26.Spark创建RDD集合
打开eclipse创建maven项目

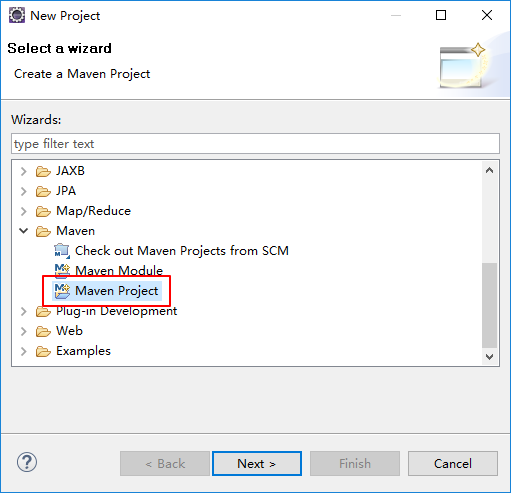
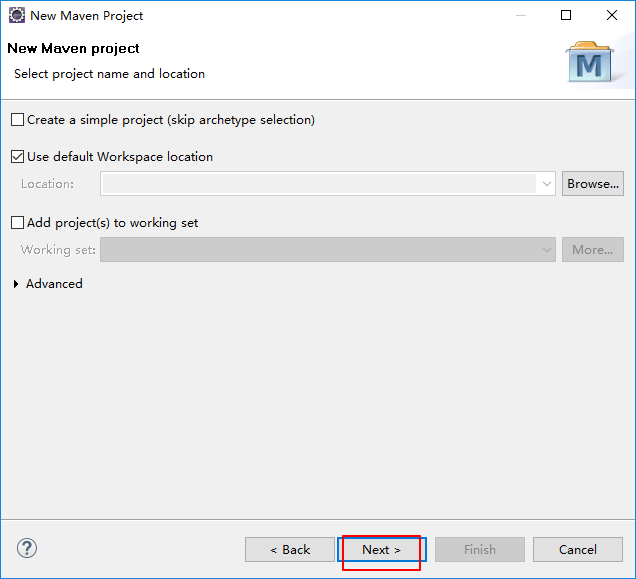
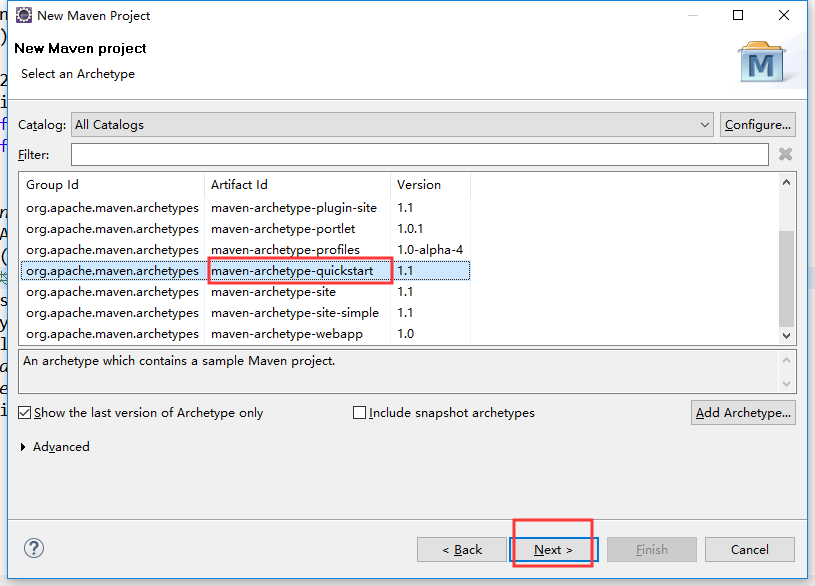
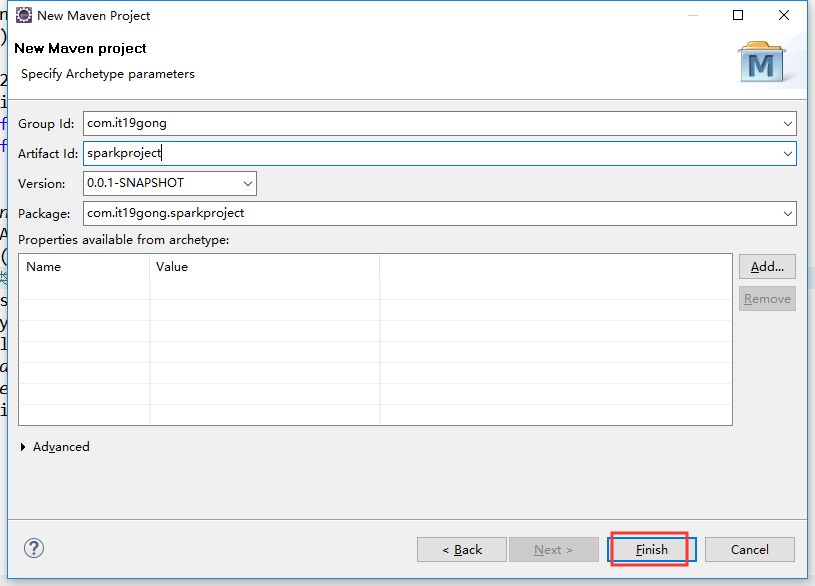
pom.xml文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion> <groupId>com.it19gong</groupId>
<artifactId>sparkproject</artifactId>
<version>0.0.-SNAPSHOT</version>
<packaging>jar</packaging> <name>sparkproject</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-</project.build.sourceEncoding>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.</artifactId>
<version>1.5.</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.</artifactId>
<version>1.5.</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.</artifactId>
<version>1.5.</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.</artifactId>
<version>1.5.</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.4.</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka_2.</artifactId>
<version>1.5.</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.</version>
</dependency> <dependency>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-core</artifactId>
<version>3.2.</version>
</dependency> <dependency>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-rdbms</artifactId>
<version>4.1.</version>
</dependency> <dependency>
<groupId>org.datanucleus</groupId>
<artifactId>datanucleus-api-jdo</artifactId>
<version>3.2.</version>
</dependency> </dependencies> <build>
<sourceDirectory>src/main/java</sourceDirectory>
<testSourceDirectory>src/main/test</testSourceDirectory> <plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass></mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin> <plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>1.2.</version>
<executions>
<execution>
<goals>
<goal>exec</goal>
</goals>
</execution>
</executions>
<configuration>
<executable>java</executable>
<includeProjectDependencies>true</includeProjectDependencies>
<includePluginDependencies>false</includePluginDependencies>
<classpathScope>compile</classpathScope>
<mainClass>com.it19gong.sparkproject.App</mainClass>
</configuration>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin> </plugins>
</build> </project>
创建一个WordCountLocal.java文件
package com.it19gong.sparkproject; import java.util.Arrays; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class WordCountLocal { public static void main(String[] args) {
