Raft算法详解
一致性算法Raft详解
背景
熟悉或了解分布性系统的开发者都知道一致性算法的重要性,Paxos一致性算法从90年提出到现在已经有二十几年了,而Paxos流程太过于繁杂实现起来也比较复杂,可能也是以为过于复杂 现在我听说过比较出名使用到Paxos的也就只是Chubby、libpaxos,搜了下发现Keyspace、BerkeleyDB数据库中也使用了该算法作为数据的一致性同步,虽然现在很广泛使用的Zookeeper也是基于Paxos算法来实现,但是Zookeeper使用的ZAB(Zookeeper Atomic Broadcast)协议对Paxos进行了很多的改进与优化,算法复杂我想会是制约他发展的一个重要原因;说了这么多只是为了要引出本篇文章的主角Raft一致性算法,没错Raft就是在这个背景下诞生的,文章开头也说到了Paxos最大的问题就是复杂,Raft一致性算法就是比Paxos简单又能实现Paxos所解决的问题的一致性算法。
Raft是斯坦福的Diego Ongaro、John Ousterhout两个人以易懂(Understandability)为目标设计的一致性算法,在2013年发布了论文:《In Search of an Understandable Consensus Algorithm》从2013年发布到现在不过只有两年,到现在已经有了十多种语言的Raft算法实现框架,较为出名的有etcd,Google的Kubernetes也是用了etcd作为他的服务发现框架;由此可见易懂性是多么的重要。
Raft概述
与Paxos不同Raft强调的是易懂(Understandability),Raft和Paxos一样只要保证n/2+1节点正常就能够提供服务;众所周知但问题较为复杂时可以把问题分解为几个小问题来处理,Raft也使用了分而治之的思想把算法流程分为三个子问题:选举(Leader election)、日志复制(Log replication)、安全性(Safety)三个子问题;这里先简单介绍下Raft的流程;
Raft开始时在集群中选举出Leader负责日志复制的管理,Leader接受来自客户端的事务请求(日志),并将它们复制给集群的其他节点,然后负责通知集群中其他节点提交日志,Leader负责保证其他节点与他的日志同步,当Leader宕掉后集群其他节点会发起选举选出新的Leader;
Raft简介
Raft是一个用于日志复制,同步的一致性算法。它提供了和Paxos一样的功能和性能,但是它的算法结构与Paxos不同。这使得Raft相比Paxos更好理解,并且更容易构建实际的系统。为了强调可理解性,Raft将一致性算法分解为几个关键流程(模块),例如选主,安全性,日志复制,通过将分布式一致性这个复杂的问题转化为一系列的小问题进而各个击破的方式来解决问题。同时它通过实施一个更强的一致性来减少一些不必要的状态,进一步降低了复杂性。Raft还包括了一个新机制,允许线上进行动态的集群扩容,利用有交集的大多数机制来保证安全性。
####一些背景知识
#####A. 一致性算法简单回顾
一致性算法允许一个集群像一个整体一样工作,即使其中一些机器出现故障也不会影响正常服务。正因为如此,一致性算法在构建可信赖的大型分布式系统中都扮演着重要的角色。Paxos算法在过去10年中统治着这一领域:绝大多数实现都是基于Paxos,同时在教学领域讲解一致性问题时Paxos也经常拿来作为范例。但是不幸的是,尽管有很多工作都在试图降低它的复杂性,但是Paxos仍然难以理解。并且,Paxos自身算法的结构不能直接用于实际系统中,想要使用必须要进行大幅度改变,这些都导致无论在工业界还是教育界,Paxos都让人很DT。
时势造英雄,在这样的背景下Raft应运而生。Raft算法使用了一些特别的技巧使得它易于理解,包括算法分解(Raft主要分为选主,日志复制和安全三个大模块),同时在不影响功能的情况下,减少复制状态机的状态,降低复杂性。Raft算法或多或少的和已经存在的一些一致性算法有着相似之处,但是也具有如下特征:
