto文件
thrift文件夹下为通过调用/thirdparty/installed/bin/thrift生成的通讯代码,palo FE和BE之间进行通信是使用thrift来进行的,输入源为.../gensrc/thrift下的.thrift文件
3. 把自动生成的代码复制到windows fe代码的正确目录下,在本人机器上是......\fe\src\com\baidu\palo,如图:
B) 调试:
1. 用idea导入fe工程;
2. 在fe目录下创建lib库,把引用的库文件放置到lib目录下:
3. 编译idea,结果一定是失败的!
4. 将lib目录下的help-resource.zip复制到/fe/output(idea工程默认的输出目录)的...\fe\out\production\baidu目录下,在本机中是C:\Temp\palo-0.8.1-beta\fe\out\production\baidu目录,可以参照自己机器的具体路径进行正确配置。该文件的作用是解压后生成帮助文件,具体使用位置为:
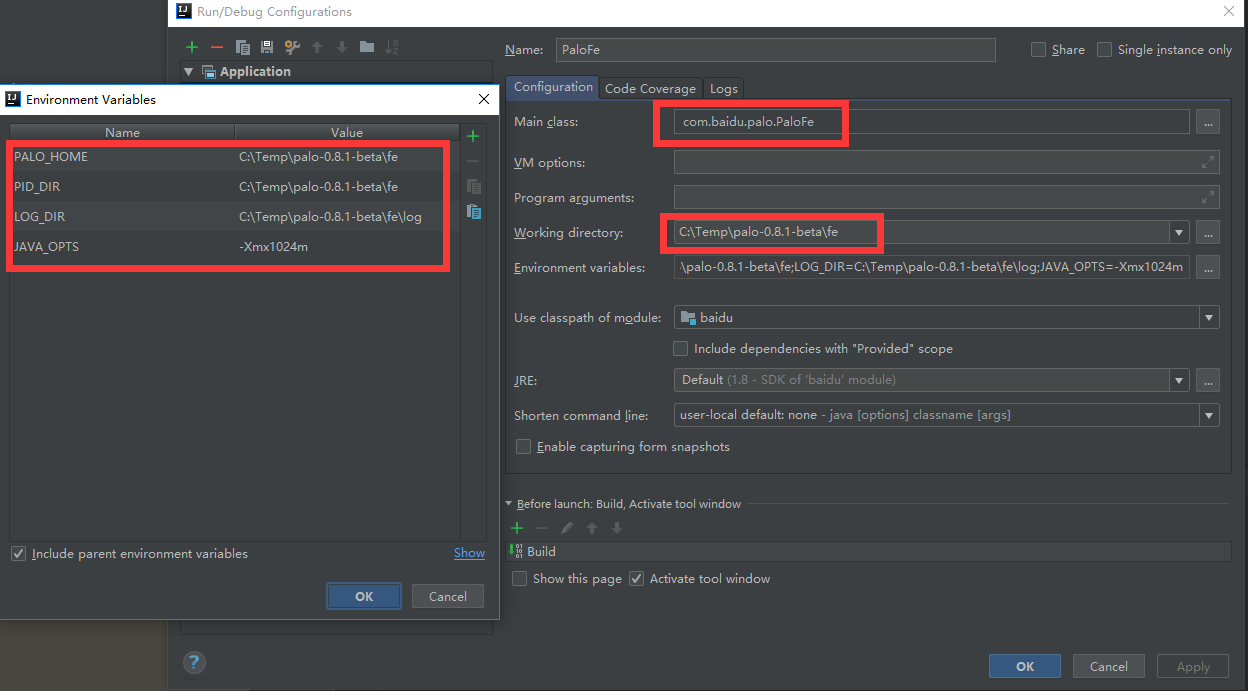
5. 在IdeaJ中设置环境变量:JAVA_OPTS,PALO_HOME,PID_DIR,LOG_DIR,在本人机器上,配置为如下,各位可以根据自己的实际情况进行配置。
JAVA_OPTS=-Xmx1024m
PALO_HOME=C:\Temp\palo-0.8.-beta\fe
PID_DIR=C:\Temp\palo-0.8.-beta\fe
LOG_DIR=C:\Temp\palo-0.8.-beta\fe\log
