大数据系列之分布式数据库HBase-1.2.4+Zookeeper 安装及增删改查实践
之前介绍过关于HBase 0.9.8版本的部署及使用,本篇介绍下最新版本HBase1.2.4的部署及使用,有部分区别,详见如下:
1. 环境准备:
1.需要在Hadoop[hadoop-2.7.3] 启动正常情况下安装,hadoop安装可参考LZ的文章 大数据系列之Hadoop分布式集群部署
2. 资料包 zookeeper-3.4.9.tar.gz,hbase-1.2.4-bin.tar.gz
2. 安装步骤:
1.安装zookeeper
1.解压zookeeper-3.4.9.tar.gz
cd
tar -xzvf zookeeper-3.4.9.tar.gz
ll zookeeper-3.4.9

2.新建配置conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/mfz/zookeeper-3.4.9/zookeeperData
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
autopurge.purgeInterval=1
3.启动zk
jps
bin/zkServer.sh start


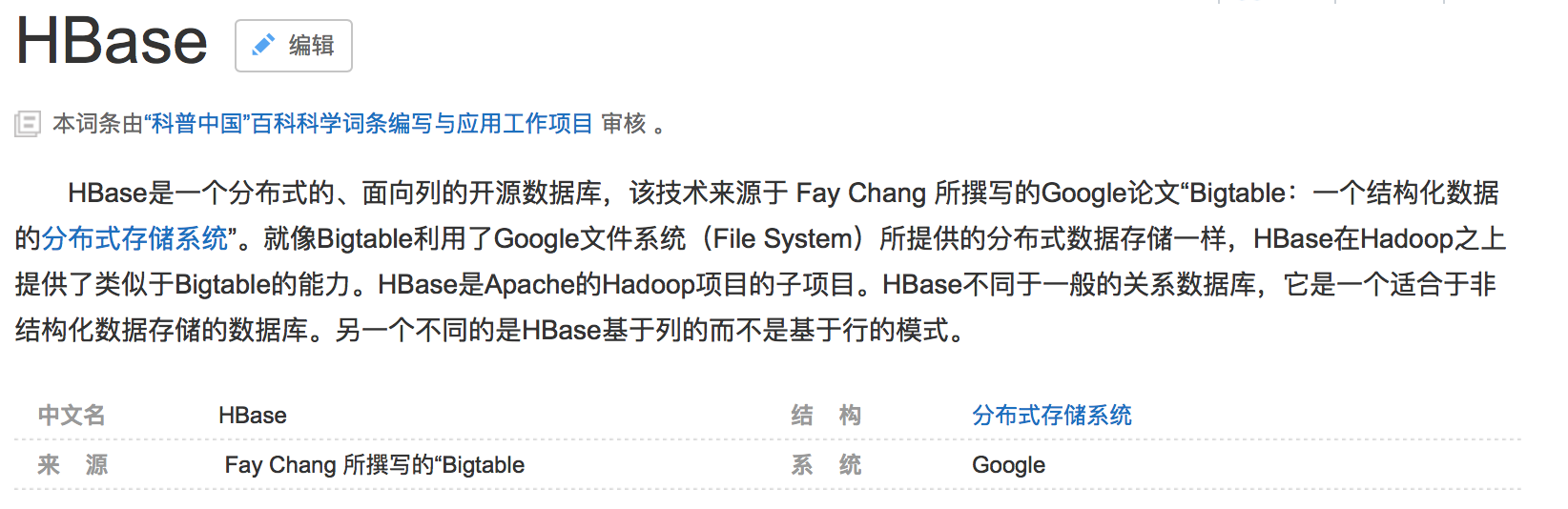
4. 查看zk端口2181状态
echo stat | nc master 2181
2.安装HBase-1.2.4
1.将hbase 压缩包放入用户~/resources下
2.执行命令,cp到用户根目录,解压
cp resources/hbase-1.2.4-bin.tar.gz . tar -xzvf hbase-1.2.4-bin.tar.gz ll hbase-1.2.4

3.配置 conf/hbase-env.sh
... # The java implementation to use. Java 1.7+ required.
