爬虫----异步---高性能爬虫----aiohttp 和asycio 的使用
前情提要:
首先膜拜loco大佬
肯定有人像我一样.不会异步,发一下.
一:性能比对
多进程,多线程,(这里不建议使用,太消耗性能)
进程池和线程池 (可以适当的使用)
单线程+异步协程 (推荐使用)
二:案例演示
1->1: 普通的啥也不用的
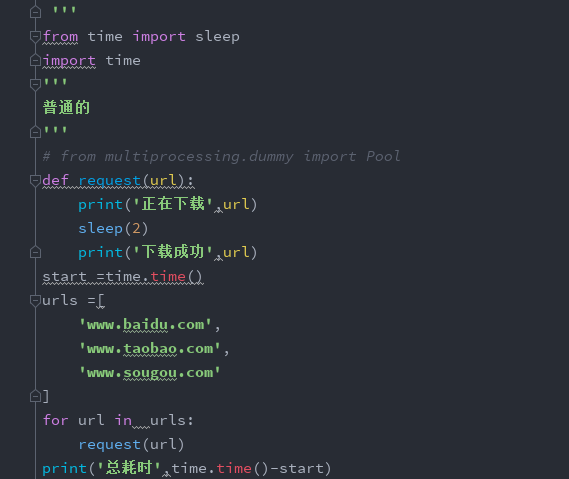
1->2:
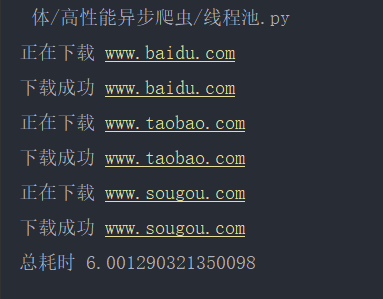
2->1:
使用线程池
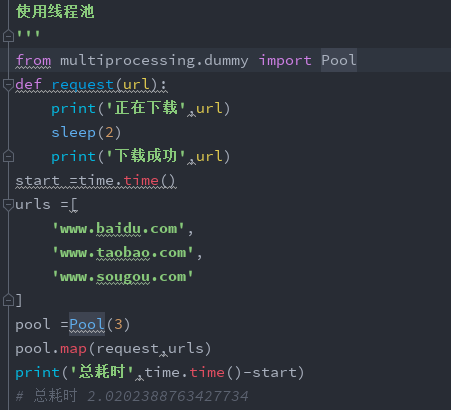
2->2:结果

三:异步协程
1: 协程的参数设定

2:协程的简单使用


3:task的使用
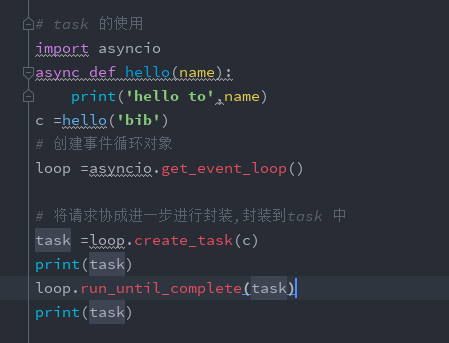

4:future 的使用
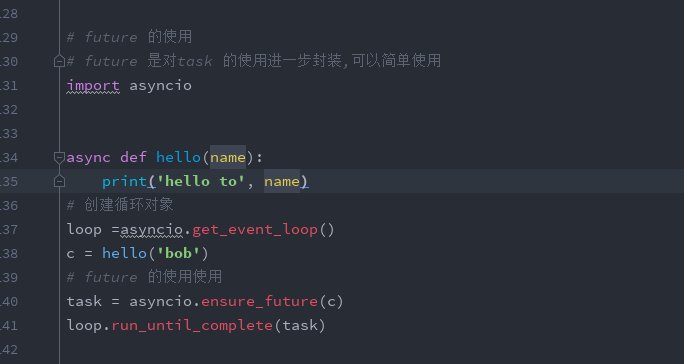
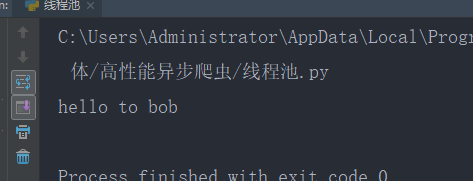
5:
回调函数的使用