//1.设置本地开发
SparkConf conf = new SparkConf().setAppName("WordCountLocal").setMaster("local"); //2.创建spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
//3.读取文件
JavaRDD<String> lines = sc.textFile("E://Mycode//dianshixiangmu//sparkproject//data//spark.txt");
//4.开始进行计算
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
} }); JavaPairRDD<String, Integer> pairs = words.mapToPair(
new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, );
} }); JavaPairRDD<String, Integer> wordCounts = pairs.reduceByKey( new Function2<Integer, Integer, Integer>() { private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
} }); wordCounts.foreach(new VoidFunction<Tuple2<String,Integer>>() { private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1 + " appeared " + wordCount._2 + " times.");
} }); sc.close(); }
}
运行一下
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
// :: INFO SparkContext: Running Spark version 1.5.
// :: INFO SecurityManager: Changing view acls to: Brave
// :: INFO SecurityManager: Changing modify acls to: Brave
// :: INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Brave); users with modify permissions: Set(Brave)
// :: INFO Slf4jLogger: Slf4jLogger started
// :: INFO Remoting: Starting remoting
// :: INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@10.0.75.1:55718]
// :: INFO Utils: Successfully started service 'sparkDriver' on port .
// :: INFO SparkEnv: Registering MapOutputTracker
// :: INFO SparkEnv: Registering BlockManagerMaster
// :: INFO DiskBlockManager: Created local directory at C:\Users\Brave\AppData\Local\Temp\blockmgr--9dcc-40bd-86b9-9056cb077e9e
// :: INFO MemoryStore: MemoryStore started with capacity 2.9 GB
// :: INFO HttpFileServer: HTTP File server directory is C:\Users\Brave\AppData\Local\Temp\spark-7e77199e-97b8-4ad1-850d-45a4b9dbb981\httpd-2e225558-a380-410a-83ab-6d4353461237
// :: INFO HttpServer: Starting HTTP Server
// :: INFO Utils: Successfully started service 'HTTP file server' on port .
// :: INFO SparkEnv: Registering OutputCommitCoordinator
// :: INFO Utils: Successfully started service 'SparkUI' on port .
// :: INFO SparkUI: Started SparkUI at http://10.0.75.1:4040
// :: WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
// :: INFO Executor: Starting executor ID driver on host localhost
// :: INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port .