- 强leader语义:相比其他一致性算法,Raft使用增强形式的leader语义。举个例子,日志只能由leader复制给其它节点。这简化了日志复制需要的管理工作,使得Raft易于理解。
- leader的选择:Raft使用随机计时器来选择leader,它的实现只是在心跳机制(任何一致性算法中都必须实现)上多做了一点“文章”,不会增加延迟和复杂性。
- 关系改变:Raft使用了一个新机制joint consensus允许集群动态在线扩容,保障Raft的可持续服务能力。
Raft算法已经被证明是安全正确的,同时也有实验支撑Raft的效率不比其他一致性算法差。最关键是Raft算法要易于理解,在实际系统应用中易于实现的特点使得它成为了解决分布式系统一致性问题上新的“宠儿”。
#####B. 复制状态机
一致性算法是从复制状态机中提出的。简单地讲,复制状态机就是通过彼此之间的通信来将一个集群从一个一致性状态转向下一个一致性状态,它要能容忍很多错误情形。经典如GFS,HDFS都是使用了单独的复制状态机负责选主,存储一些能够在leader crash情况下进行恢复的配置信息等,比如Chubby和ZooKeeper。
复制状态机的典型实现是基于复制日志,如下图所示:
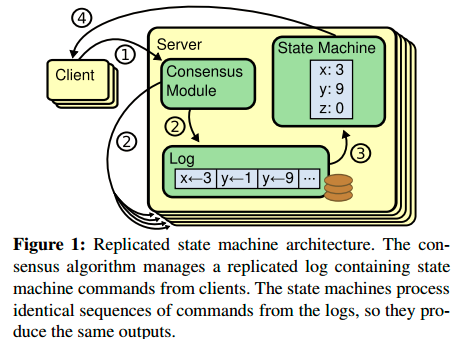
每个server上存储了一个包含一系列指令的日志,这些指令,状态机要按序执行。每一个日志在相同的位置存放相同的指令(可以理解成一个log包含一堆entry,这些entry组成一个数组,每个entry是一个command,数组相同偏移处的command相同),所以每一个状态机都执行了相同序列的指令。一致性算法就是基于这样一个简单的前提:集群中所有机器当前处于一个一致性状态,如果它们从该状态出发执行相同序列的指令走状态机的话,那么它们的下一个状态一定一致。但由于分布式系统中存在三态(成功,失败,无响应),如何来确保每台机器上的日志一致就非常复杂,也是一致性算法需要解决的问题。通常来讲,一致性算法需要具有以下特征:
- 安全性:在非拜占庭故障下,包括网络分区,延迟,丢包,乱序等等情况下都保证正确。
- 绝对可用:只要集群中大多数机器正常,集群就能错误容忍,进行正常服务。
- 不依赖时序保证一致性:由于使用逻辑时钟,所以物理时钟错误或者极端的消息延迟都不影响可用性。
- 通常情况下,一个指令可以在一轮RPC周期内由大多数节点完成,宕机或者运行速度慢的少数派不影响系统整体性能。
####Raft算法
前面对Raft算法进行了简要的介绍,这里开始对它进行深入分析。Raft实现一致性的机制是这样的:首先选择一个leader全权负责管理日志复制,leader从客户端接收log entries,将它们复制给集群中的其它机器,然后负责告诉其它机器什么时候将日志应用于它们的状态机。举个例子,leader可以在无需询问其它server的情况下决定把新entries放在哪个位置,数据永远是从leader流向其它机器。一个leader可以fail或者与其他机器失去连接,这种情形下会有新的leader被选举出来。
通过leader机制,Raft将一致性难题分解为三个相对独立的子问题:
- Leader选举:当前leader跪了的情况下,新leader被选举出来。
- 日志复制:leader必须能够从客户端接收log entries,然后将它们复制给其他机器,强制它们与自己一致。
- 安全性:如果任何节点将偏移x的log entry应用于自己的状态机,那么其他节点改变状态机时使用的偏移x的指令必须与之相同。
#####A. Raft基本知识
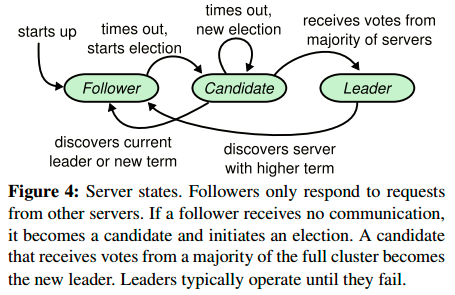
一个Raft集群包含单数个server,5个是一个典型配置,允许该系统最多容忍两个机器fail。在任何时刻,每个server有三种状态:leader,follower,candidate。正常运行时,只有一个leader,其余全是follower。follower是被动的:它们不主动提出请求,只是响应leader和candidate的请求。leader负责处理所有客户端请求(如果客户端先连接某个follower,该follower要负责把它重定向到leader)。第三种状态candidate用于选主。下图展示了这些状态以及它们之间的转化:
Raft将时间分解成任意长度的terms,如下图所示:
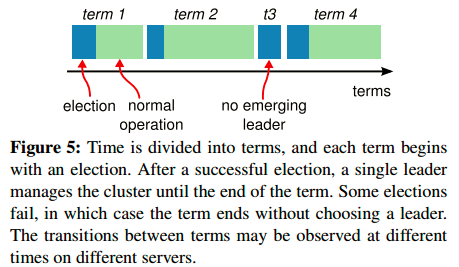
terms有连续单调递增的编号,每个term开始于选举,这一阶段每个candidate都试图成为leader。如果一个candidate选举成功,它就在该term剩余周期内履行leader职责。在某种情形下,可能出现选票分散,没有选出leader的情况,这时新的term立即开始。Raft确保在任何term都只可能存在一个leader。term在Raft用作逻辑时钟,servers可以利用term判断一些过时的信息:比如过时的leader。每台server都存储当前term号,它随时间单调递增。term号可以在任何server通信时改变:如果某台server的当前term号小于其它servers,那么这台server必须更新它的term号,与它人保持一致;如果一个candidate或者leader发现自己的term过期,它就必须要“放下身段”变成follower;如果某台server收到一个过时的请求(拥有过时的term号),它会拒绝该请求。Raft servers使用RPC交互,基本的一致性算法只需要两种RPC。RequestVote RPCs由candidate在选举阶段发起。AppendEntries RPCs在leader复制数据时发起,leader在和其他人做心跳时也用该RPC。servers发起一个RPC,如果在没得到响应,则需要不断重试。另外,发起RPC是并行的。
#####B. leader选举
Raft使用心跳机制来触发选举。当server启动时,初始状态都是follower。每一个server都有一个定时器,超时时间为election timeout,如果某server没有超时的情况下收到来自leader或者candidate的任何RPC,定时器重启,如果超时,它就开始一次选举。leader给其他人发RPC要么复制日志,要么就是用来告诉followers老子是leader,你们不用选举的心跳(告诉followers对状态机应用日志的消息夹杂在心跳中)。如果某个candidate获得了大多数人的选票,它就赢得了选举成为新leader。每个server在某个term周期内只能给最多一个人投票,按照先来先给的原则。新leader要给其他人发送心跳,阻止新选举。
在等待选票过程中,一个candidate,假设为A,可能收到它人的声称自己是leader的AppendEntries RPC,如果那家伙的term号大于等于A的,那么A承认他是leader,自己重新变成follower。如果那家伙比自己小,那么A拒绝该RPC,继续保持candidate状态。
还有第三种可能性就是candidate既没选举成功也没选举失败:如果多个followers同时成为candidate去拉选票,导致选票分散,任何candidate都没拿到大多数选票,这种情况下Raft使用超时机制来解决。Raft给每一个server都分配一个随机长度的election timeout(一般是150——300ms),所以同时出现多个candidate的可能性不大,即使机缘巧合同时出现了多个candidate导致选票分散,那么它们就等待自己的election timeout超时,重新开始一次新选举(再一再二不能再三再四,不可能每次都同时出现多个candidate),实验也证明这个机制在选举过程中收敛速度很快。
#####C. 日志复制
一旦选举出了一个leader,它就开始负责服务客户端的请求。每个客户端的请求都包含一个要被复制状态机执行的指令。leader首先要把这个指令追加到log中形成一个新的entry,然后通过AppendEntries RPCs并行的把该entry发给其他servers,其他server如果发现没问题,复制成功后会给leader一个表示成功的ACK,leader收到大多数ACK后应用该日志,返回客户端执行结果。如果followers crash或者丢包,leader会不断重试AppendEntries RPC。Logs按照下图组织:
