分布式缓存 - hash环/一致性hash
一 引言
当前memcached,redis这类分布式kv缓存已经非常普遍。我们知道memcached的分布式其实是一种"伪分布式",也就是它的服务器节点之间其实是无关联的,之间没有网络拓扑关系,由客户端来决定一个key要存放在哪台机器。
具体来讲,假设我们有多台memcached服务器,编号分别为m0, m1, m2.. 对于一个key,由客户端来决定存放到哪台机器,最简单的办法就是key % N, 其中N是机器的总数
但是有一个问题,一旦机器数增加或减少,N发生变化,key去mod新旧N得到的机器编号大概率不相等,那么之前存放的数据就全部无效了。
二 hash环
基于上面的问题,提出了hash环的概念。hash环的过程有两次hash
(1) 把所有的机器编号hash到这个环上
(2) 把key也hash到这个环上,然后在这个环上进行匹配,看这个key和哪台机器匹配
具体过程是这样: 假定有一个hash函数,其值空间为(0 ~ 2^32-1)。也就是说,其hash值是个32位无整型数字,这些数字组成一个环。首先对机器进行hash(比如根据机器ip),算出每台机器在这个环上的位置; z再对key进行hash,算出该key在环上的位置,然后从这个位置往前走,遇到的第一台机器就是该key对应的机器,就把该(key, value)存储到该机器上,如下图所示。
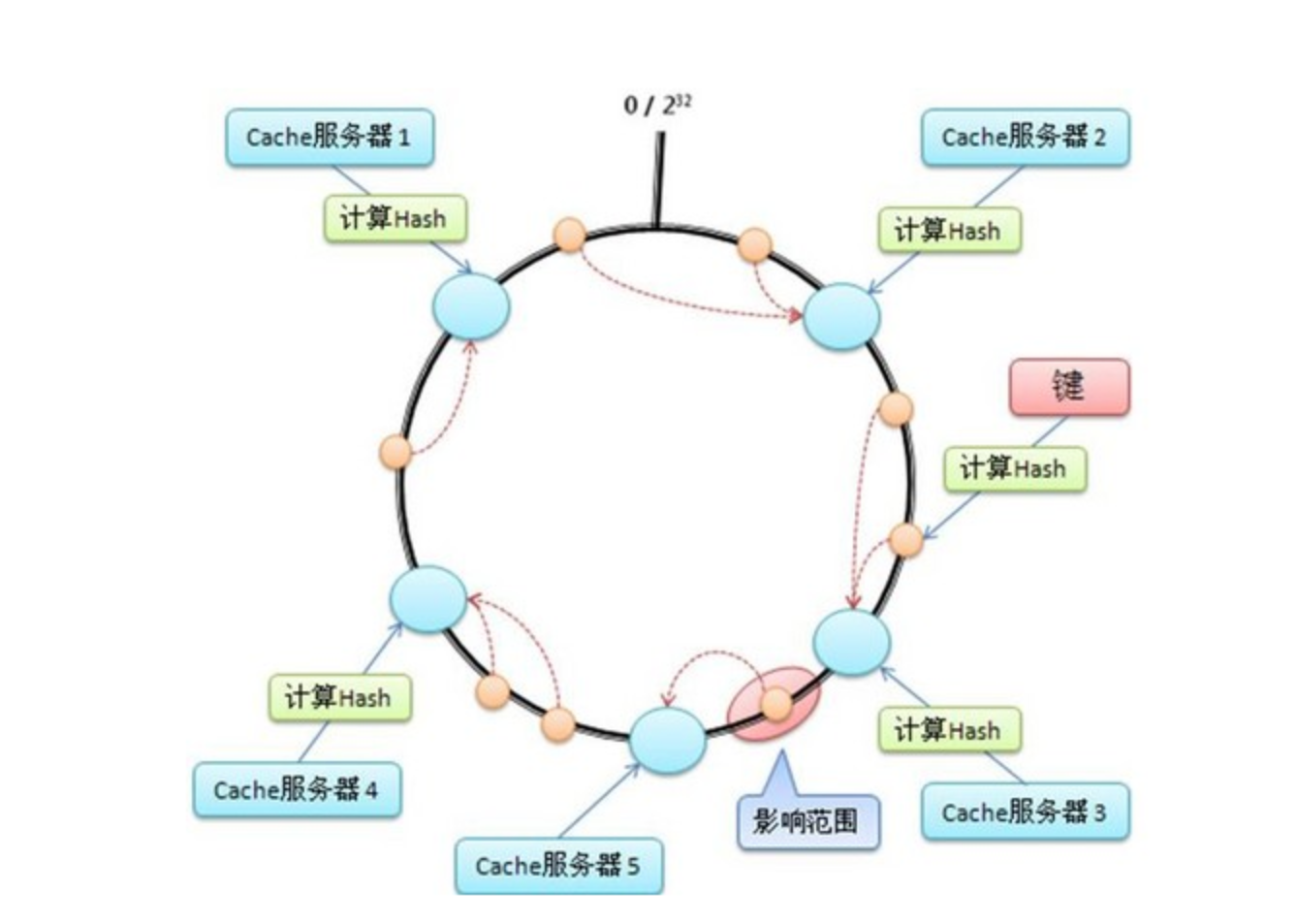
首先计算出每台cache服务器在环上的位置(图中浅蓝色的大圆圈),然后每来一个key计算出value填到环上的位置(图中橙色的小圆圈),然后顺时针走,遇到的第一个机器,就是要存储的机器
这里的关键点是:当机器数N变化时,其他机器在环上的位置并不会发生改变。这样只有增加/减少的那台机器附近的数据会失效,其他机器上的数据还是有效的。
三 数据倾斜问题