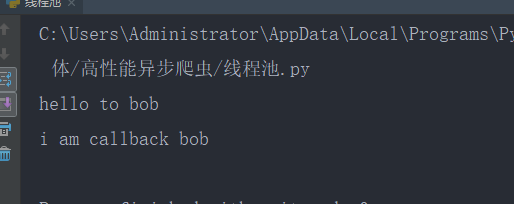
四:支持异步请求网络的模块: aiohttp
import aiohttp
import asyncio async def get_page(url):
async with aiohttp.ClientSession() as session: #with 前面都要加async
async with await session.get(url=url) as response: # 有io阻塞的都要加await
挂起
page_text = await response.text() #read() json()
print(page_text)
start = time.time()
urls = [
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom',
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom',
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom'
]
tasks = []
loop = asyncio.get_event_loop()
for url in urls:
c = get_page(url)
task = asyncio.ensure_future(c)
tasks.append(task)
loop.run_until_complete(asyncio.wait(tasks))
print('总耗时:',time.time()-start)
爬虫----异步---高性能爬虫----aiohttp 和asycio 的使用的更多相关文章
- 【Python爬虫】:使用高性能异步多进程爬虫获取豆瓣电影Top250
在本篇博文当中,将会教会大家如何使用高性能爬虫,快速爬取并解析页面当中的信息.一般情况下,如果我们请求网页的次数太多,每次都要发出一次请求,进行串行执行的话,那么请求将会占用我们大量的时间,这样得不偿 ...
- 八、asynicio模块以及爬虫应用asynicio模块(高性能爬虫)
asynicio模块以及爬虫应用asynicio模块(高性能爬虫) 一.背景知识 爬虫的本质就是一个socket客户端与服务端的通信过程,如果我们有多个url待爬取,只用一个线程且采用串行的方式执行, ...
- Python爬虫-01:爬虫的概念及分类
目录 # 1. 为什么要爬虫? 2. 什么是爬虫? 3. 爬虫如何抓取网页数据? # 4. Python爬虫的优势? 5. 学习路线 6. 爬虫的分类 6.1 通用爬虫: 6.2 聚焦爬虫: # 1. ...
- 放养的小爬虫--京东定向爬虫(AJAX获取价格数据)
放养的小爬虫--京东定向爬虫(AJAX获取价格数据) 笔者声明:只用于学习交流,不用于其他途径.源代码已上传github.githu地址:https://github.com/Erma-Wang/Sp ...
- crawler_爬虫_反爬虫策略
关于反爬虫和恶意攻击的一些策略和思路 有时网站经常受到恶意spider攻击,疯狂抓取网站内容,对网站性能有较大影响. 下面我说说一些反恶意spider和spam的策略和思路. 1. 通过日志分析来 ...
- Java 多线程爬虫及分布式爬虫架构探索
这是 Java 爬虫系列博文的第五篇,在上一篇 Java 爬虫服务器被屏蔽,不要慌,咱们换一台服务器 中,我们简单的聊反爬虫策略和反反爬虫方法,主要针对的是 IP 被封及其对应办法.前面几篇文章我们把 ...
- Java 多线程爬虫及分布式爬虫架构
这是 Java 爬虫系列博文的第五篇,在上一篇 Java 爬虫服务器被屏蔽,不要慌,咱们换一台服务器 中,我们简单的聊反爬虫策略和反反爬虫方法,主要针对的是 IP 被封及其对应办法.前面几篇文章我们把 ...
- 【Python网络爬虫一】爬虫原理和URL基本构成
1.爬虫定义 网络爬虫,即Web Spider,是一个很形象的名字.把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛.网络蜘蛛是通过网页的链接地址来寻找网页的.从网站某一个页面(通常 ...
- Python爬虫从入门到放弃(二十二)之 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
随机推荐
- php实现支付宝在线支付和扫码支付demo
### php实现支付宝在线支付和扫码支付demo 背景:在做一个公众号时增加了h5端,需要接入支付,非微信环境,选择了支付宝,以下简单记录下实现过程,并做了简单的封装,拿来即可使用,注意:本项目只是 ...
- Excel逻辑运算函数
Excel逻辑运算函数 1.FALSE和TRUE的使用 筛选出表中salary>6.gender为男.age>28至少满足这三个条件中的两个的数据 1.依次使用:=C2>6.=D ...
- css — 权重、继承性、排版、float
目录 1. 继承性 2. css中的权重 3. 常用格式化排版 4. 浮动布局float 1. 继承性 继承性:在css有某些属性是可以继承下来,如 color,text-xxx,line-heigh ...
- go 常量定义和使用
常量的定义与变量类似,只不过使用 const 关键字. 常量可以是字符.字符串.布尔或数字类型的值. 常量不能使用 := 语法定义. 常量必须定义时赋值,不能多次赋值 package main imp ...
- 关于typecho发布文章后的错位
今天发布了一篇文章,发布后发现,what?主页错位了,安装控制变量法知道,肯定是这篇文章有什么不可告人的秘密. 所以,顺便使用一下二分法查找一下为啥,最后找到是因为使用了---------->( ...
- SAS学习笔记40 SAS程序运行过程
当我们提交运行一个DATA步程序后,具体发生了什么事情. SAS程序与其他程序一样,在运行时都要经过两个阶段:编译(Compilation).执行(Execution) 程序首先经过编译阶段,该阶段主 ...
- c++博客转载
C++ 中文件流(fstream)的使用方法及示例 http://blog.jobbole.com/108649/ qt中文乱码问题: https://blog.csdn.net/brave_hear ...
- Spring框架ioc概括
什么是Spring且能做什么 Spring是一个开源框架,它由Rod Johnson创建.它是为了解决企业应用开发的复杂性而创建的. Spring使用基本的JavaBean来完成以前只可能由EJB完成 ...
- 国际化(i18n)学习
一 软件的国际化:软件开发时,要使它能同时应对世界不同地区和国家的访问,并针对不同地区和国家的访问,提供相应的.符合来访者阅读习惯的页面或数据. 国际化(internationalization)又称 ...
- 二、运行时JVM结构组成及作用
二.运行时JVM结构组成及作用 程序计数器 是否共享:否,线程私有,每个线程有1个独立的程序计数器! 所处位置:线程私有的内部区域 生命周期:与线程绑定 主要作用: 当前线程执行字节码的行号指示器! ...