// :: INFO NettyBlockTransferService: Server created on
// :: INFO BlockManagerMaster: Trying to register BlockManager
// :: INFO BlockManagerMasterEndpoint: Registering block manager localhost: with 2.9 GB RAM, BlockManagerId(driver, localhost, )
// :: INFO BlockManagerMaster: Registered BlockManager
// :: INFO MemoryStore: ensureFreeSpace() called with curMem=, maxMem=
// :: INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 117.3 KB, free 2.9 GB)
// :: INFO MemoryStore: ensureFreeSpace() called with curMem=, maxMem=
// :: INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 12.4 KB, free 2.9 GB)
// :: INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost: (size: 12.4 KB, free: 2.9 GB)
// :: INFO SparkContext: Created broadcast from textFile at WordCountLocal.java:
// :: WARN : Your hostname, DESKTOP-76BE8V4 resolves to a loopback/non-reachable address: fe80::::597b:a8f9::f5d2%eth10, but we couldn't find any external IP address!
// :: INFO FileInputFormat: Total input paths to process :
// :: INFO SparkContext: Starting job: foreach at WordCountLocal.java:
// :: INFO DAGScheduler: Registering RDD (mapToPair at WordCountLocal.java:)
// :: INFO DAGScheduler: Got job (foreach at WordCountLocal.java:) with output partitions
// :: INFO DAGScheduler: Final stage: ResultStage (foreach at WordCountLocal.java:)
// :: INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage )
// :: INFO DAGScheduler: Missing parents: List(ShuffleMapStage )
// :: INFO DAGScheduler: Submitting ShuffleMapStage (MapPartitionsRDD[] at mapToPair at WordCountLocal.java:), which has no missing parents
// :: INFO MemoryStore: ensureFreeSpace() called with curMem=, maxMem=
// :: INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.7 KB, free 2.9 GB)
// :: INFO MemoryStore: ensureFreeSpace() called with curMem=, maxMem=
// :: INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.6 KB, free 2.9 GB)
// :: INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost: (size: 2.6 KB, free: 2.9 GB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ShuffleMapStage (MapPartitionsRDD[] at mapToPair at WordCountLocal.java:)
// :: INFO TaskSchedulerImpl: Adding task set 0.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID , localhost, PROCESS_LOCAL, bytes)
// :: INFO Executor: Running task 0.0 in stage 0.0 (TID )
// :: INFO HadoopRDD: Input split: file:/E:/Mycode/dianshixiangmu/sparkproject/data/spark.txt:+
// :: INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
// :: INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
// :: INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
// :: INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
// :: INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
// :: INFO Executor: Finished task 0.0 in stage 0.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID ) in ms on localhost (/)
// :: INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: ShuffleMapStage (mapToPair at WordCountLocal.java:) finished in 0.094 s
// :: INFO DAGScheduler: looking for newly runnable stages
// :: INFO DAGScheduler: running: Set()
// :: INFO DAGScheduler: waiting: Set(ResultStage )
// :: INFO DAGScheduler: failed: Set()
// :: INFO DAGScheduler: Missing parents for ResultStage : List()
// :: INFO DAGScheduler: Submitting ResultStage (ShuffledRDD[] at reduceByKey at WordCountLocal.java:), which is now runnable
// :: INFO MemoryStore: ensureFreeSpace() called with curMem=, maxMem=
// :: INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 2.4 KB, free 2.9 GB)
// :: INFO MemoryStore: ensureFreeSpace() called with curMem=, maxMem=
// :: INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1509.0 B, free 2.9 GB)
// :: INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost: (size: 1509.0 B, free: 2.9 GB)
// :: INFO SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO DAGScheduler: Submitting missing tasks from ResultStage (ShuffledRDD[] at reduceByKey at WordCountLocal.java:)
// :: INFO TaskSchedulerImpl: Adding task set 1.0 with tasks
// :: INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID , localhost, PROCESS_LOCAL, bytes)
// :: INFO Executor: Running task 0.0 in stage 1.0 (TID )
// :: INFO ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO ShuffleBlockFetcherIterator: Started remote fetches in ms
jkjf appeared times.
spark appeared times.
hive appeared times.
klsdjflk appeared times.
hadoop appeared times.
flume appeared times.
appeared times.
dshfjdslfjk appeared times.
sdfjjk appeared times.
djfk appeared times.
hava appeared times.
java appeared times.
sdjfk appeared times.
sdfjs appeared times.