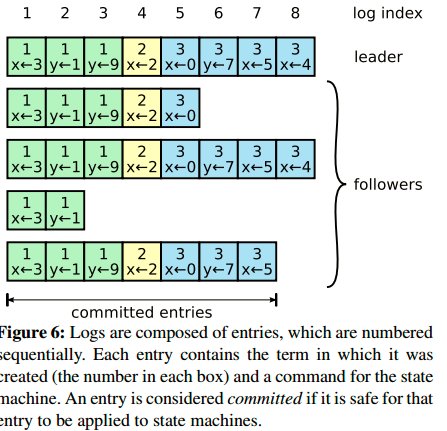
每个log entry都存储着一条用于状态机的指令,同时保存从leader收到该entry时的term号。该term号可以用来判断一些log之间的不一致状态。每一个entry还有一个index指明自己在log中的位置。
leader需要决定什么时候将日志应用给状态机是安全的,被应用的entry叫committed。Raft保证committed entries持久化,并且最终被其他状态机应用。一个log entry一旦复制给了大多数节点就成为committed。同时要注意一种情况,如果当前待提交entry之前有未提交的entry,即使是以前过时的leader创建的,只要满足已存储在大多数节点上就一次性按顺序都提交。leader要追踪最新的committed的index,并在每次AppendEntries RPCs(包括心跳)都要捎带,以使其他server知道一个log entry是已提交的,从而在它们本地的状态机上也应用。
Raft的日志机制提供两个保证,统称为Log Matching Property:
- 不同机器的日志中如果有两个entry有相同的偏移和term号,那么它们存储相同的指令。
- 如果不同机器上的日志中有两个相同偏移和term号的日志,那么日志中这个entry之前的所有entry保持一致。
第一个保证是由于一个leader在指定的偏移和指定的term,只能创建一个entry,log entries不能改变位置。第二个保证通过AppendEntries RPC的一个简单的一致性检查机制完成。当发起一个AppendEntries RPC,leader会包含正好排在新entries之前的那个entry的偏移和term号,如果follower发现在相同偏移处没有相同term号的一个entry,那么它拒绝接受新的entries。这个一致性检查以一种类似归纳法的方式进行:初始状态大家都没有日志,不需要进行Log Matching Property检查,但是无论何时followers只要日志要追加都要进行此项检查。因此,只要AppendEntries返回成功,leader就知道这个follower的日志一定和自己的完全一样。
在正常情形下,leader和follower的日志肯定是一致的,所以AppendEntries一致性检查从不失败。然而,如果leader crash,那么它们的日志很可能出现不一致。这种不一致会随着leader或者followers的crash变得非常复杂。下图展示了所有日志不一致的情形:
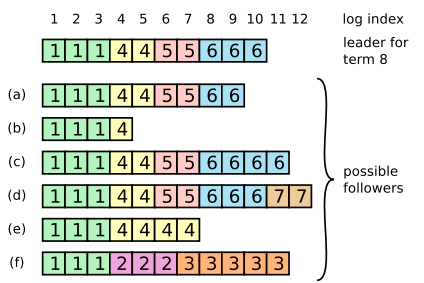
如上图(a)(b)followers可能丢失日志,(c)(d)有多余的日志,或者是(e)(f)跨越多个terms的又丢失又多余。在Raft里,leader强制followers和自己的日志严格一致,这意味着followers的日志很可能被leader的新推送日志所覆盖。
leader为了强制它人与自己一致,势必要先找出自己和follower之间存在分歧的点,也就是我的日志与你们的从哪里开始不同。然后令followers删掉那个分歧点之后的日志,再将自己在那个点之后的日志同步给followers。这个实现也是通过AppendEntries RPCs的一致性检查来做的。leader会把发给每一个follower的新日志的偏移nextIndex也告诉followers。当新leader刚开始服务时,它把所有follower的nextIndex都初始化为它最新的log entry的偏移+1(如上图中的11)。如果一个follower的日志和leader的不一致,AppendEntries RPC会失败,leader就减小nextIndex然后重试,直到找到分歧点,剩下的就好办了,移除冲突日志entries,同步自己的。当然这里有很大的优化余地,完全不需要一步一步回溯,怎么玩请自己看论文 1,很简单。