# export JAVA_HOME=/usr/java/jdk1.6.0/
export JAVA_HOME=/usr/java/jdk1.8.0_102/
# Extra Java runtime options.
# Below are what we set by default. May only work with SUN JVM.
# For more on why as well as other possible settings,
# see http://wiki.apache.org/hadoop/PerformanceTuning
export HBASE_OPTS="-XX:+UseConcMarkSweepGC"
# Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m" # Tell HBase whether it should manage it's own instance of Zookeeper or not.
export HBASE_MANAGES_ZK=false ...
4.配置 conf/hbase-site.xml
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master</value>
</property>
</configuration>
5.配置 conf/regionservers ,将内容替换为slave (集群从节点主机hostname)
6.配置环境变量,可在.base_profile , 也可在root 用户下配置/etc/profile 。 注意要生效配置 source {filename}
#HBase CONFIG
export HBASE_HOME=/home/mfz/hbase-1.2.4
export PATH=$HBASE_HOME/bin:$PATH
export HADOOP_CLASSPATH=$HBASE_HOME/lib/*
7.将配置完成后的Hbase安装包传输到slave集群节点上
cd
scp -r hbase-1.2.4 slave:~/
8. 启动Hbase ,进入安装目录下:
bin/start-hbase.sh

9.验证Hbase,进入master 浏览器.此步骤与0.9.8版本不同的是端口还由60010改为16010,启动界面如下则启动成功


10.进入HBase shell执行增、删、改、查操作(与Hbase 0.9.8 Shell命令一致)不做其他说明
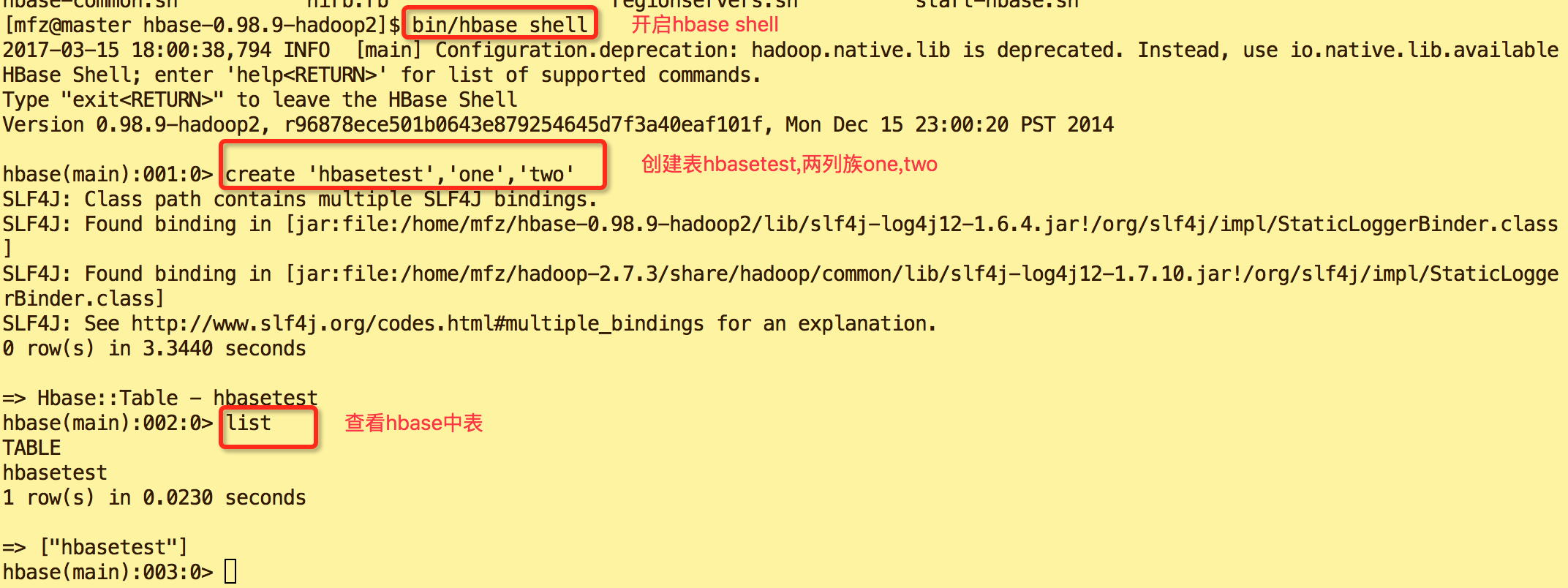
#shell 命令如下 #开启Hbase shell
bin/hbase shell #创建表 hbasename, 有两个列族 'one'和'two'
create 'hbasename','one','two' #查看表
list #查看表结构
describe 'hbasetest' #插入数据
put 'hbasename','test1','one','helloWorld',1 #查看数据
scan 'hbasename'
get 'hbasename','test1' #修改表结构(新增列族'three')
alter 'hbasename',NAME='three' #删除表
disable 'hbasename'
drop 'hbasename'





更多hbase shell命令详见官网 http://hbase.apache.org/book.html#shell_exercises
3.HBase-demo

1.BaseConfig.Java
package hbase.base; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory; /**
* @author mengfanzhu
* @Package hbase.base
* @Description:
* @date 17/3/16 10:59
*/
public class BaseConfig { /**
* 创建hbase连接
* @return
*/
public static Connection getConnection() throws Exception{
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("hbase.zookeeper.quorum", "10.211.55.5");
conf.set("hbase.master", "10.211.55.5:9000");
Connection conn = ConnectionFactory.createConnection(conf);
return conn;
}
}
2.BaseDao.java
package hbase.base; import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.*; /**
* @author mengfanzhu
* @Package base
* @Description:
* @date 17/3/16 10:58
*/
public interface BaseDao { /**
* 创建表
* @param tableDescriptor
*/
public void createTable(HTableDescriptor tableDescriptor) throws Exception; /**
* 新增数据
* @param putData
* @param tableName
*/
public void putData(Put putData,String tableName) throws Exception; /**
* 删除数据
* @param delData
* @param tableName
*/
public void delData(Delete delData,String tableName) throws Exception; /**
* 查询数据
* @param scan
* @param tableName
* @return
*/
public ResultScanner scanData(Scan scan,String tableName) throws Exception; /**
* 查询数据
* @param get
* @param tableName