// :: INFO Executor: Finished task 0.0 in stage 1.0 (TID ). bytes result sent to driver
// :: INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID ) in ms on localhost (/)
// :: INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
// :: INFO DAGScheduler: ResultStage (foreach at WordCountLocal.java:) finished in 0.024 s
// :: INFO DAGScheduler: Job finished: foreach at WordCountLocal.java:, took 0.189574 s
// :: INFO SparkUI: Stopped Spark web UI at http://10.0.75.1:4040
// :: INFO DAGScheduler: Stopping DAGScheduler
// :: INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
// :: INFO MemoryStore: MemoryStore cleared
// :: INFO BlockManager: BlockManager stopped
// :: INFO BlockManagerMaster: BlockManagerMaster stopped
// :: INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
// :: INFO SparkContext: Successfully stopped SparkContext
// :: INFO ShutdownHookManager: Shutdown hook called
// :: INFO ShutdownHookManager: Deleting directory C:\Users\Brave\AppData\Local\Temp\spark-7e77199e-97b8-4ad1-850d-45a4b9dbb981
集群执行wordcount程序
创建一个WordCountCluster.java文件
// 如果要在spark集群上运行,需要修改的,只有两个地方
// 第一,将SparkConf的setMaster()方法给删掉,默认它自己会去连接
// 第二,我们针对的不是本地文件了,修改为hadoop hdfs上的真正的存储大数据的文件
SparkConf conf = new SparkConf().setAppName("WordCountCluster");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile("hdfs://node1:9000/spark.txt");
package com.it19gong.sparkproject; import java.util.Arrays; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction; import scala.Tuple2; public class WordCountCluster { public static void main(String[] args) {
//1.设置本地开发
SparkConf conf = new SparkConf().setAppName("WordCountCluster"); //2.创建spark上下文
JavaSparkContext sc = new JavaSparkContext(conf);
//3.读取文件
JavaRDD<String> lines = sc.textFile("hdfs://node1/spark.txt");
//4.开始进行计算
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() { private static final long serialVersionUID = 1L; @Override
public Iterable<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
} }); JavaPairRDD<String, Integer> pairs = words.mapToPair(
new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L; @Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, );
} }); JavaPairRDD<String, Integer> wordCounts = pairs.reduceByKey( new Function2<Integer, Integer, Integer>() { private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