其中JAVA_OPTS可以不配置。
6. 在PALO_HOME文件夹下创建目录,palo-meta(必须手动创建),该目录是fe存放meta data的目录,fe所有的元数据均存放在此位置。

7. 设置导入label的保留时间
vim fe/conf/fe.conf
添加:
label_keep_max_second = #second, the default value is **= days
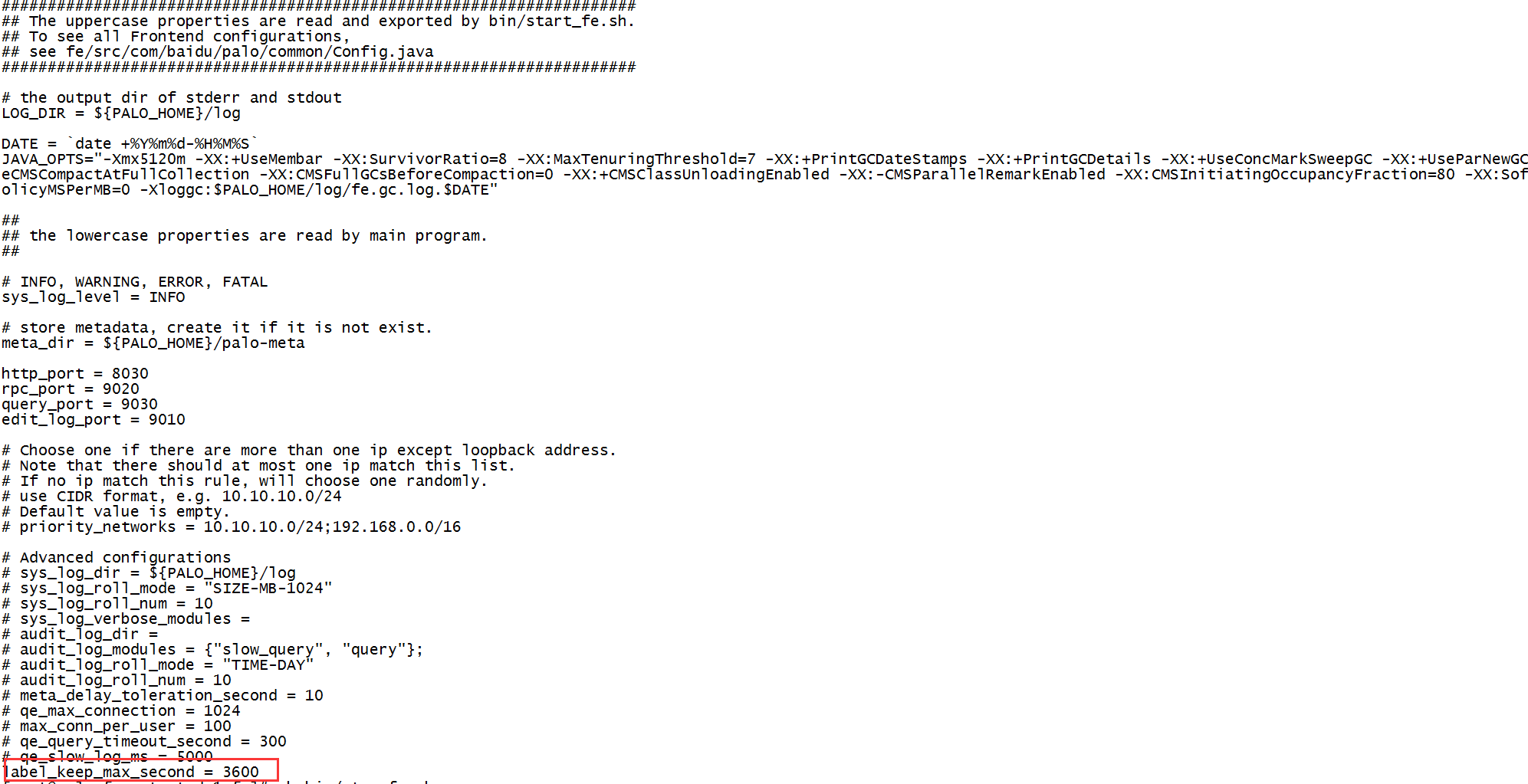
设置这个属性,在导入数据调试时很有用处,可以避免大量label干扰视线,可能个人有洁癖。
8. 设置be的最大使用内存
set exec_mem_limit=; #设置为20G,只针对当前session 有效,默认值为2G
set global exec_mem_limit=; #设置为20G,全局永久生效,配置将保存在fe的元数据中,默认值为2G
9. 在IdeaJ中开始你的调试之旅,have fun with big data using palo!!
Windows 上用IntelliJ Idea调试百度大数据分析框架Apache Doris FE的更多相关文章
- CentOS 上使用vscode 调试百度大数据分析框架Apache Doris BE
A: 前期准备工作 1. 安装vscode,详细请参见vscode官网https://code.visualstudio.com/docs/setup/linux,摘要如下: sudo rpm --i ...