#####D. 安全性
前文讲解了Raft如何选主和如何进行日志复制,然而这些还不足以保证不同节点能执行严格一致的指令序列,需要额外的一些安全机制。比如,一个follower可能在当前leader commit日志时不可用,然而过会它又被选举成了新leader,这样这个新leader可能会用新的entries覆盖掉刚才那些已经committed的entries。结果不同的复制状态机可能会执行不同的指令序列,产生不一致的状况。这里Raft增加了一个可以确保新leader一定包含任何之前commited entries的选举机制。
(1) 选举限制
Raft使用了一个投票规则来阻止一个不包含所有commited entries的candidate选举成功。一个candidate为了选举成功必须联系大多数节点,假设它们的集合叫A,而一个entry如果能commit必然存储在大多数节点,这意味着对于每一个已经committed的entry,A集合中必然有一个节点持有它。如果这个candidate的Log不比A中任何一个节点旧才有机会被选举为leader,所以这个candidate如果要成为leader一定已经持有了所有commited entries(注意我说的持有指只是储存,不一定被应用到了复制状态机中。比如一个老的leader将一个entry发往大多数节点,它们都成功接收,老leader随即就commit这个entry,然后挂掉,此时这个entry叫commited entry,但是它不一定应用在了集群中所有的复制状态机上)。这个实现在RequestVote RPC中:该RPC包含了candidate log的信息,选民如果发现被选举人的log没有自己新,就拒绝投票。Raft通过比较最近的日志的偏移和term号来决定谁的日志更新。如果两者最近的日志term号不同,那么越大的越新,如果term号一样,越长的日志(拥有更多entries)越新。
(2) 提交早期terms的entries
正如前面所述的那样,一个leader如果知道一个当前term的entry如果储在大多数节点,就认为它可以commit。但是,一个leader不能也认为一个早于当前term的entry如果存在大多数节点,那么也是可以commit的。下图展示了这样一种状况,一个老的log存储在大多数节点上,但是仍有可能被新leader覆盖掉:

要消除上图中的问题,Raft采取针对老term的日志entries绝不能仅仅通过它在集群中副本的数量满足大多数,就认为是可以commit的。完整的commit语义也演变成:一个日志entry如果能够被认为是可以提交的,必须同时满足两个条件:
- 这个entry存储在大多数节点上
- 当前term至少有一个entry存储在大多数节点。
以上图为例,这两个条件确保一旦当前leader将term4的entry复制给大多数节点,那么S5不可能被选举为新leader了(日志term号过时)。综合考虑,通过上述的选举和commit机制,leaders永远不会覆盖已提交entries,并且leader的日志永远绝对是”the truth”。
(3) 调解过期leader
在Raft中有可能同一时刻不只一个server是leader。一个leader突然与集群中其他servers失去连接,导致新leader被选出,这时刚才的老leader又恢复连接,此时集群中就有了两个leader。这个老leader很可能继续为客户端服务,试图去复制entries给集群中的其它servers。但是Raft的term机制粉碎了这个老leader试图造成任何不一致的行为。每一个RPC servers都要交换它们的当前term号,新leader一旦被选举出来,肯定有一个大多数群体包含了最新的term号,老leader的RPC都必须要联系一个大多数群体,它必然会发现自己的term号过期,从而主动让贤,退变为follower状态。