} }); wordCounts.foreach(new VoidFunction<Tuple2<String,Integer>>() { private static final long serialVersionUID = 1L; @Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System.out.println(wordCount._1 + " appeared " + wordCount._2 + " times.");
} }); sc.close(); }
}
对工程进行打包
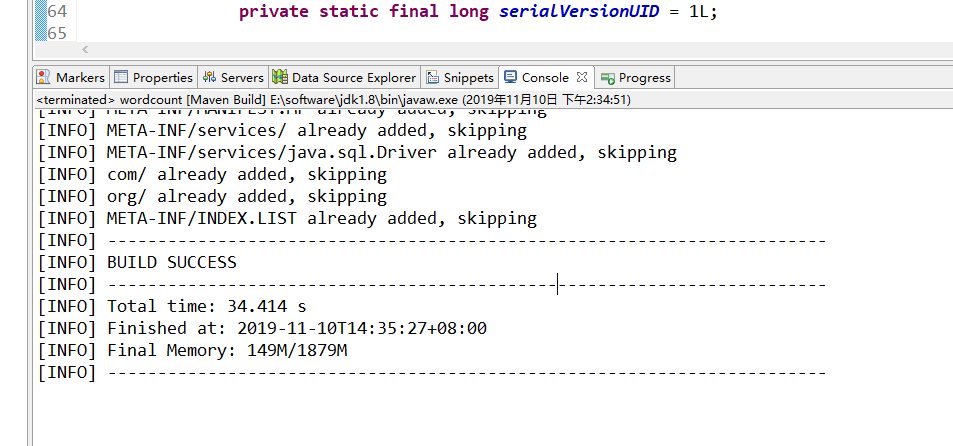
把spark.txt文件上传到集群

同时把文件上传到hdfs上

把刚刚打好的架包上传到集群
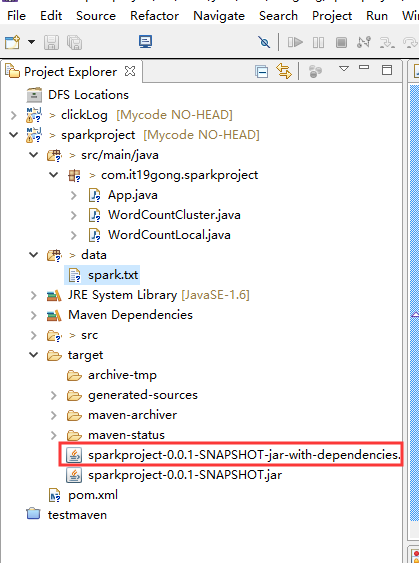
修改一下包的名字

现在我们编写一个脚本
Wordcount.sh
/opt/modules/spark-1.5.1-bin-hadoop2.6/bin/spark-submit --class com.it19gong.sparkproject.WordCountCluster --num-executors --driver-memory 100m --executor-memory 100m --executor-cores /home/hadoop/sparkproject.jar

启动spark
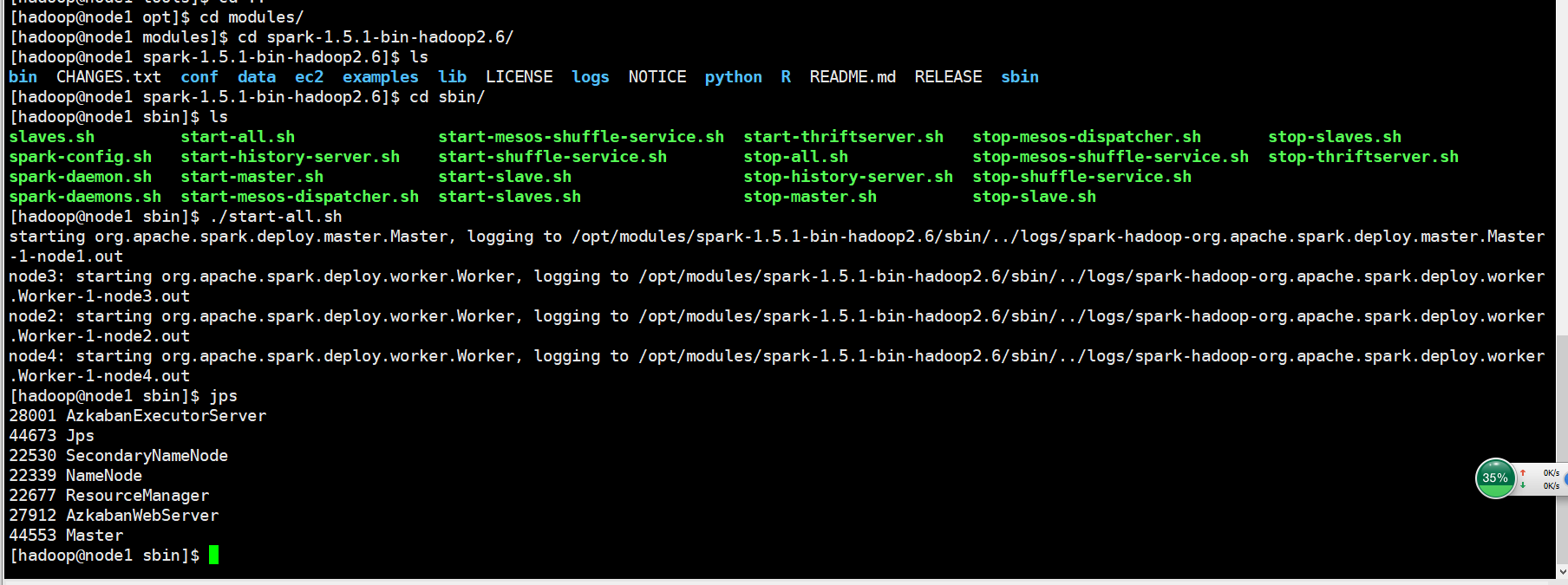
执行脚本
[hadoop@node1 ~]$ ./Wordcount.sh
// :: INFO spark.SparkContext: Running Spark version 1.5.
// :: WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
// :: INFO spark.SecurityManager: Changing view acls to: hadoop
// :: INFO spark.SecurityManager: Changing modify acls to: hadoop
// :: INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
// :: INFO slf4j.Slf4jLogger: Slf4jLogger started
// :: INFO Remoting: Starting remoting
// :: INFO util.Utils: Successfully started service 'sparkDriver' on port .
// :: INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@192.168.86.131:42358]
// :: INFO spark.SparkEnv: Registering MapOutputTracker
// :: INFO spark.SparkEnv: Registering BlockManagerMaster
// :: INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-2e4d079e-a368--93e6-de99c948e0d2
// :: INFO storage.MemoryStore: MemoryStore started with capacity 52.2 MB
// :: INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-b3327381---913a-0b09e354f0e1/httpd-1cd444b4-38c9-4cec-9e16-66d0d2c1117c
// :: INFO spark.HttpServer: Starting HTTP Server
// :: INFO server.Server: jetty-.y.z-SNAPSHOT
// :: INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:
// :: INFO util.Utils: Successfully started service 'HTTP file server' on port .
// :: INFO spark.SparkEnv: Registering OutputCommitCoordinator
// :: INFO server.Server: jetty-.y.z-SNAPSHOT
// :: INFO server.AbstractConnector: Started SelectChannelConnector@0.0.0.0:
// :: INFO util.Utils: Successfully started service 'SparkUI' on port .