- 使用Windows上的Eclipse 远程调试 linux下的Tomcat
1:修改Linux上Tomcat的catalina.sh,第一行添加declare -x CATALINA_OPTS="-Xdebug -Xrunjdwp:transport=dt_sock ...
- 在Windows上安装PHP(将PHP加载到Apache中)
第一步:在 windows.php.net 下载软件包 第二步:解压压缩包,将解压后的目录放到指定目录并重命名 第三步: 创建PHP配置文件,修改Apache配置文件(httpd.conf),将PHP ...
- 分享一个.NET平台开源免费跨平台的大数据分析框架.NET for Apache Spark
今天早上六点半左右微信群里就看到张队发的关于.NET Spark大数据的链接https://devblogs.microsoft.com/dotnet/introducing-net-for-apac ...
- 大数据分析引擎Apache Flink
Apache Flink是一个高效.分布式.基于Java实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性.灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分 ...
- 国人之光:大数据分析神器Apache Kylin
一.简介 Apache Kylin是一个开源的.分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献 ...
- JVM 源码分析(二):搭建 JDK 8 源码调试环境(Windows 上使用 CLion)
前言 一.准备源码 二.安装 "Bootstrap JDK" 三.配置编译环境 四.编译与测试 五.安装 CMake 和 GDB 五.准备远程调试 六.开始远程调试 前言 上一篇文 ...
- Windows下fabric sdk连接Linux上fabric网络的调试过程
上个月刚入职一家公司从事区块链研发工作,选型采用Hyperledger Fabric作为开发平台.团队的小组成员全部采用的是在VirtualBox上面安装桌面版的Ubuntu 16.04虚拟机,开发工 ...
- 大数据高性能数据库Redis在Windows上的使用教程
Redis学习笔记----Redis在windows上的安装配置和使用 Redis简介 redis是一个key-value存储系统.和Memcached类似,它支持存储的value类型相对更多,包括s ...
随机推荐
- Android res目录结构
所有以drawable开头的文件夹都是用来放图片的 所有以values开头的文件夹都是用来放字符串的 layout 文件夹是用来放布局文件的 menu 文件夹是用来放菜单文件的.之所以有这么多 dra ...
- 并发编程-synchronized关键字大总结
0.synchronized 的特点: 可以保证代码的原子性和可见性. 1.synchronized 的性质: 可重入(可以避免死锁.单个线程可以重复拿到某个锁,锁的粒度是线程而不是调用).不可中断( ...
- PHP如何生成文章预览图
PHP如何生成文章预览图 一.总结 一句话总结:php的wkhtmltox扩展,php官方文档有怎么使用,或者github,或者百度,等等等等 wkhtmltox 1.PHP如何自动生成文章预览图? ...
- python批量修改ssh密码
由于工作需要本文主结合了excel表格,对表格中的ssh密码进行批量修改 以下是详细代码(python3): #!/usr/bin/env python#-*-coding:utf-8-*- impo ...
- Rails 5 Test Prescriptions 倒数第2章spring gem 如何让测试变快。分离rails(只有原理)
Spring speeds up development by keeping your application running in the background Rails程序自动增加:sprin ...
- UVA-10779 Collectors Problem (网络流建模)
题目大意:有n个人,已知每人有ki个糖纸,并且知道每张糖纸的颜色.其中,Bob希望能和同伴交换使得手上的糖纸数尽量多.他的同伴只会用手上的重复的交换手上没有的,并且他的同伴们之间不会产生交换.求出Bo ...
- axis2 webservice jar包使用情况(转)
原文地址:axis2 webservice jar包使用情况 今天使用axis2webservice,整理了下jar包,方便以后时候. axis2 webservice 服务端jar包: --> ...
- 【hive】count() count(if) count(distinct if) sum(if)的区别
表名: user_active_day (用户日活表) 表内容: user_id(用户id) user_is_new(是否新用户 1:新增用户 0:老用户) location_city(用户所在地 ...
- Git创建仓库的方法(github翻译)
…通过命令行创建一个新的仓库 echo "# GitTest" >> README.md # 船舰一个说明文件,说明内容是 "# GitTest" ...
- 基于Open XML 导出数据到Excel
数据导出的结果: 步骤1.新建一个Excel 文档,模板根据自己需要设置 步骤2.使用OpenXml 打开Excel 文件 步骤3.点击ReflectCode 功能,生成相应的代码文档 using ...