当机器不很多时,很可能出现几台机器在环上面贴的很近,分布很不均匀。这将会导致大部门数据集中在某几台机器上。
为了解决这个问题,可以引入"虚拟机器"的概念,也就是说,一台机器需要在环上映射出多个位置。比如我们用机器的ip来hash,那么我们可以在ip后面加几个编号,形如ip_1, ip_2, ip_3... 这样就实现了一台物理机器映射出了多个虚拟机器的编号。
数据首先映射到"虚拟机器"上,再从"虚拟机器"映射到物理机器上。因为虚拟机器可以很多,在环上均匀分布,从而保证数据相对均匀地分布在物理机器上。
四 zk的引入
上面我们提到了服务器的机器数N的变化,那么如何通知到客户端呢
一种笨方法就是手动,当机器数N变化,重新配置客户端,重启客户端。
另外一种,引入zk,服务器的节点列表注册到zk上面,客户端监听zk。发现节点数发生变化,自动更新自己的配置。
当然不用zk用一个其他的中心节点也可以,只要能实现这种更改的通知即可(也即分布式服务协调)
分布式缓存 - hash环/一致性hash的更多相关文章
- 分布式缓存--系列1 -- Hash环/一致性Hash原理
当前,Memcached.Redis这类分布式kv缓存已经非常普遍.从本篇开始,本系列将分析分布式缓存相关的原理.使用策略和最佳实践. 我们知道Memcached的分布式其实是一种“伪分布式”,也就是 ...
- Hash环/一致性Hash原理
当前,Memcached.Redis这类分布式kv缓存已经非常普遍.从本篇开始,本系列将分析分布式缓存相关的原理.使用策略和最佳实践. 我们知道Memcached的分布式其实是一种“伪分布式”,也就是 ...
- 搞懂分布式技术11:分布式session解决方案与一致性hash
搞懂分布式技术11:分布式session解决方案与一致性hash session一致性架构设计实践 原创: 58沈剑 架构师之路 2017-05-18 一.缘起 什么是session? 服务器为每个用 ...