然而有可能是老leader commit一个entry后失去连接,这时新leader必然有那个commit的entry,只是新leader可能还没commit它,这时新leader会在初次服务客户端前先把这个entry再commit一次,followers如果已经commit过直接返回成功,没commit就commit后返回成功而已,不会造成不一致。
#####E. Follower 或者candidate crash
Followers和candidate的crash比起leader来说处理要简单很多,它们的处理流程是相同的,如果某个follower或者candidate crash了,那么未来发往它的RequestVote和AppendEntries RPCs 都会失败,Raft采取的策略就是不停的重发,如果crash的机器恢复就会执行成功。另外,如果server crash是在完成一个RPC但在回复之前,那么在它恢复之后仍然会收到相同的RPC(让它重试一次),Raft的所有RPC都是幂等操作,如果follower已经有了某个entry,但是leader又让它复制,follower直接忽略即可。
#####F. 时间与可用性
Raft集群的可用性需要满足一个时间关系,即下面的公式:

broadcastTime代表平均的广播延迟(从并行发起RPC开始,直到收到大多数的回复为止)。electionTimeout就是前文所述的超时时间间隔,MTBF代表一个机器两次宕机时间间隔的平均值。broadcastTime必须远远小于electionTimeout,否则会频繁触发无意义的选举重启。electionTimeout远远小于MTBF就很好理解了。
####集群扩容
迄今为止的讨论都是假设集群配置不变的情况下(参与一致性算法的机器数目不变),但是实际中集群扩容(广义概念,泛指集群容量变化,可增可减)有时是必须的。比如业务所需,集群需要扩容,或者某机器永久损坏,需要从集群中剔除等等。
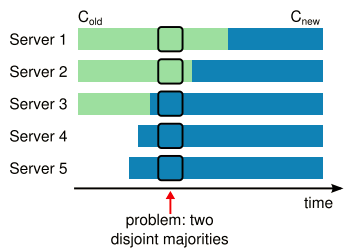
扩容最大的挑战就是保证一致性很困难,因为扩容不是原子的,有可能集群中一部分机器用老配置信息,另一部分用新配置信息,如上图所示,因此究竟多少算大多数在集群中可能存在分歧。扩容一般都分为两个阶段,有很多实现方法,比较典型的就是第一阶段,使所有旧配置信息失效,这段时间不对外提供服务;第二阶段允许新配置信息,重新对外服务。在Raft中集群第一阶段首先使集群转向一个被称作联合一致性(joint consensus)的状态;一旦这个联合一致性(有一个特殊的Cold,new entry表征)被提交,这个系统就开始向新配置迁移。joint consensus既包含老配置信息,又包含新配置信息,它的规则(Cold,new规则)如下:
- log entries复制给集群中所有机器,不管配置信息新旧
- 任何配置的server都有权利当leader
- 达成一致所需要的大多数(不管是选举还是entry提交),既要包括老配置中的一个大多数也要包括新配置机器中的一个大多数。
joint consensus允许集群配置平滑过渡而不失去安全和一致性,同时集群可正常对外服务。集群配置信息以一个特殊的entry表征,存储在log中并和其他entry语义一样。当一个leader收到扩容请求,它就创建一个Cold,new的entry,并复制给集群其它其它机器,一旦有某个follower收到此entry并追加到自己的日志中,它就使用Cold,new规则(不需要committed)。leader按照Cold,new 规则对Cold,new进行commit。如果一个leader crash了,新leader既可能是没收到Cold,new的又可能是收到的,但是这两种情况都不会出现leader用Cnew规则做决策。
一旦Cold,new被提交,就开始向新配置转换。Raft保证只有拥有Cold,new的节点才会被选举为leader。现在leader可以很安全地创建一个叫Cnew的entry,然后复制给集群中属于新配置的节点。配置信息还是节点一收到就可以用来做决策。Cnew的commit使用Cnew 规则,旧配置已经与集群无关,新配置中不存在的机器可以着手关闭,Raft通过保证不让Cold和Cnew的节点有机会同时做决策来保障安全性。配置改变示意图如下:
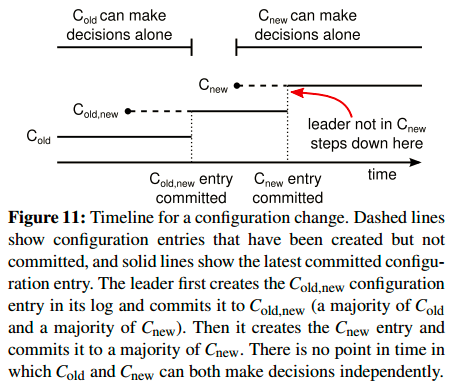
有三个要注意的点:
(1) 新server加入进集群时也许没有存储任何log entries,它们需要很长时间来追上原有机器的“进度”,为了防止集群性能出现巨大的抖动,Raft在配置改变前又引入了一个特殊的阶段,当新机器加入集群时,它们作为无投票权的节点,即leader还是会将log entries复制给它们,但是不会被当做大多数对待。一旦这些“新人”追上了其他机器的进度,动态扩容可以像上述一样执行。
(2) 当前leader也许不是集群新配置中的一份子,在这种情况下,一旦Cnew被提交,这个leader就主动退出。这意味着当Cnew提交过程中这个leader要管理一个不包括它自己的集群。这时,它在给其他节点复制log entries时不把自己计入大多数。当Cnew提交成功,这个leader的使命就光荣完成了,在这个时间点前,只有Cold的节点才会被选举为leader。
(3) 第三个问题是被移除的机器可能会影响集群服务。这些机器不会再接收到心跳信息,它们因此可能重启选举,结果是它们用一个更新的term号发起RequestVote RPCs,当前leader无奈的退化为follower。新leader(拥有新配置的)还是会被选举出来,但是那些被移除的机器还是继续超时,开启选举,导致系统可用性降低。为解决这一问题,需要有一个机制让集群中节点能够忽略这种RequestVote RPCs,相信当前leader正在正常工作。Raft使用最小超时延迟(前面说过,Raft会随机为每个节点指定一个随机的election timeout,典型的是150ms到300ms,最小超时延迟就是它们之间的最小值)来保证,如果一个节点在最小超时延迟前收到一个RequestVote RPCs,那么该节点不会提升term号,也不会为其投票。这个不会影响正常的选举,因为正常选举中都是至少等待一个最小超时延迟才开始下一次选举的。
####Raft新集群扩容方案
为了降低集群扩容的复杂性,Raft还有一个可以备选的方案。它增强了扩容的限制:一次只允许一台机器加入或移除集群。复杂的扩容可以通过一系列的单机增加或删除变向实现。
当从集群中添加或删除一台机器时,任何旧配置集群中的大多数和任何新配置集群中的大多数必然存在一个交集,如下图所示。
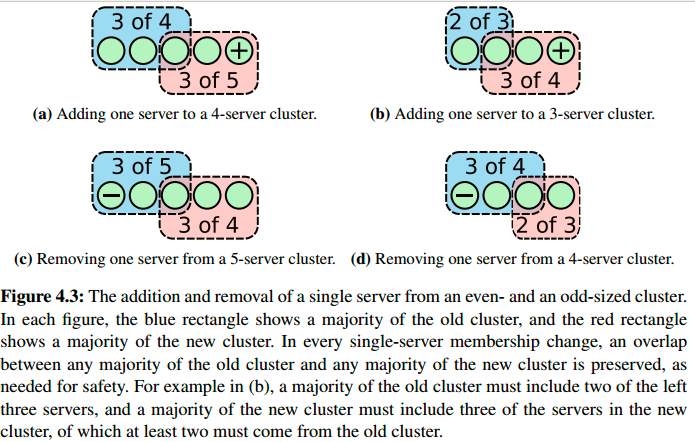
注意就是这个交集让集群不可能存在两个互相独立,没有交集的大多数群体。因此系统中不会同时存在两个leader(一个由旧配置集群选举出来,一个由新配置集群选举出来),因此扩容是安全的,集群可以直接从旧配置转向新配置。
当leader收到添加或删除一台机器的请求,它将该Cnew添加到自己的log中,然后使用一样的复制机制,把这个entry复制给属于新配置集群的所有节点。只要节点把Cnew添加进log,就马上使用新配置信息,无需等到该entry提交。leader使用Cnew规则对Cnew进行提交,一旦提交完成,扩容就宣告完成,leader就知道任何没有Cnew的节点都不可能形成一个大多数,这样的节点也不可能成为集群的leader。Cnew的提交暗示了以下三件事情:
- leader获知扩容成功完成
- 如果新配置移除一台机器,那么这台机器可以着手关闭
- 新的扩容可以开始
正如上面所讲的那样,servers永远使用log中最新的配置,不管这个配置entry是否被提交。这样leader知道一
Raft算法详解的更多相关文章
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- [转] KMP算法详解
转载自:http://www.matrix67.com/blog/archives/115 KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的K ...