// :: INFO ui.SparkUI: Started SparkUI at http://192.168.86.131:4040
// :: INFO spark.SparkContext: Added JAR file:/home/hadoop/sparkproject.jar at http://192.168.86.131:40646/jars/sparkproject.jar with timestamp 1573371224734
// :: WARN metrics.MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
// :: INFO executor.Executor: Starting executor ID driver on host localhost
// :: INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port .
// :: INFO netty.NettyBlockTransferService: Server created on
// :: INFO storage.BlockManagerMaster: Trying to register BlockManager
// :: INFO storage.BlockManagerMasterEndpoint: Registering block manager localhost: with 52.2 MB RAM, BlockManagerId(driver, localhost, )
// :: INFO storage.BlockManagerMaster: Registered BlockManager
// :: INFO storage.MemoryStore: ensureFreeSpace() called with curMem=, maxMem=
// :: INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 127.4 KB, free 52.1 MB)
// :: INFO storage.MemoryStore: ensureFreeSpace() called with curMem=, maxMem=
// :: INFO storage.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 14.1 KB, free 52.1 MB)
// :: INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost: (size: 14.1 KB, free: 52.2 MB)
// :: INFO spark.SparkContext: Created broadcast from textFile at WordCountCluster.java:
// :: INFO mapred.FileInputFormat: Total input paths to process :
// :: INFO spark.SparkContext: Starting job: foreach at WordCountCluster.java:
// :: INFO scheduler.DAGScheduler: Registering RDD (mapToPair at WordCountCluster.java:)
// :: INFO scheduler.DAGScheduler: Got job (foreach at WordCountCluster.java:) with output partitions
// :: INFO scheduler.DAGScheduler: Final stage: ResultStage (foreach at WordCountCluster.java:)
// :: INFO scheduler.DAGScheduler: Parents of final stage: List(ShuffleMapStage )
// :: INFO scheduler.DAGScheduler: Missing parents: List(ShuffleMapStage )
// :: INFO scheduler.DAGScheduler: Submitting ShuffleMapStage (MapPartitionsRDD[] at mapToPair at WordCountCluster.java:), which has no missing parents
// :: INFO storage.MemoryStore: ensureFreeSpace() called with curMem=, maxMem=
// :: INFO storage.MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.7 KB, free 52.1 MB)
// :: INFO storage.MemoryStore: ensureFreeSpace() called with curMem=, maxMem=
// :: INFO storage.MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.6 KB, free 52.1 MB)
// :: INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost: (size: 2.6 KB, free: 52.2 MB)
// :: INFO spark.SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO scheduler.DAGScheduler: Submitting missing tasks from ShuffleMapStage (MapPartitionsRDD[] at mapToPair at WordCountCluster.java:)
// :: INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with tasks
// :: INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID , localhost, ANY, bytes)
// :: INFO executor.Executor: Running task 0.0 in stage 0.0 (TID )
// :: INFO executor.Executor: Fetching http://192.168.86.131:40646/jars/sparkproject.jar with timestamp 1573371224734
// :: INFO util.Utils: Fetching http://192.168.86.131:40646/jars/sparkproject.jar to /tmp/spark-b3327381-3897-4200-913a-0b09e354f0e1/userFiles-5ed25560-5fd3-43ce-8f5f-d5017b6e5c4e/fetchFileTemp5320647246797663342.tmp
// :: INFO executor.Executor: Adding file:/tmp/spark-b3327381---913a-0b09e354f0e1/userFiles-5ed25560-5fd3-43ce-8f5f-d5017b6e5c4e/sparkproject.jar to class loader
// :: INFO rdd.HadoopRDD: Input split: hdfs://node1/spark.txt:0+159
// :: INFO Configuration.deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
// :: INFO Configuration.deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
// :: INFO Configuration.deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
// :: INFO Configuration.deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
// :: INFO Configuration.deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
// :: INFO executor.Executor: Finished task 0.0 in stage 0.0 (TID ). bytes result sent to driver
// :: INFO scheduler.DAGScheduler: ShuffleMapStage (mapToPair at WordCountCluster.java:) finished in 3.353 s
// :: INFO scheduler.DAGScheduler: looking for newly runnable stages
// :: INFO scheduler.DAGScheduler: running: Set()
// :: INFO scheduler.DAGScheduler: waiting: Set(ResultStage )
// :: INFO scheduler.DAGScheduler: failed: Set()
// :: INFO scheduler.DAGScheduler: Missing parents for ResultStage : List()
// :: INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID ) in ms on localhost (/)
