效应量Effect Size
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频教程)


效应量可以表示两组样本平均数的差异

效应量可以用d表示,其公式

观察实验组和对照组,效应量越大,两组平均数越远,差异越大

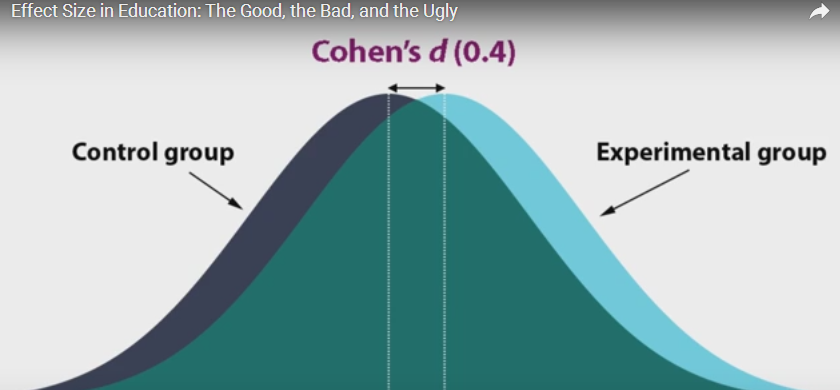


效应量不受样本容量的影响。当样本容量大得到显著时,有必要报告效应量大小。
效应量太小,意味着处理即使达到了显著水平,也缺乏实用价值。
在一般统计分析中,一般我们只报告统计量F或t值,与p-value;实际上这些统计量对数据的描述只是描述了一小部分;传统的描述还应包括样本量,样本均数与标准差;但这些传统的描述量基本只是对单变量分布的描述,而对两组变量或处理效应的描述,则用effectsize更加直观。它在平均数检验中表示的是两组样本分布的总体的非重叠程度;ES越大,重叠程度越小,效应明显;ES越小则相反。可以这样理解,不管你取哪种样本,ES是作为为一种标准的均数差异的估计,它与当前样本无关。显然,传统的推断统计量F及p-value只是说明均数差异,但这种差异脱离样本推广到不同的抽样群体,差异究竟有多大,需要用ES来描述。(可以这样来形容F值与ES值:F值表示的是样本1与样本2之间的显著性;而ES值是表示在样本1的总体与样本2的总体中随便抽取两个样本,这种差异显著性出现的可能性)。
不同检测中,效应量量化程度不同


效应量Effect Size的更多相关文章
- 如何计算假设检验的功效(power)和效应量(effect size)?
做完一个假设检验之后,如果结果具有统计显著性,那么还需要继续计算其效应量,如果结果不具有统计显著性,并且还需要继续进行决策的话,那么需要计算功效. 功效(power):正确拒绝原假设的概率,记作1-β ...
- 去他的效应(what-the-hell effect)与自我放纵
去他的 效应(what-the-hell effect)与自我放纵 为什么写这篇文章: 对于我来说,但我感到疲惫——"无意拿起"手机,对自己说"随便看看"——但 ...
- 查看数据库表的数据量和SIZE大小的脚本修正
在使用桦仔的分享一个SQLSERVER脚本(计算数据库中各个表的数据量和每行记录所占用空间)的脚本时,遇到下面一些错误 这个是因为这些表的Schema是Maint,而不是默认的dbo,造成下面这段SQ ...
- zookeeper分布式锁避免羊群效应(Herd Effect)
本文(转自:http://jm-blog.aliapp.com/?p=2554)主要讲述在使用ZooKeeper进行分布式锁的实现过程中,如何有效的避免“羊群效应( herd effect)”的出现. ...
- 如何确定假设检验的样本量(sample size)?
在<如何计算假设检验的功效(power)和效应量(effect size)?>一文中,我们讲述了如何根据显著性水平α,效应量和样本容量n,计算功效,以及如何根据显著性水平α,功效和样本容量 ...
- 数据分析 - 斯特鲁普效应(Stroop effect)
数据分析 - 斯特鲁普效应(Stroop effect) Reinhard得到了一份斯特鲁普效应试验的数据,我们来分析下,文字的颜色,是否会影响受试者的反应. 这里先看看什么是斯特鲁普效应: 斯特鲁普 ...
- 主效应|处理误差 |组间误差|处理效应|随机误差|组内误差|误差|效应分析|方差齐性检验|SSE|SSA|SST|MSE|MSA|F检验|关系系数|完全随机化设计|区组设计|析因分析
8 什么是只考虑主效应的方差分析? 就是不考虑交互效应的方差分析,即认为因素之间是不相互影响的,就是无重复的方差分析. 什么是处理误差 (treatment error).组间误差(between ...
- R笔记 单样本t检验 功效分析
R data analysis examples 功效分析 power analysis for one-sample t-test单样本t检验 例1.一批电灯泡,标准寿命850小时,标准偏差50,4 ...
- ZooKeeper使用原理
ZooKeeper的基本原理 ZNode的基本概念 ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode.每个ZNode都可以通过其路径唯一标识 ...
随机推荐
- testng系列-ReportNG
生成reportng报告操作步骤: 一.maven的pom.xml文件需要添加内容: <properties> <!-- maven 参数配置,这里引用不同的testng.xml - ...
- 点滴拾遗 - 自定义 Format 控制 String.Format 行为
点击下载示例代码 String.Format 一重载方法的签名如下 public static string Format( IFormatProvider provider, string form ...
- “Hello World!”团队召开的第六次会议
团队“Hello World!”团队召开的第六次会议. 博客内容: 一.会议时间 二.会议地点 三.会议成员 四.会议内容 五.Todo List 六.会议照片 七.燃尽图 一.会议时间 2017年1 ...
- Java中的静态变量static
package com.wangcf; public class Test { String name="你好"; static String sex="男"; ...
- request.quest/query_string/params/body等方法介绍
假设url:http://192.168.1.111:8080/api/cluster/group?wzd=111&abc=cc 方法类型:POST,body是{"name" ...
- 18软工实践-第八次作业(课堂实战)-项目UML设计(团队)
目录 团队信息 分工选择 课上分工 课下分工 ToDolist alpha版本要做的事情 燃尽图 UML 用例图 状态图 活动图 类图 部署图 实例图 对象图 时序图 包图 通信图 贡献分评定 课上贡 ...
- 第四周作业——C语言自评
1.你对自己的未来有什么规划?做了哪些准备?以目前的现状来说,希望至少能够掌握专业所要求的基本操作,然后一步步去深入.提升,毕业之后不会灰溜溜的一次次求职失败.目前更多的是利用闲暇时间补回过去老师同学 ...
- BundleCollection学习(一)
工作中有同事提到了mvc4提供了css,js压缩功能.类BundleCollection所以搜集资料记录学习下. 学习中………… MVC中用 BundleCollection 压缩CSS时图片路径问题 ...
- Alpha 冲刺9
队名:日不落战队 安琪(队长) 今天完成的任务 协助开发手写涂鸦demo. okhttp学习第三弹. 明天的计划 协助开发语音存储demo. 还剩下的任务 个人信息数据get. 遇到的困难 困难:整理 ...
- 基于 IBM WAS ND v6.1 搭建稳定高效的集群环境
如今的电子商务及电子政务应用系统的发展已经到了一个新的阶段,应用系统的成熟度和可用性都达到了更高的水准.因此庞大的部署规模和海量的用户访问成为目前大型电子商务及电子政务应用系统的显著特征.在这样的情况 ...