- 【转】AC算法详解
原文转自:http://blog.csdn.net/joylnwang/article/details/6793192 AC算法是Alfred V.Aho(<编译原理>(龙书)的作者),和 ...
- KMP算法详解(转自中学生OI写的。。ORZ!)
KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法.KMP算法是拿来处理字符串匹配的.换句 ...
- EM算法详解
EM算法详解 1 极大似然估计 假设有如图1的X所示的抽取的n个学生某门课程的成绩,又知学生的成绩符合高斯分布f(x|μ,σ2),求学生的成绩最符合哪种高斯分布,即μ和σ2最优值是什么? 图1 学生成 ...
- Tarjan算法详解
Tarjan算法详解 今天偶然发现了这个算法,看了好久,终于明白了一些表层的知识....在这里和大家分享一下... Tarjan算法是一个求解极大强联通子图的算法,相信这些东西大家都在网络上百度过了, ...
- 安全体系(二)——RSA算法详解
本文主要讲述RSA算法使用的基本数学知识.秘钥的计算过程以及加密和解密的过程. 安全体系(零)—— 加解密算法.消息摘要.消息认证技术.数字签名与公钥证书 安全体系(一)—— DES算法详解 1.概述 ...
随机推荐
- vue新手入坑之mounted和created的区别(生命周期)
这几个月用vue框架新做了一个项目,也算是边学习边实践吧.学习中也看过一些别人的开源项目,起初对mounted和created有一些疑惑,查询相关资料发现,这和vue的生命周期有关,在此也就做一个总结 ...
- systemverilog之OOP
what is oop terminology an example class default methods for classes static attibute assigment and c ...
- $monitor用法
1.$monitor 进程同一时间有且仅有一个,若多次调用$monitor,新进程会代替以前的monitor进程. 2.$fmonitor可以同时存在任意个. 3.一般不用$monitor系统函数. ...
- python 实现计算器功能 输入字符串,输出相应结果
import re formul='1 - 2 *( (6 0- 30+(0-40/5) * (9-2* 5/3 +7 /3*99/4*2998 +10 *568/14)) - (-4*3) / (1 ...
- module_param
该宏定义在include/linux/moduleparam.h中 #define ___module_cat(a,b) __mod_ ## a ## b #define __module_cat(a ...
- 快速入门Numpy
教你十分钟学会使用numpy. 简单介绍一下numpy的话,这就是一个基于多维数组的python科学计算的核心库. 基本信息 # 一般用np作为numpy的缩写 import numpy as np ...
- TMG 模拟公司网络架构要点
1.部署的router 有且只有一个网关,指向TMG服务器 2.router 确认有默认路由,指向TMG服务器 3.TMG 只能设置一个网关,指向模拟公网关 4.TMG 要手工创建指向router的路 ...
- log4j动态日志级别调整
1. 针对root logger的设置 log4j.rootLogger=INFO, CONSOLELogger.getRootLogger().setLevel(org.apache.log4j.L ...
- ImportError: No module named ‘MySQLdb'
1.APP未注册 INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contentty ...
- Codeforces Round #305 (Div. 2) D. Mike and Feet
D. Mike and Feet time limit per test 1 second memory limit per test 256 megabytes input standard inp ...