* @return
*/
public Result getData(Get get,String tableName) throws Exception;
}
3.BaseDaoImpl.java
package hbase.base; import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; /**
* @author mengfanzhu
* @Package hbase.base
* @Description: base服务实现
* @date 17/3/16 11:11
*/
public class BaseDaoImpl implements BaseDao {
static Logger logger = LoggerFactory.getLogger(BaseDaoImpl.class); /**
* 创建表
* @param tableDescriptor
*/
public void createTable(HTableDescriptor tableDescriptor) throws Exception{
Admin admin = BaseConfig.getConnection().getAdmin();
//判断tablename是否存在
if (!admin.tableExists(tableDescriptor.getTableName())) {
admin.createTable(tableDescriptor);
}
admin.close();
}
public void addTableColumn(String tableName,HColumnDescriptor columnDescriptor) throws Exception {
Admin admin = BaseConfig.getConnection().getAdmin();
admin.addColumn(TableName.valueOf(tableName),columnDescriptor);
admin.close();
} /**
* 新增数据
* @param putData
* @param tableName
*/
public void putData(Put putData,String tableName) throws Exception{
Table table = BaseConfig.getConnection().getTable(TableName.valueOf(tableName));
table.put(putData);
table.close();
} /**
* 删除数据
* @param delData
* @param tableName
*/
public void delData(Delete delData,String tableName) throws Exception{
Table table = BaseConfig.getConnection().getTable(TableName.valueOf(tableName));
table.delete(delData);
table.close();
} /**
* 查询数据
* @param scan
* @param tableName
* @return
*/
public ResultScanner scanData(Scan scan,String tableName) throws Exception{
Table table = BaseConfig.getConnection().getTable(TableName.valueOf(tableName));
ResultScanner rs = table.getScanner(scan);
table.close();
return rs;
} /**
* 查询数据
* @param get
* @param tableName
* @return
*/
public Result getData(Get get,String tableName) throws Exception{
Table table = BaseConfig.getConnection().getTable(TableName.valueOf(tableName));
Result result = table.get(get);
table.close();
return result;
}
}
4.StudentsServiceImpl.java
package hbase.students; import hbase.base.BaseDao;
import hbase.base.BaseDaoImpl;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes; import java.util.HashMap;
import java.util.Map; /**
* @author mengfanzhu
* @Package hbase.students
* @Description: students服务
* @date 17/3/16 11:36
*/
public class StudentsServiceImpl {
private BaseDao baseDao = new BaseDaoImpl();
private static final String TABLE_NAME = "t_students";
private static final String STU_ROW_NAME = "stu_row1";
private static final byte[] FAMILY_NAME_1 = Bytes.toBytes("name");
private static final byte[] FAMILY_NAME_2 = Bytes.toBytes("age");
private static final byte[] FAMILY_NAME_3 = Bytes.toBytes("scores"); public void createStuTable() throws Exception{
//创建tablename,列族1,2
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf(TABLE_NAME));