- 分方式缓存常用的一致性hash是什么原理
分方式缓存常用的一致性hash是什么原理 一致性hash是用来解决什么问题的?先看一个场景有n个cache服务器,一个对象object映射到哪个cache上呢?可以采用通用方法计算object的has ...
- hash·余数hash和一致性hash
网站的伸缩性架构中,分布式的设计是现在的基本应用. 在memcached的分布式架构中,key-value缓存的命中通常采用分布式的算法 一.余数Hash 简单的路由算法可以使用余数Hash: ...
- 追踪分布式Memcached默认的一致性hash算法
<span style="font-family: Arial, Helvetica, sans-serif; background-color: rgb(255, 255, 255) ...
- 一致性Hash(Consistent Hashing)原理剖析
引入 在业务开发中,我们常把数据持久化到数据库中.如果需要读取这些数据,除了直接从数据库中读取外,为了减轻数据库的访问压力以及提高访问速度,我们更多地引入缓存来对数据进行存取.读取数据的过程一般为: ...
- 图解一致性hash算法和实现
更多内容,欢迎关注微信公众号:全菜工程师小辉.公众号回复关键词,领取免费学习资料. 一致性hash算法是什么? 一致性hash算法,是麻省理工学院1997年提出的一种算法,目前主要应用于分布式缓存当中 ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
随机推荐
- Linux下MySQL的操作(最全)
注意:这里以mariadb为例 启动mysql服务 systemctl start mariadb 登录mysql mysql -u root -p SQL语言分类 - 数据定义语言:简称[DDL]( ...
- Vue实战041:获取当前客户端IP地址详解(内网和外网)
前言 我们经常会有需求,希望能获取的到当前用户的IP地址,而IP又分为公网ip(也称外网)和私网IP(也称内网IP),IP地址是IP协议提供的一种统一的地址格式,每台设备都设定了一个唯一的IP地址”, ...
- java 通过runtime 调用python 不显示python运行内容的bug
先说下上面问题的原因,上面问题是因为python中用到了第三方的类库,你的电脑上没有那个类库,所以程序没有运行,在控制台也就看不到输出.只要导入那个类库就好... python 导入类库,可以单独下载 ...
- 为什么HashMap桶(链表)的长度超过8才会转换成红黑树
百度了一下,感觉能说清楚的并不多,所以在此记录一下. 首先说一说转换为红黑树的必要性:红黑树的插入.删除和遍历的最坏时间复杂度都是log(n),因此,意外的情况或者恶意使用下导致hashCode()方 ...
- RESTful入门
RESTful入门 1. REST简介 和RPC一样,都是目前比较主流的URL链接风格,也可以说是web服务的一种架构风格.REST全称Representational State Transfer, ...
- ML_Homework_Porject_1_KMeans
第一次机器学习的作业完成了,按照先前做实作的习惯来写一下总结和思考. 作业要求:对COIL20,Yale_32x32,data_batch_1(Cifar)三个数据集,分别运用KMeans对其中的图片 ...
- springmvc配置mybatis与hibernate的不同点
相信每个人对springmvc+hibernate或者springmvc+mybatis都不会陌生,拿来一个项目也都会开发.但是自己配置的情况下却很少,即使自己配置过,长时间不写也会忘,在这里记录一下 ...
- Flutter移动电商实战 --(46)详细页_自定义TabBar Widget
主要实现详情和评论的tab provide定义变量 自己做一个tab然后用provide去控制 定义两个变量来判断是左侧选中了还是右侧选中了.并定义一个方法来接受参数,修改是左侧还是右侧选中的状态值 ...
- error: cannot connect to daemon解决办法
本文链接:https://blog.csdn.net/ipinki1218/article/details/80704806运行adb shell时出现error: cannot connect to ...
- linux内核中IS_ALIGNED是如何定义的?
1. 定义如下: (include/linux/kernel.h) #define IS_ALIGNED(x, a) (((x) & ((typeof(x))(a ...