// :: INFO scheduler.DAGScheduler: Submitting ResultStage (ShuffledRDD[] at reduceByKey at WordCountCluster.java:), which is now runnable
// :: INFO storage.MemoryStore: ensureFreeSpace() called with curMem=, maxMem=
// :: INFO storage.MemoryStore: Block broadcast_2 stored as values in memory (estimated size 2.4 KB, free 52.1 MB)
// :: INFO storage.MemoryStore: ensureFreeSpace() called with curMem=, maxMem=
// :: INFO storage.MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1511.0 B, free 52.1 MB)
// :: INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost: (size: 1511.0 B, free: 52.2 MB)
// :: INFO spark.SparkContext: Created broadcast from broadcast at DAGScheduler.scala:
// :: INFO scheduler.DAGScheduler: Submitting missing tasks from ResultStage (ShuffledRDD[] at reduceByKey at WordCountCluster.java:)
// :: INFO scheduler.TaskSchedulerImpl: Adding task set 1.0 with tasks
// :: INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
// :: INFO scheduler.TaskSetManager: Starting task 0.0 in stage 1.0 (TID , localhost, PROCESS_LOCAL, bytes)
// :: INFO executor.Executor: Running task 0.0 in stage 1.0 (TID )
// :: INFO storage.ShuffleBlockFetcherIterator: Getting non-empty blocks out of blocks
// :: INFO storage.ShuffleBlockFetcherIterator: Started remote fetches in ms
jkjf appeared times.
spark appeared times.
hive appeared times.
klsdjflk appeared times.
hadoop appeared times.
flume appeared times.
appeared times.
dshfjdslfjk appeared times.
sdfjjk appeared times.
djfk appeared times.
hava appeared times.
java appeared times.
sdjfk appeared times.
sdfjs appeared times.
// :: INFO executor.Executor: Finished task 0.0 in stage 1.0 (TID ). bytes result sent to driver
// :: INFO scheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID ) in ms on localhost (/)
// :: INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
// :: INFO scheduler.DAGScheduler: ResultStage (foreach at WordCountCluster.java:) finished in 0.340 s
// :: INFO scheduler.DAGScheduler: Job finished: foreach at WordCountCluster.java:, took 4.028079 s
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/metrics/json,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/kill,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/api,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/static,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump/json,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/json,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment/json,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd/json,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/json,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool/json,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/json,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/json,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job/json,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/json,null}
// :: INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs,null}
// :: INFO ui.SparkUI: Stopped Spark web UI at http://192.168.86.131:4040
// :: INFO scheduler.DAGScheduler: Stopping DAGScheduler
// :: INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
// :: INFO storage.MemoryStore: MemoryStore cleared
// :: INFO storage.BlockManager: BlockManager stopped
// :: INFO storage.BlockManagerMaster: BlockManagerMaster stopped
// :: INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
// :: INFO spark.SparkContext: Successfully stopped SparkContext
// :: INFO remote.RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
// :: INFO remote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
// :: INFO util.ShutdownHookManager: Shutdown hook called
// :: INFO util.ShutdownHookManager: Deleting directory /tmp/spark-b3327381---913a-0b09e354f0e1
[hadoop@node1 ~]$ ls
创建RDD(集合,本地文件,HDFS文件)
进行Spark核心编程时,首先要做的第一件事,就是创建一个初始的RDD。该RDD中,通常就代表和包含了Spark应用程序的输入源数据。
然后在创建了初始的RDD之后,才可以通过Spark Core提供的transformation算子,对该RDD进行转换,来获取其他的RDD。
Spark Core提供了三种创建RDD的方式,包括:使用程序中的集合创建RDD;使用本地文件创建RDD;使用HDFS文件创建RDD。
个人经验认为:
1、使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造测试数据,来测试后面的spark应用的流程。
2、使用本地文件创建RDD,主要用于临时性地处理一些存储了大量数据的文件。
3、使用HDFS文件创建RDD,应该是最常用的生产环境处理方式,主要可以针对HDFS上存储的大数据,进行离线批处理操作。
并行化集合创建RDD
如果要通过并行化集合来创建RDD,需要针对程序中的集合,调用SparkContext的parallelize()方法。Spark会将集合中的数据拷贝到集群上去,形成一个分布式的数据集合,
也就是一个RDD。相当于是,集合中的部分数据会到一个节点上,而另一部分数据会到其他节点上。然后就可以用并行的方式来操作这个分布式数据集合,即RDD。
26.Spark创建RDD集合的更多相关文章
- Spark练习之创建RDD(集合、本地文件),RDD持久化及RDD持久化策略
Spark练习之创建RDD(集合.本地文件) 一.创建RDD 二.并行化集合创建RDD 2.1 Java并行创建RDD--计算1-10的累加和 2.2 Scala并行创建RDD--计算1-10的累加和 ...
