语言模型评价指标Perplexity
在信息论中,perplexity(困惑度)用来度量一个概率分布或概率模型预测样本的好坏程度。它也可以用来比较两个概率分布或概率模型。(应该是比较两者在预测样本上的优劣)低困惑度的概率分布模型或概率模型能更好地预测样本。
困惑度越小,句子概率越大,语言模型越好。
wiki上列举了三种perplexity的计算:
1. 概率分布的perplexity
公式:
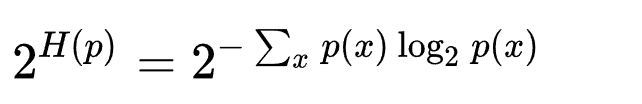
离散概率分布p的困惑度由下式给出 其中H(p) 是该分布的熵,x遍历事件空间。
随机变量X的复杂度由其所有可能的取值x定义。 一个特殊的例子是k面均匀骰子的概率分布,它的困惑度恰好是k。一个拥有k困惑度的随机变量有着和k面均匀骰子一样多的不确定性,并且可以说该随机变量有着k个困惑度的取值(k-ways perplexed)。(在有限样本空间离散随机变量的概率分布中,均匀分布有着最大的熵)
困惑度有时也被用来衡量一个预测问题的难易程度。但这个方法不总是精确的。例如:在概率分布B(1,P=0.9)中,即取得1的概率是0.9,取得0的概率是0.1。
2. 概率模型的perplexity
用一个概率模型q去估计真实概率分布p,那么可以通过测试集中的样本来定义这个概率模型的困惑度。
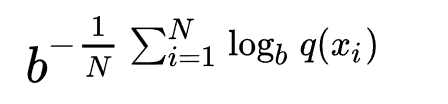

 表示我们对真实分布下样本点x出现概率的估计。比如用p(x)=n/N.
表示我们对真实分布下样本点x出现概率的估计。比如用p(x)=n/N.3. 单词的perplexity
语言模型评价指标Perplexity的更多相关文章
- LDA主题模型评估方法–Perplexity
在LDA主题模型之后,需要对模型的好坏进行评估,以此依据,判断改进的参数或者算法的建模能力. Blei先生在论文<Latent Dirichlet Allocation>实验中用的是Per ...
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- XLM论文原理解析
1. 前言 近一年来,NLP领域发展势头强劲,从ELMO到LSTM再到去年最牛叉的Google Bert,在今年年初,Facebook又推出了XLM模型,在跨语言预训练领域表现抢眼.实验结果显示XLM ...
- 0-4评价一个语言模型Evaluating Language Models:Perplexity
有了一个语言模型,就要判断这个模型的好坏. 现在假设: 我们有一些测试数据,test data.测试数据中有m个句子;s1,s2,s3-,sm 我们可以查看在某个模型下面的概率: 我们也知道,如果计算 ...
- 【NLP_Stanford课堂】语言模型2
一.如何评价语言模型的好坏 标准:比起语法不通的.不太可能出现的句子,是否为“真实”或"比较可能出现的”句子分配更高的概率 过程:先在训练数据集上训练模型的参数,然后在测试数据集上测试模型的 ...
- 语言模型kenlm的训练及使用
一.背景 近期研究了一下语言模型,同事推荐了一个比较好用的工具包kenlm,记录下使用过程. 二.使用kenlm训练 n-gram 1.工具介绍:http://kheafield.com/code/k ...
- 用python计算lda语言模型的困惑度并作图
转载请注明:电子科技大学EClab——落叶花开http://www.cnblogs.com/nlp-yekai/p/3816532.html 困惑度一般在自然语言处理中用来衡量训练出的语言模型的好坏. ...
- Multimodal —— 看图说话(Image Caption)任务的论文笔记(一)评价指标和NIC模型
看图说话(Image Caption)任务是结合CV和NLP两个领域的一种比较综合的任务,Image Caption模型的输入是一幅图像,输出是对该幅图像进行描述的一段文字.这项任务要求模型可以识别图 ...
- 学习笔记TF035:实现基于LSTM语言模型
神经结构进步.GPU深度学习训练效率突破.RNN,时间序列数据有效,每个神经元通过内部组件保存输入信息. 卷积神经网络,图像分类,无法对视频每帧图像发生事情关联分析,无法利用前帧图像信息.RNN最大特 ...
随机推荐
- postman 跟restsharp 模拟请求http
https://github.com/restsharp/RestSharp postman 生成的访问代码: 好用! Features Assemblies for .NET 4.5.2 and . ...
- mysql:where和having的区别
where在查询数据库结果返回之前对查询条件进行约束,就是结果返回之前起作用,而having是查询数据库,已经得到返回的结果了,再对结果进行过滤.(结果返回前,结果返回后) where条件不能使用聚合 ...
- 小程序开发之后台mybatis逆向工程(二)
上一节搭建好了SSM后台框架,这一节将根据表结构创建实体及映射文件以及mapper接口.如果表过多,会很麻烦,所以mybatis提供了逆向工程来解决这个问题. 上一节 SSM搭建后台管理系统 逆向工程 ...
- virtualbox使用xshell配置以及共享文件夹设置
1.virtualbox NAT网络配置后,host xshell访问 设置映射 登陆: ssh 127.0.0.1 2.virtualbox共享文件(host---->guest) 1.安装增 ...
- Binary Stirling Numbers
http://poj.org/problem?id=1430 题目: 求 第二类 斯特林数 的 奇偶性 即 求 s2 ( n , m ) % 2 : 题解: https://blog.csdn.ne ...
- POJ 2109 Power of Cryptography 数学题 double和float精度和范围
Power of Cryptography Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 21354 Accepted: 107 ...
- TensorFlow使用记录 (七): BN 层及 Dropout 层的使用
参考:tensorflow中的batch_norm以及tf.control_dependencies和tf.GraphKeys.UPDATE_OPS的探究 1. Batch Normalization ...
- Mysql模拟故障恢复案例过程
一.数据库全备,全备脚本如下: [root@leader script]# cat bak_all.sh #!/bin/bash#Date: 2019-12-08#Author: chan#Mail: ...
- IDEA找回Run Dashboard
特别提示:本人博客部分有参考网络其他博客,但均是本人亲手编写过并验证通过.如发现博客有错误,请及时提出以免误导其他人,谢谢!欢迎转载,但记得标明文章出处:http://www.cnblogs.com/ ...
- SRS之RTMP handshake
1. SrsRtmpServer::handshake 位于 srs_rtmp_stack.cpp. int SrsRtmpServer::handshake() { int ret = ERROR_ ...