HColumnDescriptor columnDescriptor_1 = new HColumnDescriptor(FAMILY_NAME_1);
HColumnDescriptor columnDescriptor_2 = new HColumnDescriptor(FAMILY_NAME_2);
HColumnDescriptor columnDescriptor_3 = new HColumnDescriptor(FAMILY_NAME_3);
tableDescriptor.addFamily(columnDescriptor_1);
tableDescriptor.addFamily(columnDescriptor_2);
tableDescriptor.addFamily(columnDescriptor_3);
baseDao.createTable(tableDescriptor);
} /**
* 插入数据<列族名称,值>
* @param bytes
*/
public void putStuData(Map<byte[],byte[]> bytes) throws Exception{
Put put = new Put(Bytes.toBytes(STU_ROW_NAME));;
int i = 1;
for(byte[] familyNames : bytes.keySet()){
put.addColumn(familyNames, bytes.get(familyNames), Bytes.toBytes(0));
i++;
} baseDao.putData(put, TABLE_NAME);
} public ResultScanner scanData(Map<byte[],byte[]> bytes) throws Exception{
Scan scan = new Scan();
for(byte[] familyNames : bytes.keySet()){
scan.addColumn(familyNames, bytes.get(familyNames));
}
scan.setCaching(100);
ResultScanner results = baseDao.scanData(scan,TABLE_NAME); return results;
}
public void delStuData(String rowId,byte[] familyName,byte[] qualifierName) throws Exception{
Delete delete = new Delete(Bytes.toBytes(rowId));
delete.addColumn(familyName, qualifierName);
baseDao.delData(delete,TABLE_NAME);
} public static void main(String[] args) throws Exception {
StudentsServiceImpl ssi = new StudentsServiceImpl();
//创建table
ssi.createStuTable();
//添加数据
Map<byte[],byte[]> bytes = new HashMap<byte[],byte[]>();
bytes.put(FAMILY_NAME_1,Bytes.toBytes("Jack"));
bytes.put(FAMILY_NAME_2,Bytes.toBytes("10"));
bytes.put(FAMILY_NAME_3,Bytes.toBytes("O:90,T:89,S:100"));
ssi.putStuData(bytes); //查看数据
Map<byte[],byte[]> byteScans = new HashMap<byte[], byte[]>();
ResultScanner results = ssi.scanData(byteScans);
for (Result result : results) {
while (result.advance()) {
System.out.println(result.current());
}
}
}
}
5.pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>mfz.hbase</groupId>
<artifactId>hbase-demo</artifactId>
<version>1.0-SNAPSHOT</version> <repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.9</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.yammer.metrics/metrics-core -->
<dependency>
<groupId>com.yammer.metrics</groupId>
<artifactId>metrics-core</artifactId>
<version>2.2.0</version>
</dependency> </dependencies> <build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.3</version>
<configuration>
<classifier>dist</classifier>
<appendAssemblyId>true</appendAssemblyId>
<descriptorRefs>
<descriptor>jar-with-dependencies</descriptor>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build> </project>
6.执行结果



demo已上传至GitHub https://github.com/fzmeng/HBaseDemo
完~~
大数据系列之分布式数据库HBase-1.2.4+Zookeeper 安装及增删改查实践的更多相关文章
- 大数据系列之分布式数据库HBase-0.9.8安装及增删改查实践
若查看HBase-1.2.4版本内容及demo代码详见 大数据系列之分布式数据库HBase-1.2.4+Zookeeper 安装及增删改查实践 1. 环境准备: 1.需要在Hadoop启动正常情况下安 ...
