爬虫----异步---高性能爬虫----aiohttp 和asycio 的使用
前情提要:
首先膜拜loco大佬
肯定有人像我一样.不会异步,发一下.
一:性能比对
多进程,多线程,(这里不建议使用,太消耗性能)
进程池和线程池 (可以适当的使用)
单线程+异步协程 (推荐使用)
二:案例演示
1->1: 普通的啥也不用的
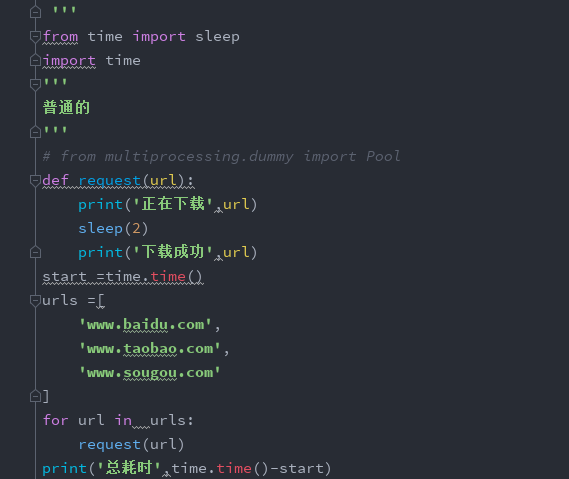
1->2:
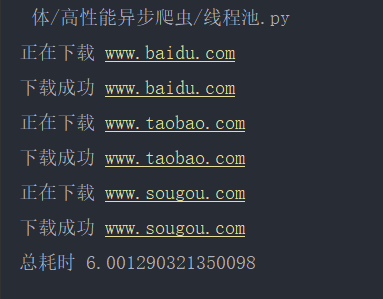
2->1:
使用线程池
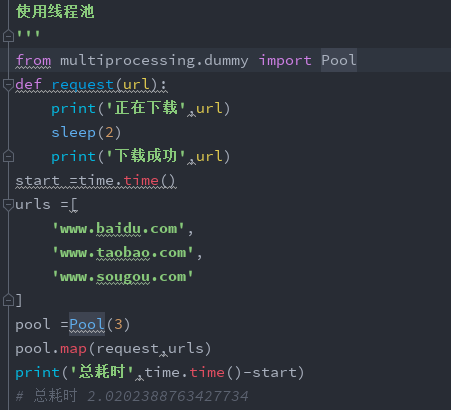
2->2:结果

三:异步协程
1: 协程的参数设定

2:协程的简单使用


3:task的使用
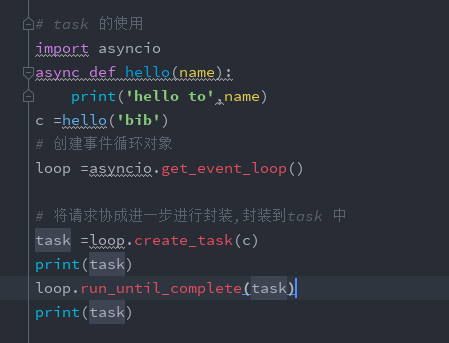

4:future 的使用
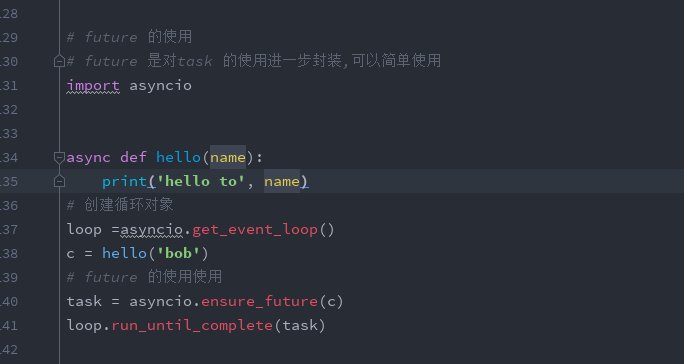
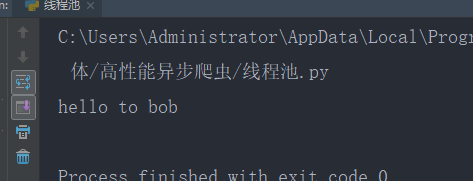
5:
回调函数的使用