- Spark核心编程---创建RDD
创建RDD: 1:使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造测试数据,来测试后面的spark应用流程. 2:使用本地文件创建RDD,主要用于临时性地处 ...
- Spark核心RDD、什么是RDD、RDD的属性、创建RDD、RDD的依赖以及缓存、
1:什么是Spark的RDD??? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
- 02、创建RDD(集合、本地文件、HDFS文件)
Spark Core提供了三种创建RDD的方式,包括:使用程序中的集合创建RDD:使用本地文件创建RDD:使用HDFS文件创建RDD. 1.并行化集合 如果要通过并行化集合来创建RDD,需要针对程序中 ...
- 【spark】RDD创建
首先我们要建立 sparkconf 配置文件,然后通过配置文件来建立sparkcontext. import org.apache.spark._ object MyRdd { def main(ar ...
- Spark RDD概念学习系列之如何创建RDD
不多说,直接上干货! 创建RDD 方式一:从集合创建RDD (1)makeRDD (2)Parallelize 注意:makeRDD可以指定每个分区perferredLocations参数,而para ...
- 5、创建RDD(集合、本地文件、HDFS文件)
一.创建RDD 1.创建RDD 进行Spark核心编程时,首先要做的第一件事,就是创建一个初始的RDD.该RDD中,通常就代表和包含了Spark应用程序的输入源数据.然后在创建了初始的RDD之后,才可 ...
- 大数据学习(26)—— Spark之RDD
做大数据一定要有一个概念,需要处理的数据量非常大,少则几十T,多则上百P,全部放内存是不可能的,会OOM,必须要用迭代器一条一条处理. RDD叫做弹性分布式数据集,是早期Spark最核心的概念,是一种 ...
- 大数据学习day19-----spark02-------0 零碎知识点(分区,分区和分区器的区别) 1. RDD的使用(RDD的概念,特点,创建rdd的方式以及常见rdd的算子) 2.Spark中的一些重要概念
0. 零碎概念 (1) 这个有点疑惑,有可能是错误的. (2) 此处就算地址写错了也不会报错,因为此操作只是读取数据的操作(元数据),表示从此地址读取数据但并没有进行读取数据的操作 (3)分区(有时间 ...
随机推荐
- 对拍——>bat
为了凸显对拍滴重要性.就拿来当置顶啦! ——本来是那样想的 ---------------------------------------------------------------------- ...
- CSP考前总结
10.2 考试: 1.数位DP 或者找规律 2.SB题,扫一遍找最大最小即可 3.莫比乌斯反演 出题人相出个数论和数据结构的综合题,但是找不到NOIP级别的,没办法只能忍痛割爱出个莫比乌斯,话说回来, ...
- 判断List<E>内是否有重复对象
主要用到Java 8的Stream类 long distinctedSize = list.stream().distinct().count(); boolean hasRepeat = list. ...
- java生成临时文件夹和删除临时文件夹
为了不生成同名的文件夹 String s = UUID.randomUUID().toString(); String filepath = ServletActionContext.getServl ...
- 在OpenFOAM中做用户自定义库——编译library【转载】
转载自:http://openfoam.blog.sohu.com/22041538.html OpenFOAM自己提供的标准类都是以库的形式提供的,并且利用头文件给出了库的应用接口.这样一来,用户的 ...
- 如何在OpenFOAM中增加边界条件【翻译】
注:如有翻译不妥,还请见谅 翻译自:http://openfoamwiki.net/index.php/HowTo_Adding_a_new_boundary_condition 首先请看:http: ...
- sqlmap环境搭建
1.安装Python2.7.12 1.1.下载Python2.7.12地址:https://www.python.org/downloads/ 1.2.环境变量配置Python2.7.11 1.3.验 ...
- Linux中touch命令使用(创建文件)
touch命令有两个功能: 1.用于把已存在文件的时间标签更新为系统当前的时间(默认方式),它们的数据将原封不动地保留下来: 2.用来创建新的空文件. 语法 touch(选项)(参数) 选项 -a:或 ...
- 通过phpMyAdmin优化mysql 数据库可能存在的问题
通过phpMyAdmin优化mysql 数据库可能存在的问题 文章来源:外星人来地球 欢迎关注,有问题一起学习欢迎留言.评论
- IO操作之BIO、NIO、AIO
一.BIO Blocking IO: 同步阻塞的编程方式. BIO编程方式通常是在JDK1.4版本之前常用的编程方式.编程实现过程为:首先在服务端启动一个ServerSocket来监听网络请求,客户端 ...