- GZFramwork数据库层《四》单据主从表增删改查
同GZFramwork数据库层<三>普通主从表增删改查 不同之处在于:实例 修改为: 直接上效果: 本系列项目源码下载地址:https://github.com/GarsonZhang/G ...
- GZFramwork数据库层《三》普通主从表增删改查
运行结果: 使用代码生成器(GZCodeGenerate)生成tb_Cusomer和tb_CusomerDetail的Model 生成器源代码下载地址: https://github.com/Gars ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- “造轮运动”之 ORM框架系列(一)~谈谈我在实际业务中的增删改查
想想毕业已经快一年了,也就是大约两年以前,怀着满腔的热血正式跨入程序员的世界,那时候的自己想象着所热爱的技术生涯会是多么的丰富多彩,每天可以与大佬们坐在一起讨论解决各种牛逼的技术问题,喝着咖啡,翘着二 ...
- 大数据系列之分布式大数据查询引擎Presto
关于presto部署及详细介绍请参考官方链接 http://prestodb-china.com PRESTO是什么? Presto是一个开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持G ...
- Python大数据系列-01-关系数据库基本运算
关系数据库基本运算 .tg {border-collapse:collapse;border-spacing:0;} .tg td{font-family:Arial, sans-serif;font ...
- 2.大约QT数据库操作,简单的数据库连接操作,增删改查数据库,QSqlTableModel和QTableView,事务性操作,大约QItemDelegate 代理
Linux下的qt安装,命令时:sudoapt-get install qt-sdk 安装mysql数据库,安装方法參考博客:http://blog.csdn.net/tototuzuoquan ...
- hbase使用MapReduce操作1(基本增删改查)
操作代码 import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.*; import org.apach ...
随机推荐
- bzoj2820-GCD
题意 \(T\le 10^4\) 次询问 \(n,m\) ,求 \[ \sum _{i=1}^n\sum _{j=1}^m[gcd(i,j)\text { is prime}] \] 分析 这题还是很 ...
- Python常忘的进阶知识(上)
0.目录 1.面向对象 1.1 函数与方法 1.2 类变量与实例变量 1.3 实例方法.类方法.静态方法 1.4 公开和私有:没有什么是不能访问的 1.5 继承 2.正则表达式 2.1 Python内 ...
- YOLO v1之总结篇(linux+windows)
YOLO出自2016 CVPR You Only Look Once:Unified, Real-Time Object Detection,也是一个非常值得学习的框架,不得不说facebook的技术 ...
- 【BZOJ3566】概率充电器(动态规划)
[BZOJ3566]概率充电器(动态规划) 题面 BZOJ Description 著名的电子产品品牌 SHOI 刚刚发布了引领世界潮流的下一代电子产品--概率充电器: "采用全新纳米级加工 ...
- 自动化测试常用断言的使用方法(python)
自动化测试中寻找元素并进行操作,如果在元素好找的情况下,相信大家都可以较熟练地编写用例脚本了,但光进行操作可能还不够,有时候也需要对预期结果进行判断. 这里介绍几个常用断言的使用方法,可以一定程度上帮 ...
- Communications link failure;;The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
Caused by: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure::The ...
- 【bzoj1502】月下柠檬树
Portal -->bzoj1502 Solution 额其实说实在这题我一开始卡在了..这个阴影长啥样上QwQ 首先因为是平行光线然后投影到了一个水平面上所以这个投影一定是..若干个圆再加上这 ...
- 【bzoj3173】最长上升子序列
Portal --> bzoj3173 Solution 感觉自己需要智力康复qwq 首先题目给的这个序列肯定是一个\(1-n\)的排列,并且插入的顺序是从小到大 仔细思考一下会发现如果知道了最 ...
- Redis基操
Redis key-value类型的缓存数据库 指定IP和端口连接redis: ./redis-cli -h ip -p port Redis基本操作命令 命令 返回值 简介 ping PONG 测试 ...
- 机器学习算法的Python实现 (1):logistics回归 与 线性判别分析(LDA)
先收藏............ 本文为笔者在学习周志华老师的机器学习教材后,写的课后习题的的编程题.之前放在答案的博文中,现在重新进行整理,将需要实现代码的部分单独拿出来,慢慢积累.希望能写一个机器学 ...