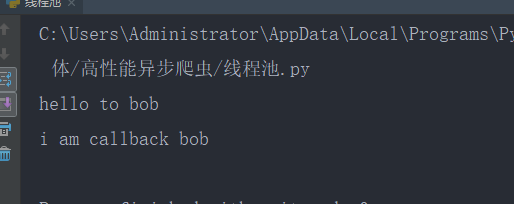
四:支持异步请求网络的模块: aiohttp
import aiohttp
import asyncio async def get_page(url):
async with aiohttp.ClientSession() as session: #with 前面都要加async
async with await session.get(url=url) as response: # 有io阻塞的都要加await
挂起
page_text = await response.text() #read() json()
print(page_text)
start = time.time()
urls = [
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom',
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom',
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom'
]
tasks = []
loop = asyncio.get_event_loop()
for url in urls:
c = get_page(url)
task = asyncio.ensure_future(c)
tasks.append(task)
loop.run_until_complete(asyncio.wait(tasks))
print('总耗时:',time.time()-start)
爬虫----异步---高性能爬虫----aiohttp 和asycio 的使用的更多相关文章
- 【Python爬虫】:使用高性能异步多进程爬虫获取豆瓣电影Top250
在本篇博文当中,将会教会大家如何使用高性能爬虫,快速爬取并解析页面当中的信息.一般情况下,如果我们请求网页的次数太多,每次都要发出一次请求,进行串行执行的话,那么请求将会占用我们大量的时间,这样得不偿 ...
- 八、asynicio模块以及爬虫应用asynicio模块(高性能爬虫)
asynicio模块以及爬虫应用asynicio模块(高性能爬虫) 一.背景知识 爬虫的本质就是一个socket客户端与服务端的通信过程,如果我们有多个url待爬取,只用一个线程且采用串行的方式执行, ...
- Python爬虫-01:爬虫的概念及分类
目录 # 1. 为什么要爬虫? 2. 什么是爬虫? 3. 爬虫如何抓取网页数据? # 4. Python爬虫的优势? 5. 学习路线 6. 爬虫的分类 6.1 通用爬虫: 6.2 聚焦爬虫: # 1. ...
- 放养的小爬虫--京东定向爬虫(AJAX获取价格数据)
放养的小爬虫--京东定向爬虫(AJAX获取价格数据) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wang/Sp ...
- crawler_爬虫_反爬虫策略
关于反爬虫和恶意攻击的一些策略和思路 有时网站经常受到恶意spider攻击,疯狂抓取网站内容,对网站性能有较大影响. 下面我说说一些反恶意spider和spam的策略和思路. 1. 通过日志分析来 ...
- Java 多线程爬虫及分布式爬虫架构探索
这是 Java 爬虫系列博文的第五篇,在上一篇 Java 爬虫服务器被屏蔽,不要慌,咱们换一台服务器 中,我们简单的聊反爬虫策略和反反爬虫方法,主要针对的是 IP 被封及其对应办法.前面几篇文章我们把 ...
- Java 多线程爬虫及分布式爬虫架构
这是 Java 爬虫系列博文的第五篇,在上一篇 Java 爬虫服务器被屏蔽,不要慌,咱们换一台服务器 中,我们简单的聊反爬虫策略和反反爬虫方法,主要针对的是 IP 被封及其对应办法.前面几篇文章我们把 ...
- 【Python网络爬虫一】爬虫原理和URL基本构成
1.爬虫定义 网络爬虫,即Web Spider,是一个很形象的名字.把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛.网络蜘蛛是通过网页的链接地址来寻找网页的.从网站某一个页面(通常 ...
- Python爬虫从入门到放弃(二十二)之 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
随机推荐
- git使用中的一些命令及心得
Git 与 SVN 区别点: 1.Git 是分布式的,SVN 不是:这是 Git 和其它非分布式的版本控制系统,例如 SVN,CVS 等,最核心 的区别. 2.Git 把内容按元数据方式存储,而 SV ...
- Nginx Too many open files
2019/07/25 08:31:31 [crit] 15929#15929: accept4() failed (24: Too many open files) 2019/07/25 08:31: ...
- Python考试_第三次
- python 全栈11期月考题 一 基础知识:(70分) 1.文件操作有哪些模式?请简述各模式的作用(2分) 2.详细说明tuple.list.dict的用法,以及它们的特点(3分) 3.解释生成 ...
- 三、eureka服务端获取服务列表
所有文章 https://www.cnblogs.com/lay2017/p/11908715.html 正文 eureka服务端维护了一个服务信息的列表,服务端节点之间相互复制服务信息.而作为eur ...
- JAVA中对象的克隆及深拷贝和浅拷贝
使用场景: 在日常的编程过程 中,经常会遇到,有一个对象OA,在某一时间点OA中已经包含了一些有效值 ,此时可能会需一个和OA完全相对的新对象OB,并且要在后面的操作中对OB的任何改动都不会影响到OA ...
- PowerBulider获取计算机mac地址
PowerBulider获取计算机mac地址 1.下载GETNET.DLL获取网络资源的API 2.PB的全局函数中的引入需要API,常用API列表如下 //得到计算机名字 function bool ...
- Computer Vision_33_SIFT:Evaluation of Interest Point Detectors——2000
此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面.对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献.有一些刚刚出版的 ...
- (14)占位符%和format
# 在介绍占位符之前,这里先介绍下索引,索引可以方便的帮我们拿到容器内的数据 # 索引可以简单的理解为一个有序的标记,我们把容器里的元素每一个都编上一个编号 # 凡是有序的容器类型数据,都可以通过索引 ...
- 用js刷剑指offer(替换空格)
题目描述 请实现一个函数,将一个字符串中的每个空格替换成“%20”.例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy. 牛客网链接 js代码 func ...
- Excel 教程二 单元格范围的使用
上一篇已经看了Excel这个软件的基本功能区,这一节我们来看一下我们经常使用的单元格范围. 一.首先我们看一下单元格,行和列 单元格指的是excel工作簿中的某一行某一列对应的具体位置,列指的是从上到 ...